【CSDN自动发评论】无情的发评论机器——爬虫小试验
前言
昨天在学AC自动机的时候,做到一道题,搜题解的时候,看到了一篇非常好的博客:
传送门
看完之后不禁觉得,写的真是太好了,再仔细一看,居然是我的学姐写的耶,于是就想在评论区给学姐捧捧场,发点什么好呢,发个“太强了”吧。
这个时候我正好开着抓包工具(怎么可能啊QAQ),然后就抓到了这样一个包

难道——这该不会——这莫非
怀着激动的心情我往上翻了翻

果然,这是一个post请求,也就是说,我的发评论的操作,竟然是由这个请求完成的!(假装震惊0.0)
既然如此,通过简单的操作模拟这个请求,是不是就可以自动发评论了呢,心里大概有了个谱,那就让我们来试一试吧。
冲
于是我在各种博客下面发了好多好多奇奇怪怪的评论,当然最后都删掉了啦!
通过我多次的实验发现,所有的评论竟然都是通过同一个URL发出去的!没错,就是上面的那个URL:
https://blog.csdn.net/phoenix/web/v1/comment/submit
于是我复制了这串URL,粘贴到我的导航栏里,然后按了一下回车,然后
ohhhhhhhhhhhhhh
ohhhhhhhhhhhhhhhhhh
屁都不会发生哦

其实应该是这样的
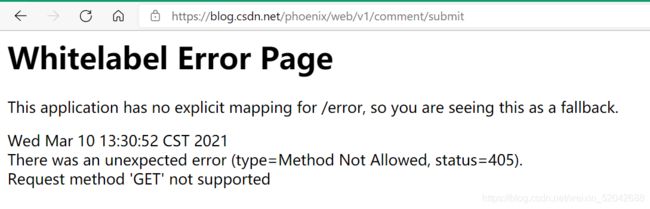
这是个什么意思呢
反正我是看不懂,没看到我抓包工具都是中文的吗?总之,我只看到了 ‘GET’ not supported 几个字,根据我这个小学生的英语水平来判断的话,大概意思就是,GET请求不被支持,吧。
所以这个URL本身就是为了发评论而存在的,只能接受POST请求
那么它是通过什么来判断评论的内容和哪篇博客的呢,诶,还记不记得我们第一次抓到的包

没错,就是这个,很明显,content里存的就是我们评论的内容嘛,那么下面那个神秘的代码是什么呢?
![]()
找到了吧,嘿嘿,其实就是用来定位博客的啦,可以理解为CSDN给每篇博客都定义了一个编号
那好吧,既然都这么清晰了,我们就打开pycharm(我管你用的是啥,哼),来模仿一下那个请求吧
嗯URL,嗯headers,嗯post请求,嗯
相信聪明的你一定很快就能写出代码来了
import requests
url = 'https://blog.csdn.net/phoenix/web/v1/comment/submit'
headers = {
'cookie' : '你不会真以为我会放自己的cookie在这里吧不会吧不会吧',
'referer': 'https://blog.csdn.net/qq_45599865/article/details/113048103?spm=1001.2014.3001.5501',
'user-agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.72 Safari/537.36 Edg/89.0.774.45'
}
data = {
'commentId' : '',
'content': '太强了',
'articleId': '113048103'
}
requests.post(url = url , headers = headers , data = data)
这样就可以了呢,虽然你复制去跑肯定是错的(注意cookie啊喂)
但是写完这个代码我难免觉得有些空虚,这个代码的作用,未免太太太太太小了吧,只是发一条评论,那不是有手就行,要这代码做什么呢
害,没办法,我就知道你们会这样想
给学姐所有的博客都发个“太强了”吧
如果这个程序,能给学姐所有的博客都发条评论,也学会比之前的代码好一些吧,如果修改一下URL,就能实现给任何一个人的所有博客发评论,那就再好不过了吧,嘿嘿,我懂你
那么我们来分析分析,要给一篇博客发评论,我们需要的其实只有博客的编号而已对吧
只要我们能够拿到学姐所有博客的编号,就可以实现给所有博客发评论了吧嘿嘿
那么我们先来浏览一下学姐主页的构成
给学姐点个关注也不是不可以哦
让我们打开抓包工具,用金手指随便点一篇博客康康吧
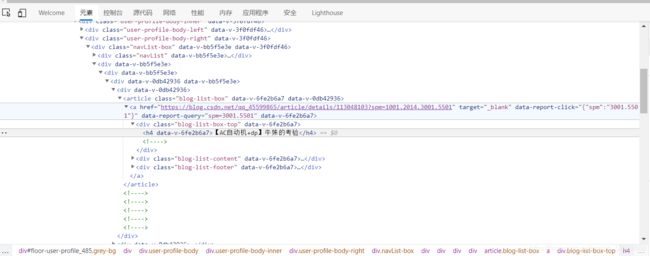
很显然,这篇博客的地址就存在那个href中对吧
那么我们看一下上面的目录,有没有成列表分布的目录呢,诶,还真有

