@(跃迁之路)专栏
叨叨两句
- 技术的精进不能只是简单的刷题,而应该是不断的“刻意”练习
- 该系列改版后正式纳入【跃迁之路】专栏,持续更新
刻意练习——MySQL
2018.04.02
题目描述
DROP TABLE IF EXISTS test1;
CREATE TABLE test1 (id int(11) NOT NULL AUTO_INCREMENT,username varchar(20) NOT NULL,course varchar(20) NOT NULL,score bigint(20) NOT NULL,
PRIMARY KEY (id)
) ENGINE=InnoDB AUTO_INCREMENT=10 DEFAULT CHARSET=utf8;
INSERT INTO test1 VALUES ('1', '张三', '数学', '34');
INSERT INTO test1 VALUES ('2', '张三', '语文', '44');
INSERT INTO test1 VALUES ('3', '张三', '英语', '54');
INSERT INTO test1 VALUES ('4', '李四', '数学', '134');
INSERT INTO test1 VALUES ('5', '李四', '语文', '144');
INSERT INTO test1 VALUES ('6', '李四', '英语', '154');
INSERT INTO test1 VALUES ('7', '王五', '数学', '234');
INSERT INTO test1 VALUES ('8', '王五', '语文', '244');
INSERT INTO test1 VALUES ('9', '王五', '英语', '254');
查出以下结果
法1
SELECT
A.username,A.score as '数学',B.score as '语文',C.score as '英语'
FROM
(select username,course,score from test1 where course = '数学') A,
(select username,course,score from test1 where course = '语文') B,
(select username,course,score from test1 where course = '英语') C
WHERE
A.username = B.username
and B.username = C.username法2【推荐】
select
username,sum(case course when '数学' then score else 0 end ) as '数学',
sum(case course when '语文' then score else 0 end ) as '语文',
sum(case course when '英语' then score else 0 end ) as '英语'
FROM
test1
group by username2018.04.03
题目描述
在audit表上创建外键约束,其emp_no对应employees_test表的主键id。
CREATE TABLE employees_test(
ID INT PRIMARY KEY NOT NULL,
NAME TEXT NOT NULL,
AGE INT NOT NULL,
ADDRESS CHAR(50),
SALARY REAL
);
CREATE TABLE audit(
EMP_no INT NOT NULL,
create_date datetime NOT NULL
);
DROP TABLE audit;
CREATE TABLE audit(
EMP_no INT NOT NULL,
create_date datetime NOT NULL,
FOREIGN KEY(EMP_no) REFERENCES employees_test(ID)
);2018.04.04

由于视图 emp_v 的记录是从 employees 中导出的,所以要判断两者中相等的数据,只需要判断emp_no相等即可。
方法一:用 WHERE 选取二者 emp_no 相等的记录
SELECT em.* FROM employees AS em, emp_v AS ev WHERE em.emp_no = ev.emp_no
方法二:用 INTERSECT 关键字求 employees 和 emp_v 的交集
可参考:http://www.sqlite.org/lang_select.html
SELECT * FROM employees INTERSECT SELECT * FROM emp_v
方法三:仔细一想,emp_v的全部记录均由 employees 导出,因此可以投机取巧,直接输出 emp_v 所有记录
SELECT * FROM emp_v
