使用NumPy实现人工神经网络分类图像
转载自深度学习炼丹微信公众号
本文使用人工神经网络(ANN)对Fruits360图像数据集进行分类,从头开始在NumPy中实现ANN,Fruits360数据集有60类水果,如苹果,番石榴,鳄梨,香蕉,樱桃,枣,猕猴桃,桃子等。在这里,我们使用4个选定的类别,分别是苹果,柠檬,芒果和覆盆子。每个类别有大约491个图像用于训练,另外162个用于测试。图像像素大小为100x100。
github:https://github.com/ahmedfgad/NumPyANN
特征提取
首先选择合适的一组,以达到最高的分类准确度。根据下面显示的4个选定类别的样本图像,它们的颜色不同,这就是为什么颜色特征适合用于此任务的原因。

RGB颜色空间不会将颜色信息与其他类型的信息(如照明)隔离开来。因此,如果RGB用于表示图像,则3个通道将参与计算。出于这个原因,最好使用将颜色信息隔离成单个通道(如HSV)的颜色空间。在这种情况下,颜色通道是色调通道(H)。下图显示了之前呈现的4个样本的色调通道。我们可以注意到每个图像的色调值与其他图像的不同之处。

色调通道大小仍为100x100。如果将整个通道应用于ANN,则输入层将具有10,000个神经元。网络仍然巨大。为了减少使用的数据量,我们可以使用直方图来表示色调通道。直方图将具有360个区间,反映色调值的可能值的数量。以下是4个样本图像的直方图。对于色调通道使用360箱直方图,似乎每个水果都投票到直方图的某些特定箱。与使用RGB颜色空间中的任何通道相比,不同类别之间的重叠较少。例如,与芒果相比,苹果直方图中的区间为0到10,其区间为90到110。

这是从4个图像计算色调通道直方图的代码。
import numpy
import skimage.io, skimage.color
import matplotlib.pyplot
raspberry = skimage.io.imread(fname="raspberry.jpg", as_grey=False)
apple = skimage.io.imread(fname="apple.jpg", as_grey=False)
mango = skimage.io.imread(fname="mango.jpg", as_grey=False)
lemon = skimage.io.imread(fname="lemon.jpg", as_grey=False)
apple_hsv = skimage.color.rgb2hsv(rgb=apple)
mango_hsv = skimage.color.rgb2hsv(rgb=mango)
raspberry_hsv = skimage.color.rgb2hsv(rgb=raspberry)
lemon_hsv = skimage.color.rgb2hsv(rgb=lemon)
fruits = ["apple", "raspberry", "mango", "lemon"]
hsv_fruits_data = [apple_hsv, raspberry_hsv, mango_hsv, lemon_hsv]
idx = 0
for hsv_fruit_data in hsv_fruits_data:
fruit = fruits[idx]
hist = numpy.histogram(a=hsv_fruit_data[:, :, 0], bins=360)
matplotlib.pyplot.bar(left=numpy.arange(360), height=hist[0])
matplotlib.pyplot.savefig(fruit+"-hue-histogram.jpg", bbox_inches="tight")
matplotlib.pyplot.close("all")
idx = idx + 1
通过循环使用的4个图像类中的所有图像,我们可以从所有图像中提取特征。下一个代码就是这样做的。根据4类(1,962)中的图像数量和从每个图像(360)提取的特征向量长度,创建NumPy零数组并将其保存在dataset_features变量中。为了存储每个图像的类标签,创建了另一个名为outputs的 NumPy数组。apple的类标签为0,lemon为1,mango为2,raspberry为3.代码期望它在根目录中运行,其中有4个文件夹根据名为fruits的列表中列出的水果名称命名。它遍历所有文件夹中的所有图像,从每个图像中提取色调直方图,为每个图像分配一个类标签,最后使用pickle库保存提取的特征和类标签。您也可以使用NumPy来保存生成的NumPy数组而不是pickle。
import numpy
import skimage.io, skimage.color, skimage.feature
import os
import pickle
fruits = ["apple", "raspberry", "mango", "lemon"]
#492+490+490+490=1,962
dataset_features = numpy.zeros(shape=(1962, 360))
outputs = numpy.zeros(shape=(1962))
idx = 0
class_label = 0
for fruit_dir in fruits:
curr_dir = os.path.join(os.path.sep, fruit_dir)
all_imgs = os.listdir(os.getcwd()+curr_dir)
for img_file in all_imgs:
fruit_data = skimage.io.imread(fname=os.getcwd()+curr_dir+img_file, as_grey=False)
fruit_data_hsv = skimage.color.rgb2hsv(rgb=fruit_data)
