关于windows下的libtorch配置
1.环境
- Windows service 2012 R2/Windows10
- Cuda 9.0
- OpenCV3.4.1
- Libtorch1.0
- VS2017/VS2015
2.配置
-
第一步:CUDA 9.0+cudnn7.5安装(也可以用CUDA8.0)
如果已经安装了cuda8.0及以上版本,可以忽略此步骤。
libtorch有cuda8.0 和cuda9.0的版本,为了与vs版本保持一致,这里建议用cuda9.0版本(当然cuda8.0也可以成功编译),参考安装链接:https://blog.csdn.net/u013165921/article/details/77891913。
- 第二步:VS2017下载
下载Visio Studio Installer,通过Visio Studio Installer安装vs2017,安装时选择使用C++的桌面开发,记得在单个组件上一定要将所有的Windows 10 SDK选上,其他的正常安装.
- 第三步:VS2017配置Opencv3.4.1(到目前为止libtorch不支持opencv4.0)
这里建议配置opencv3.4版本,目前libtorch还不支持opencv4.0,opencv配置的步骤比较多,如果您的电脑还未配置Opencv,您可以参考这个博客可以配置成功:https://blog.csdn.net/qq_41175905/article/details/80560429,如果在这之前已经配置好了Opencv,可以忽略此步骤.
- 第四步:Libtorch配置
1.libtorch 1.0 c++版本下载:
cuda8.0版本的libtorch1.0下载:https://download.pytorch.org/libtorch/cu80/libtorch-win-shared-with-deps-latest.zip。
cuda9.0版本的libtorch1.0下载:https://download.pytorch.org/libtorch/cu90/libtorch-win-shared-with-deps-latest.zip。
Windows版本的libtorch已经是编译好了的,下载后解压即可。
2.修改Cmakelists.txt文件:
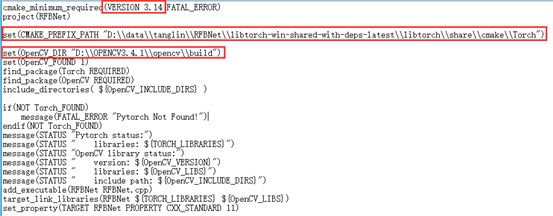
这里需要修改3个地方:
l 第一个红框修改为当前的cmake版本
l 第二个红框修改为当前的libtorch路径
l 第三个红框设置为当前的..\opencv\build目录路径。
3.libtorch联合编译
首先我已经有了以下等待编译相关文件
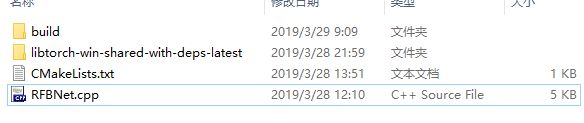
在..\build路径下内打开命令行窗口,输入:
cmake -DCMAKE_PREFIX_PATH=C:\Program Files\opencv\build\x64\vc14\lib;D:\data\tanglin\RFBNet\libtorch-win-shared-with-deps-latest\libtorch -DCMAKE_BUILD_TYPE=Release -G"Visual Studio 15 2017 Win64" ..