【错误方法:】用以下方法直接输出 *,会得到两张表中符合条件的重复记录,因此不合题意,必须在 * 前加表名作限定
SELECT * FROM employees, emp_v WHERE employees.emp_no = emp_v.emp_no2018.04.05
题目描述
将所有获取奖金的员工当前的薪水增加10%。
create table emp_bonus(
emp_no int not null,
recevied datetime not null,
btype smallint not null);
CREATE TABLE salaries (emp_no int(11) NOT NULL,salary int(11) NOT NULL,from_date date NOT NULL,to_date date NOT NULL, PRIMARY KEY (emp_no,from_date));
UPDATE salaries SET salary = salary * 1.1 WHERE emp_no IN
(SELECT s.emp_no FROM salaries AS s INNER JOIN emp_bonus AS eb
ON s.emp_no = eb.emp_no AND s.to_date = '9999-01-01')2018.04.06
题目描述
针对库中的所有表生成select count(*)对应的SQL语句
CREATE TABLE employees (emp_no int(11) NOT NULL,birth_date date NOT NULL,first_name varchar(14) NOT NULL,last_name varchar(16) NOT NULL,gender char(1) NOT NULL,hire_date date NOT NULL,
PRIMARY KEY (emp_no));
create table emp_bonus(
emp_no int not null,
recevied datetime not null,
btype smallint not null);
CREATE TABLE dept_emp (emp_no int(11) NOT NULL,dept_no char(4) NOT NULL,from_date date NOT NULL,to_date date NOT NULL,
PRIMARY KEY (emp_no,dept_no));
CREATE TABLE dept_manager (dept_no char(4) NOT NULL,emp_no int(11) NOT NULL,from_date date NOT NULL,to_date date NOT NULL,
PRIMARY KEY (emp_no,dept_no));
CREATE TABLE salaries (emp_no int(11) NOT NULL,salary int(11) NOT NULL,from_date date NOT NULL,to_date date NOT NULL,
PRIMARY KEY (emp_no,from_date));
输出格式:
cnts
select count(*) from employees;
select count(*) from departments;
select count(*) from dept_emp;
select count(*) from dept_manager;
select count(*) from salaries;
select count(*) from titles;
select count(*) from emp_bonus;
本题主要有以下两个关键点:
1、在 SQLite 系统表 sqlite_master 中可以获得所有表的索引,其中字段 name 是所有表的名字,而且对于自己创建的表而言,字段 type 永远是 'table',详情可参考:
http://blog.csdn.net/xingfeng0501/article/details/7804378
2、在 SQLite 中用 “||” 符号连接字符串
SELECT "select count(*) from " || name || ";" AS cnts
FROM sqlite_master WHERE type = 'table'
3.mysql使用concat进行字符串拼接2018.04.07
题目描述
获取Employees中的first_name,查询按照first_name最后两个字母,按照升序进行排列
CREATE TABLE employees (emp_no int(11) NOT NULL,birth_date date NOT NULL,first_name varchar(14) NOT NULL,last_name varchar(16) NOT NULL,gender char(1) NOT NULL,hire_date date NOT NULL,