hist = numpy.histogram(a=fruit_data_hsv[:, :, 0], bins=360)
dataset_features[idx, :] = hist[0]
outputs[idx] = class_label
idx = idx + 1
class_label = class_label + 1
with open("dataset_features.pkl", "wb") as f:
pickle.dump("dataset_features.pkl", f)
with open("outputs.pkl", "wb") as f:
pickle.dump(outputs, f)
目前,使用360个元素的特征向量来表示每个图像。过滤这些元素是为了保留最相关的元素以区分4个类。减少的特征向量长度是102而不是360.使用更少的元素有助于比以前更快地进行训练。所述dataset_features可变形状将1962x102。
到目前为止,训练数据(功能和类标签)已准备就绪。接下来是使用NumPy实现ANN。
ANN实现
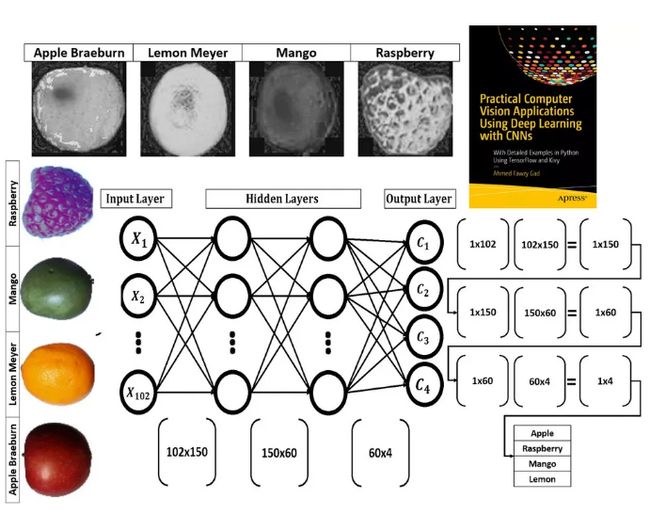
下图显示了目标ANN结构。有一个输入层有102个输入,2个隐藏层有150和60个神经元,输出层有4个输出(每个水果类一个)。
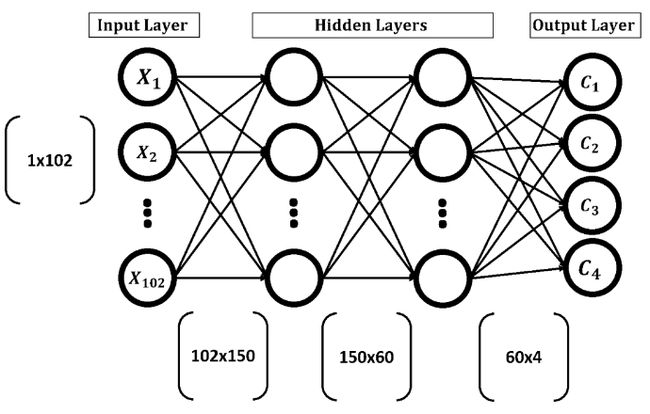
任何层的输入向量乘以(矩阵乘法)权重矩阵,将其连接到下一层以产生输出向量。这样的输出矢量再次乘以将其层连接到下一层的权重矩阵。该过程继续,直到到达输出层。矩阵乘法的总结在下图中。

大小为1x102的输入向量将乘以大小为102x150的第一个隐藏层的权重矩阵。记住它是矩阵乘法。因此,输出阵列形状为1x150。然后将这种输出用作第二隐藏层的输入,其中它乘以尺寸为150×60的权重矩阵。结果大小为1x60。最后,这样的输出乘以第二隐藏层和大小为60x4的输出层之间的权重。结果最终的大小为1x4。此结果向量中的每个元素都指向一个输出类。输入样本根据得分最高的类别进行标记。
用于实现此类乘法的Python代码如下所示。
import numpy
import pickle
def sigmoid(inpt):
return 1.0 / (1 + numpy.exp(-1 * inpt))
f = open("dataset_features.pkl", "rb")
data_inputs2 = pickle.load(f)
f.close()
features_STDs = numpy.std(a=data_inputs2, axis=0)
data_inputs = data_inputs2[:, features_STDs > 50]
f = open("outputs.pkl", "rb")
data_outputs = pickle.load(f)
f.close()
HL1_neurons = 150
input_HL1_weights = numpy.random.uniform(low=-0.1, high=0.1,
size=(data_inputs.shape[1], HL1_neurons))
HL2_neurons = 60
HL1_HL2_weights = numpy.random.uniform(low=-0.1, high=0.1,
size=(HL1_neurons, HL2_neurons))
output_neurons = 4
HL2_output_weights = numpy.random.uniform(low=-0.1, high=0.1,
size=(HL2_neurons, output_neurons))
H1_outputs = numpy.matmul(a=data_inputs[0, :], b=input_HL1_weights)
H1_outputs = sigmoid(H1_outputs)
H2_outputs = numpy.matmul(a=H1_outputs, b=HL1_HL2_weights)
H2_outputs = sigmoid(H2_outputs)
out_otuputs = numpy.matmul(a=H2_outputs, b=HL2_output_weights)
predicted_label = numpy.where(out_otuputs == numpy.max(out_otuputs))[0][0]
print("Predicted class : ", predicted_label)
在读取先前保存的特征及其输出标签并过滤特征之后,定义层的权重矩阵。它们随机给出-0.1到0.1的值。例如,变量“input_HL1_weights”保持输入层和第一隐藏层之间的权重矩阵。根据特征元素的数量和隐藏层中神经元的数量来定义这种矩阵的大小。
在创建权重矩阵之后,接下来是应用矩阵乘法。例如,变量“H1_outputs”保持将给定样本的特征向量乘以输入层和第一隐藏层之间的权重矩阵的输出。
通常,激活函数应用于每个隐藏层的输出,以在输入和输出之间创建非线性关系。例如,矩阵乘法的输出应用于S形激活函数。
在生成输出层输出之后,进行预测。预测的类标签保存在“predict_label”变量中。对每个输入样本重复这些步骤。下面给出了适用于所有样本的完整代码。
import numpy
import pickle
def sigmoid(inpt):
return 1.0 / (1 + numpy.exp(-1 * inpt))
def relu(inpt):
result = inpt
result[inpt < 0] = 0
return result
def update_weights(weights, learning_rate):
new_weights = weights - learning_rate * weights