此处分别是opencv路径、libtorch路径和VS版本,需根据自己的环境修改。如果顺利则会显示生成成功:

3.运行
打开..\build文件夹,则会看到生成成功的工程文件RFBNet.vcxproj,右键用vs2017或者vs2015打开工程文件。
链接..\nms_gpu目录下的gpu_nms.h头文件和nms_lib.lib文件到RFBNet.cpp中,vs2017链接lib静态库参考链接:https://blog.csdn.net/tangyanzhi1111/article/details/78962208。解决方案配置需选择Release x64,点击运行。
运行的时候一般会出现找不到torch.dll等问题,因此需要将..\libtorch\lib目录下相对应的dll文件复制到..\build\Release目录下。复制过去后则会成功运行。
4.附加
1.关于VS2017+CUDA9.0编程环境配置
cuda安装成功后,会自动设置以下环境变量:

其他教程中还需要在环境变量中添加以下变量,但是我没添加它也可以用:
CUDA_SDK_PATH = C:\ProgramData\NVIDIA Corporation\CUDA Samples\v9.0
CUDA_LIB_PATH = %CUDA_PATH%\lib\x64 CUDA_BIN_PATH = %CUDA_PATH%\bin
CUDA_SDK_BIN_PATH = %CUDA_SDK_PATH%\bin\win64
CUDA_SDK_LIB_PATH = %CUDA_SDK_PATH%\common\lib\x64打开VS2017.创建一个空win32程序,即test_cuda项目
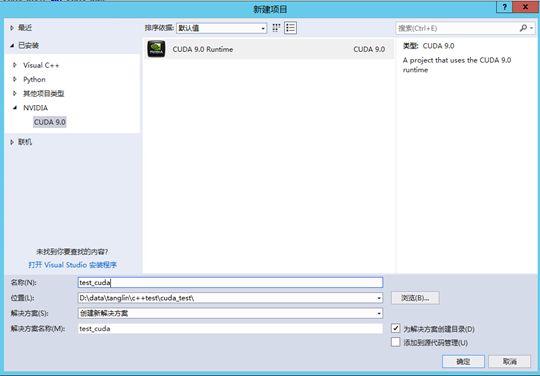
.右键源文件文件夹->添加->新建项->选择CUDA C/C++File,取名test
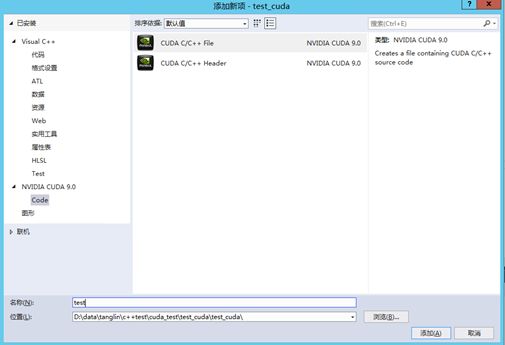
选择test_cuda,点击右键–>项目依赖项–>自定义生成,选择CUDA9.0
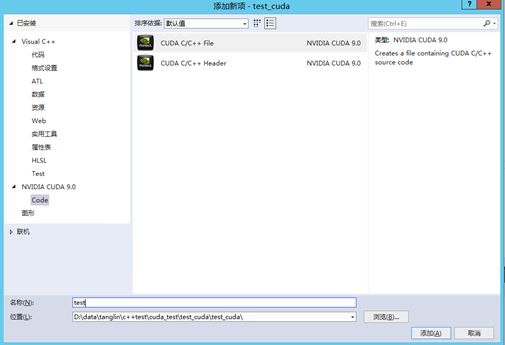
点击test.cu的属性,在配置属性–>常规–>项类型–>选择“CUDA C/C++”
接下来需要配置一些项目:
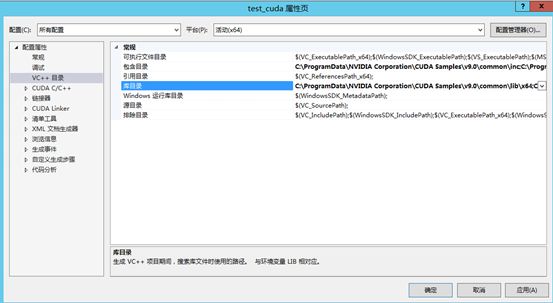
右键项目 → 属性 → 配置属性 → VC++目录 → 包含目录,添加以下目录:
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v9.0\include C:\ProgramData\NVIDIA Corporation\CUDA Samples\v9.0\common\inc
右键项目 → 属性 → 配置属性 → VC++目录 → 库目录,添加以下目录:
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v9.0\lib\x64 C:\ProgramData\NVIDIA Corporation\CUDA Samples\v9.0\common\lib\x64
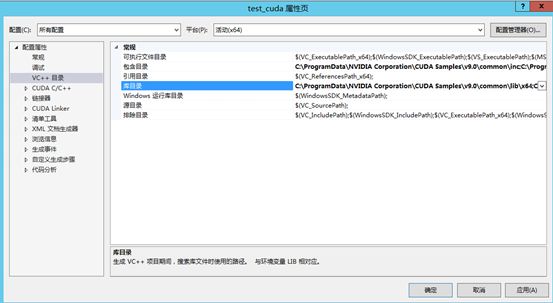
配置CUDA静态链接库路径:
右键项目 → 属性 → 配置属性 → 链接器 → 常规 → 附加库目录,添加以下目录:
$(CUDA_PATH_V9_0)\lib\$(Platform)
选用CUDA静态链接库:
右键项目 → 属性 → 配置属性 → 链接器 → 输入 → 附加依赖项,添加以下库:
cublas.lib;cublas_device.lib;cuda.lib;cudadevrt.lib;cudart.lib;cudart_static.lib;cufft.lib;cufftw.lib;curand.lib;cusolver.lib;cusparse.lib;nppc.lib;nppial.lib;nppicc.lib;nppicom.lib;nppidei.lib;nppif.lib;nppig.lib;nppim.lib;nppist.lib;nppisu.lib;nppitc.lib;npps.lib;nvblas.lib;nvcuvid.lib;nvgraph.lib;nvml.lib;nvrtc.lib;OpenCL.lib;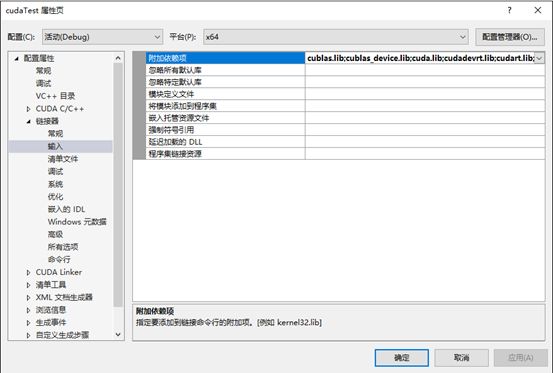
修改test.cu,添加以下测试代码:
#include "cuda_runtime.h" #include "device_launch_parameters.h" #includeint main() { int deviceCount; cudaGetDeviceCount(&deviceCount); int dev; for (dev = 0; dev < deviceCount; dev++) { int driver_version(0), runtime_version(0); cudaDeviceProp deviceProp; cudaGetDeviceProperties(&deviceProp, dev); if (dev == 0) if (deviceProp.minor = 9999 && deviceProp.major == 9999) printf("\n"); printf("\nDevice%d:\"%s\"\n", dev, deviceProp.name); cudaDriverGetVersion(&driver_version); printf("CUDA驱动版本: %d.%d\n", driver_version / 1000, (driver_version % 1000) / 10); cudaRuntimeGetVersion(&runtime_version); printf("CUDA运行时版本: %d.%d\n", runtime_version / 1000, (runtime_version % 1000) / 10); printf("设备计算能力: %d.%d\n", deviceProp.major, deviceProp.minor); printf("Total amount of Global Memory: %u bytes\n", deviceProp.totalGlobalMem); printf("Number of SMs: %d\n", deviceProp.multiProcessorCount); printf("Total amount of Constant Memory: %u bytes\n", deviceProp.totalConstMem); printf("Total amount of Shared Memory per block: %u bytes\n", deviceProp.sharedMemPerBlock); printf("Total number of registers available per block: %d\n", deviceProp.regsPerBlock); printf("Warp size: %d\n", deviceProp.warpSize); printf("Maximum number of threads per SM: %d\n", deviceProp.maxThreadsPerMultiProcessor); printf("Maximum number of threads per block: %d\n", deviceProp.maxThreadsPerBlock); printf("Maximum size of each dimension