PRIMARY KEY (emp_no));
输出格式:
first_name
Chirstian
Tzvetan
Bezalel
Duangkaew
Georgi
Kyoichi
Anneke
Sumant
Mary
Parto
Saniya
本题考查 substr(X,Y,Z) 或 substr(X,Y) 函数的使用。其中X是要截取的字符串。Y是字符串的起始位置(注意第一个字符的位置为1,而不为0),取值范围是±(1~length(X)),当Y等于length(X)时,则截取最后一个字符;当Y等于负整数-n时,则从倒数第n个字符处截取。Z是要截取字符串的长度,取值范围是正整数,若Z省略,则从Y处一直截取到字符串末尾;若Z大于剩下的字符串长度,也是截取到字符串末尾为止。
SELECT first_name FROM employees ORDER BY substr(first_name,length(first_name)-1)
SELECT first_name FROM employees ORDER BY substr(first_name,-2)
2018.04.08

本题要用到SQLite的聚合函数group_concat(X,Y),其中X是要连接的字段,Y是连接时用的符号,可省略,默认为逗号。此函数必须与 GROUP BY 配合使用。此题以 dept_no 作为分组,将每个分组中不同的emp_no用逗号连接起来(即可省略Y)。可参考:
http://www.sqlite.org/lang_aggfunc.html#groupconcat
http://blog.csdn.net/langzxz/article/details/16807859
SELECT dept_no, group_concat(emp_no) AS employees
FROM dept_emp GROUP BY dept_no2018.04.09
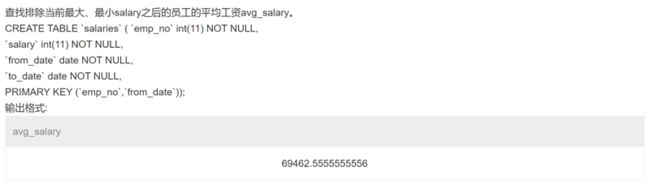
本题逻辑有问题,在挑选当前最大、最小salary时没加 to_date = '9999-01-01' 作条件限制,导致挑选出来的是全表最大、最小salary,然后对除去这两个salary再作条件限制 to_date = '9999-01-01' ,求平均薪水,此时求出的平均薪水与题目逻辑要求的不同。
SELECT AVG(salary) AS avg_salary FROM salaries
WHERE to_date = '9999-01-01'
AND salary NOT IN (SELECT MAX(salary) FROM salaries)
AND salary NOT IN (SELECT MIN(salary) FROM salaries)
正确的逻辑应如下所示,但在本题OJ系统中通不过:
SELECT AVG(salary) AS avg_salary FROM salaries
WHERE to_date = '9999-01-01'
AND salary NOT IN (SELECT MAX(salary) FROM salaries WHERE to_date = '9999-01-01')
AND salary NOT IN (SELECT MIN(salary) FROM salaries WHERE to_date = '9999-01-01')2018.04.10
题目描述
分页查询employees表,每5行一页,返回第2页的数据
CREATE TABLE employees (emp_no int(11) NOT NULL,birth_date date NOT NULL,first_name varchar(14) NOT NULL,last_name varchar(16) NOT NULL,gender char(1) NOT NULL,hire_date date NOT NULL,
PRIMARY KEY (emp_no));
select * from employees limit 5,52018.04.11
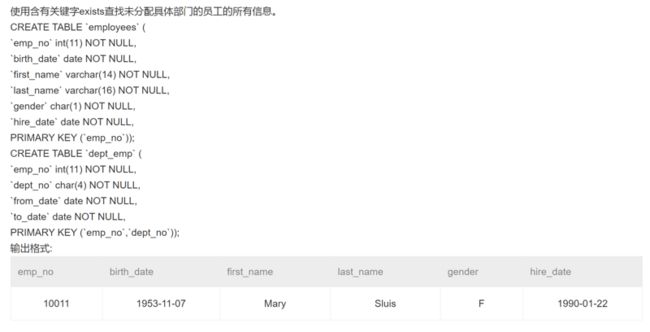
本题用 EXISTS 关键字的方法如下:意为在 employees 中挑选出令(SELECT emp_no FROM dept_emp WHERE emp_no = employees.emp_no)不成立的记录,即当 employees.emp_no=10011时。反之,把NOT去掉,则输出 employees.emp_no=10001~10010时的记录。
SELECT * FROM employees WHERE NOT EXISTS
(SELECT emp_no FROM dept_emp WHERE emp_no = employees.emp_no)2018.4.12
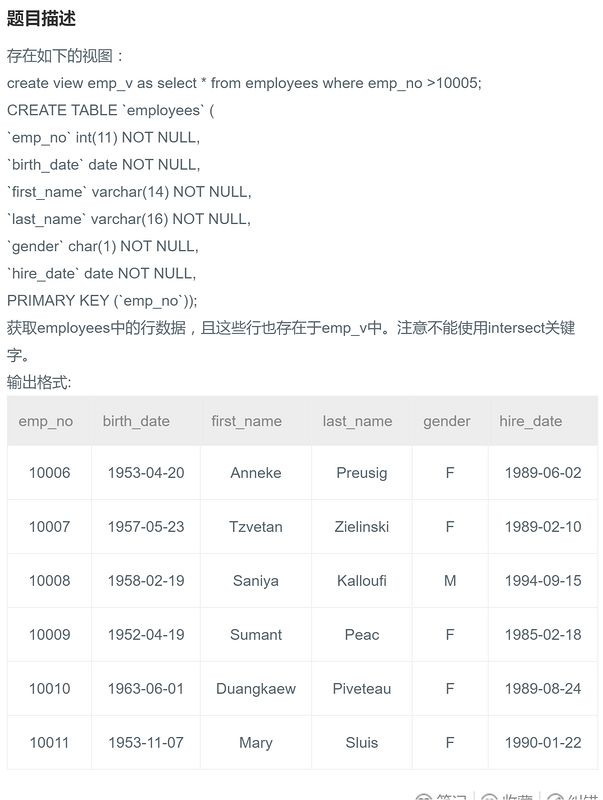