这显然就是学姐博客的列表了
接下来怎么做不用我多说了吧,当然是查帕斯啦!(不是不说么)
url = 'https://blog.csdn.net/qq_45599865'
headers = {
'cookie' : '天真,我会把cookie放这儿吗',
'user-agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.72 Safari/537.36 Edg/89.0.774.45'
}
res = requests.get(url = url , headers = headers).text
#print(res)
tree = etree.HTML(res)
lst = tree.xpath('//*[@id="floor-user-profile_485"]/div/div[2]/div/div[2]/div/div[2]/div/div')
这样我们就拿到了这个列表,接下来循环每一个div,就把我们要的href取出来,然后截取到每篇博客的代号,接着一篇一篇地发评论就好了吧
注意我们发评论时的referer也是要改的哦
for i in lst :
href = i.xpath('//article[@class="blog-list-box"]/a/@href')
#print(href)
for hre in href:
#print(hre)
url1 = 'https://blog.csdn.net/phoenix/web/v1/comment/submit'
headers1 = {
'cookie': '都说了不会有cookie的啦,你还看,再看也没用',
'referer': '{0}?spm=1001.2014.3001.5501'.format(hre),
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'
}
hre = hre + "@"
ex = '/article/details/(.*?)@'
hr = re.findall(ex , hre)[0]
#print(hr)
data1 = {
'commentId' : '',
'content': '太强了',
'articleId': '{0}'.format(hr)
}
try:
requests.post(url=url1, headers=headers1, data=data1)
print("成功!")
except:
print("失败。。")
写完这个我信誓旦旦的跑了一遍
然而
然而它竟然
只发了三篇!!!!!
这是怎么回事呢,为什么发了三篇别的都没有发出去呢
其实这是CSDN限制的问题哦,如果你尝试在这篇博客下面连续发四个评论,你就会发现——这是不可行的!而过了一段时间之后再发,就又发的出去了
经过我多次的实验,基本可以确定,这个CD的时间是一分钟左右,也就是说,在CSDN里,你一分钟最多只能发三个评论哦,那么就只好在发完一个评论之后,让程序休息一段时间啦
完整代码
import requests
from lxml import etree
import re
import time
url = 'https://blog.csdn.net/qq_45599865'
headers = {
'cookie' : '用你自己的辣',
'user-agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.72 Safari/537.36 Edg/89.0.774.45'
}
res = requests.get(url = url , headers = headers).text
#print(res)
tree = etree.HTML(res)
lst = tree.xpath('//*[@id="floor-user-profile_485"]/div/div[2]/div/div[2]/div/div[2]/div/div')
for i in lst :
href = i.xpath('//article[@class="blog-list-box"]/a/@href')
#print(href)
for hre in href:
#print(hre)
url1 = 'https://blog.csdn.net/phoenix/web/v1/comment/submit'
headers1 = {
'cookie': '真是的都说了几遍啦,真是讲不明白呢,不过,这样的你,也有点可爱哦(呕)',
'referer': '{0}?spm=1001.2014.3001.5501'.format(hre),
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'
}
hre = hre + "@"
ex = '/article/details/(.*?)@'
hr = re.findall(ex , hre)[0]
#print(hr)
data1 = {
'commentId' : '',
'content': '太强了',
'articleId': '{0}'.format(hr)
}
try:
requests.post(url=url1, headers=headers1, data=data1)
print("成功!")
except:
print("失败。。")
time.sleep(30)
【注意事项】非常非常的重要
如果要在学姐的博客下面发评论的话,记得点赞和关注哦