return new_weights
def train_network(num_iterations, weights, data_inputs, data_outputs, learning_rate, activation="relu"):
for iteration in range(num_iterations):
print("Itreation ", iteration)
for sample_idx in range(data_inputs.shape[0]):
r1 = data_inputs[sample_idx, :]
for idx in range(len(weights) - 1):
curr_weights = weights[idx]
r1 = numpy.matmul(a=r1, b=curr_weights)
if activation == "relu":
r1 = relu(r1)
elif activation == "sigmoid":
r1 = sigmoid(r1)
curr_weights = weights[-1]
r1 = numpy.matmul(a=r1, b=curr_weights)
predicted_label = numpy.where(r1 == numpy.max(r1))[0][0]
desired_label = data_outputs[sample_idx]
if predicted_label != desired_label:
weights = update_weights(weights,
learning_rate=0.001)
return weights
def predict_outputs(weights, data_inputs, activation="relu"):
predictions = numpy.zeros(shape=(data_inputs.shape[0]))
for sample_idx in range(data_inputs.shape[0]):
r1 = data_inputs[sample_idx, :]
for curr_weights in weights:
r1 = numpy.matmul(a=r1, b=curr_weights)
if activation == "relu":
r1 = relu(r1)
elif activation == "sigmoid":
r1 = sigmoid(r1)
predicted_label = numpy.where(r1 == numpy.max(r1))[0][0]
predictions[sample_idx] = predicted_label
return predictions
f = open("dataset_features.pkl", "rb")
data_inputs2 = pickle.load(f)
f.close()
features_STDs = numpy.std(a=data_inputs2, axis=0)
data_inputs = data_inputs2[:, features_STDs > 50]
f = open("outputs.pkl", "rb")
data_outputs = pickle.load(f)
f.close()
HL1_neurons = 150
input_HL1_weights = numpy.random.uniform(low=-0.1, high=0.1,
size=(data_inputs.shape[1], HL1_neurons))
HL2_neurons = 60
HL1_HL2_weights = numpy.random.uniform(low=-0.1, high=0.1,
size=(HL1_neurons, HL2_neurons))
output_neurons = 4
HL2_output_weights = numpy.random.uniform(low=-0.1, high=0.1,
size=(HL2_neurons, output_neurons))
weights = numpy.array([input_HL1_weights,
HL1_HL2_weights,
HL2_output_weights])
weights = train_network(num_iterations=10,
weights=weights,
data_inputs=data_inputs,
data_outputs=data_outputs,
learning_rate=0.01,
activation="relu")
predictions = predict_outputs(weights, data_inputs)
num_flase = numpy.where(predictions != data_outputs)[0]
print("num_flase ", num_flase.size)
在“权重”变量保持整个网络所有的权重。基于每个权重矩阵的大小,动态地指定网络结构。例如,如果“input_HL1_weights”变量的大小是102x80,那么我们可以推断出第一个隐藏层有80个神经元。
该“train_network”为核心功能,因为它通过所有样品循环训练网络。对于每个样本,应用列表3-6中讨论的步骤。它接受训练迭代次数,功能,输出标签,权重,学习速率和激活功能。激活功能有两种选择,即ReLU或sigmoid。ReLU是一个阈值函数,只要它大于零,就会返回相同的输入。否则,它返回零。
如果网络对给定样本做出错误预测,则使用“update_weights”函数更新权重。没有使用优化算法来更新权重。根据学习率简单地更新权重。准确度不超过45%。为了获得更好的准确性,使用优化算法来更新权重。例如,您可以在scikit-learn库的ANN实现中找到梯度下降技术。