of a block: %d x %d x %d\n", deviceProp.maxThreadsDim[0], deviceProp.maxThreadsDim[1], deviceProp.maxThreadsDim[2]); printf("Maximum size of each dimension of a grid: %d x %d x %d\n", deviceProp.maxGridSize[0], deviceProp.maxGridSize[1], deviceProp.maxGridSize[2]); printf("Maximum memory pitch: %u bytes\n", deviceProp.memPitch); printf("Texture alignmemt: %u bytes\n", deviceProp.texturePitchAlignment); printf("Clock rate: %.2f GHz\n", deviceProp.clockRate * 1e-6f); printf("Memory Clock rate: %.0f MHz\n", deviceProp.memoryClockRate * 1e-3f); printf("Memory Bus Width: %d-bit\n", deviceProp.memoryBusWidth); } return 0; }
生成,这里注意VS2017版本和CUDA9.0不兼容,因此在visio studio installer 2017里面安装VS2015,如图所示:

如果一切顺利,则会出现:
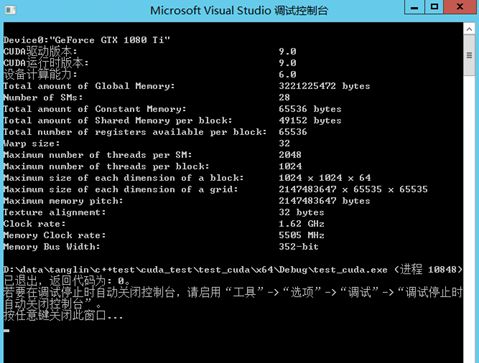
2.关于CUDA编程静态链接库的生成
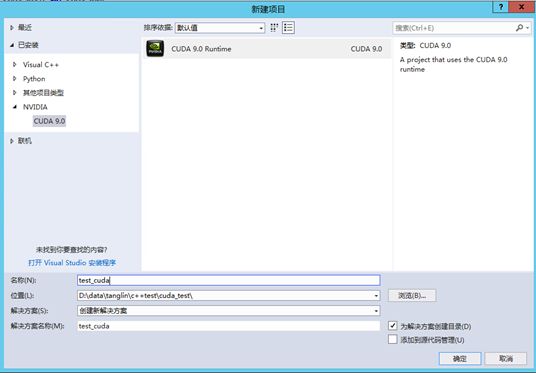
VS2017新建新建-项目-CUDA 9.0 Runtime , 输入项目名称 “test_cuda”此时会自动生成代码 kernel.cu :
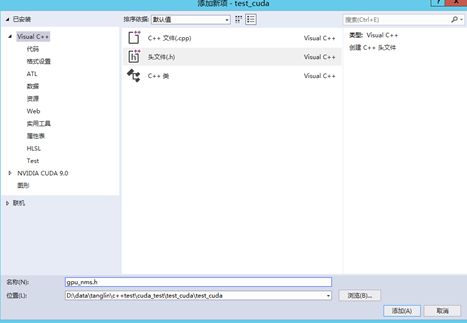
右键项目test_cuda->添加->新建项->选择visual c++头文件,命名为gpu_nms.h
在头文件中添加函数的声明:
void _nms(int* keep_out, int* num_out, const float* boxes_host, int boxes_num, int boxes_dim, float nms_overlap_thresh, int device_id);将新项目自动生成的代码 kernel.cu 里面的内容修改为自己lib文件想要定义的函数内容,同时需要添加之前新建的头文件
#include "gpu_nms.h"修改test_cuda项目的项目属性,如果是VS2017版本需要将平台工具集修改为vs2015,配置类型设置为静态库(.lib)
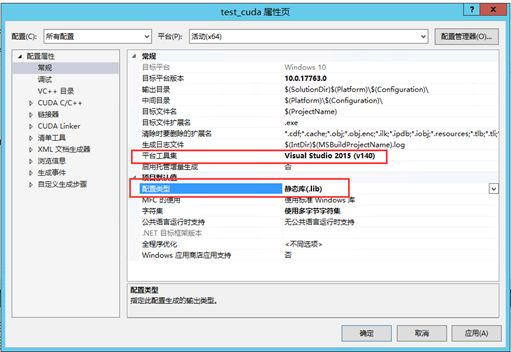
此时所有配置均完成,点击运行,在路径..\test_cuda\x64\Debug目录下则会生成test_cuda.lib文件.
3.vs2017静态链接库lib的引用
vs里面静态链接库引用非常简单,这里介绍两种方法:
l 第一种方法,直接在.c文件中声明所调用的lib文件名“#pragma comment(lib,"Staticlib.lib")
l 第二种方法:
- 添加工程的头文件目录:工程---属性---配置属性---c/c++---常规---附加包含目录:加上头文件存放目录;
- 添加文件引用的lib静态库路径:工程---属性---配置属性---链接器---常规---附加库目录:加上lib文件存放目录;
- 然后添加工程引用的lib文件名:工程---属性---配置属性---链接器---输入---附加依赖项:加上lib文件名