select ev.* from emp_v ev,employees e where ev.emp_no = e.emp_no
本题主要考查 SQLite 中 CASE 表达式的用法。即当 btype = 1 时,得到 salary * 0.1;当 btype = 2 时,得到 salary * 0.2;其他情况得到 salary * 0.3。详细用法请参考:
http://www.sqlite.org/lang_expr.html 中的【The CASE expression】
http://www.2cto.com/database/201202/120267.html 中的【条件表达式】
SELECT e.emp_no, e.first_name, e.last_name, b.btype, s.salary,
(CASE b.btype
WHEN 1 THEN s.salary * 0.1
WHEN 2 THEN s.salary * 0.2
ELSE s.salary * 0.3 END) AS bonus
FROM employees AS e INNER JOIN emp_bonus AS b ON e.emp_no = b.emp_no
INNER JOIN salaries AS s ON e.emp_no = s.emp_no AND s.to_date = '9999-01-01'
其实观察测试数据会发现 btype 只有1,2,3三种情况,即使不会 CASE 表达式,也能运用四则运算解出:(注意要除以10.0,如果除以10的话,结果的小数位会被舍去)
SELECT e.emp_no, e.first_name, e.last_name, b.btype, s.salary,
(s.salary * b.btype / 10.0) AS bonus
FROM employees AS e INNER JOIN emp_bonus AS b ON e.emp_no = b.emp_no
INNER JOIN salaries AS s ON e.emp_no = s.emp_no AND s.to_date = '9999-01-01'2018.4.13
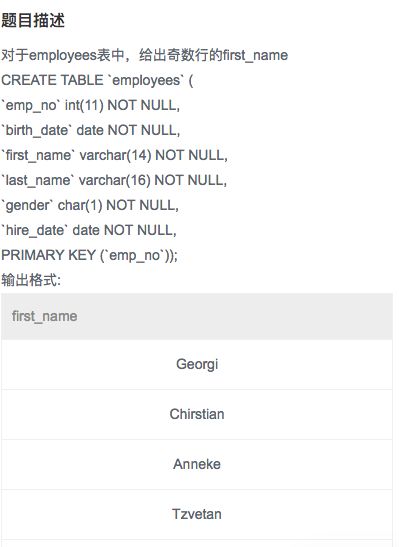
首先题目的叙述有问题,导致理解有误,输出的数据与参考答案不同。先给出正确的题目叙述:【对于employees表,在对first_name进行排名后,选出奇数排名对应的first_name】。
1、本题用到了三层 SELECT 查询,为了便于理解,采用缩进方式分层,且最外层对应e1,最内层对应e3;
2、在e3层中,采用 COUNT() 函数对 e2.first_name 进行排名标号,即在给定 e2.first_name的情况下,不大于 e2.first_name 的 e3.first_name 的个数有多少,该个数刚好与 e2.first_name 的排名标号匹配,且将该值命名为 rowid;
/*注意:排名标号后并未排序,即[Bob, Carter, Amy]的排名是[2,3,1],选取奇数排名后输出[Carter, Amy],所以可见参考答案中的first_name并未按字母大小排序*/
3、在e1层中,直接在限定条件 e1.rowid % 2 = 1 下,代表奇数行的 rowid,选取对应的 e1.first_name;
4、e2层则相当于连接e1层(选取表示层)与e3层(标号层)的桥梁。
SELECT e1.first_name FROM
(SELECT e2.first_name,
(SELECT COUNT(*) FROM employees AS e3
WHERE e3.first_name <= e2.first_name)
AS rowid FROM employees AS e2) AS e1
WHERE e1.rowid % 2 = 12018.4.14
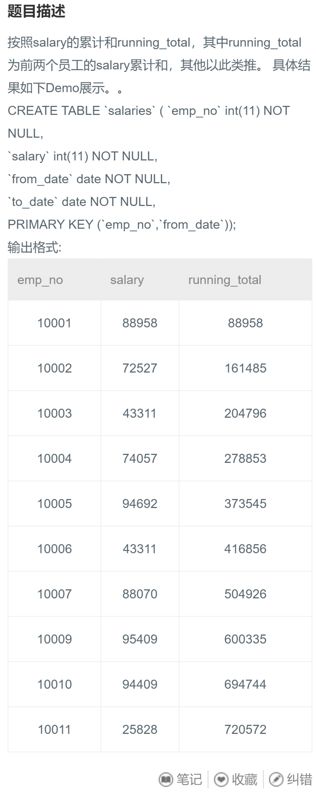
本题的思路为复用 salaries 表进行子查询,最后以 s1.emp_no 排序输出求和结果。
1、输出的第三个字段,是由一个 SELECT 子查询构成。将子查询内复用的 salaries 表记为 s2,主查询的 salaries 表记为 s1,当主查询的 s1.emp_no 确定时,对子查询中不大于 s1.emp_no 的 s2.emp_no 所对应的薪水求和
2、注意是对员工当前的薪水求和,所以在主查询和子查询内都要加限定条件 to_date = '9999-01-01'
SELECT s1.emp_no, s1.salary,
(SELECT SUM(s2.salary) FROM salaries AS s2
WHERE s2.emp_no <= s1.emp_no AND s2.to_date = '9999-01-01') AS running_total
FROM salaries AS s1 WHERE s1.to_date = '9999-01-01' ORDER BY s1.emp_no