前言:又到春招季!作为国民级出行服务平台,高德业务快速发展,大量校招/社招名额开放,欢迎大家投递简历,详情见文末。为帮助大家更了解高德技术,我们策划了 #春招专栏#的系列文章,组织各业务团队的高年级同学以 科普+应用实践为主要内容为大家做相关介绍。
本文是#春招专栏#系列的第1篇,根据高德机器学习研发部负责人damon在AT技术讲坛所分享的《AI在出行领域的应用实践》的内容整理而成。在不影响原意的情况下对内容略作删节。
AT技术讲坛(Amap Technology Tribune)是高德发起的一档技术交流活动,每期围绕一个主题,我们会邀请阿里集团内外的专家以演讲、QA、开放讨论的方式,与大家做技术交流。
damon根据用户在出行前,出行中和出行后如何使用导航服务,分别选取了几个典型的业务场景来介绍AI算法在其中的应用,最后对未来做了一些展望。

以某位同学周末和朋友相约去“木屋烧烤”店撸串为例,假设这位同学选择驾车前往目的地,我们来看下AI算法是如何在导航过程中起到作用的。
出行前,先做路线规划,ETA(预估到达时间),不要迟到;出行中,最怕的就是遇到突发动态事件而影响到出行时间;出行后(到目的地),餐馆是否还在正常营业,也需要通过技术挖掘,帮助用户提前规避白跑一趟的风险。
下面分别介绍。
出行前-路线规划
路线规划,和网页搜索,商品搜索的推荐算法很相似,为用户推荐一条符合个人喜好的优质路线。推荐的路线要符合以下几个条件:
- 能走:此路能通,按照路线可以到达终点。
- 好走:路线质量在当前地点时间下确保优质。
- 千人千面:不同用户在保证路线优质的前提下,个性化调整更符合用户偏好。
同时,在不对用户产生误导的前提下,提供更多的对比参考给用户来选择:
- 优质:相比首路线/主路线,有一定的、用户可感受到的优势。
- 多样:相比首路线/主路线,尽可能有自己的特长。
路线规划算法的特点
从用户产生出行需求,到需求得到满足。在用户搜索的时候,上传的Query除了有起终点和导航策略,也会像其他搜索一样,有隐含的需求,比如个性化和场景化。在导航业务里面,个性化可以拆分成熟路和偏好两个维度,熟路比较容易理解,偏好是指用户对时间、距离、红绿灯、收费等不同维度上的偏好。
那么,对应的解决方案,我们引入用户ID,存储记忆了用户的起终点对应的熟路信息。对用户的偏好,类似DIN的网络结构,对用户历史导航序列进行建模,获取用户偏好信息。
在用户提交搜索需求之后,对导航引擎来说,也分为召回,排序和过滤几部分。
对于导航的召回,对性能要求比较高,所以目前召回的结果较少。对排序来说,同样是多目标,而且多目标之间要进行平衡的业务。类比到电商推荐领域,不仅希望用户更多地对商品进行点击浏览,还希望用户在看完商品介绍之后进行购买,提高GMV。
对于地图出行,不仅希望用户更多的使用导航且按照推荐的路线走,还希望实走时间要尽可能短,用户反馈尽量好。
而且,和其他领域类似,多个目标之间会存在冲突,比如电商CTR和GMV。在导航领域,让用户尽可能的走封闭道路,没有出口,那肯定实走覆盖率就上升了,但是这样规划的路线会绕远,时间和距离都变差。
多目标的平衡,如何在“帕累托最优”的情况下,进行多个目标之间的取舍、平衡,是大家一直在探索的问题,我们目前采用的是带约束的最优化问题来进行建模,就是保证其他指标不变差的情况下,把某个指标最优化。
最后,用户拿到导航引擎返回的路线结果,特点是信息少,用户只能看到整条路线的总时间、总距离和收费等统计信息,对于这条路好不好走,能不能走很难知道。
而且,大部分用户是在陌生场景下用导航,对导航依赖很重,很难决策走哪条路更好,这就导致排序在首条的方案选择率很高,达到90%以上,这个偏置是很严重的,在训练实走覆盖率的时候,我们设计了偏置网络,来吸收用户这种倾向。
导航还有一个特点,一旦出错,对用户伤害特别大,比如遇到小路,用户的车可能会出现刮蹭;遇到封路,用户可能就得绕路,付出相当的时间和金钱成本。这往往会比信息搜索给用户带来的影响和伤害更大。所以,我们在过滤阶段,对Badcase的过滤也是严格作为约束要求的。
路线规划召回算法
路线规划算法,经典的是教科书上的Dijkstra算法,存在的问题就是性能比较差,线上实际应用都做了优化,这里就不展开介绍了。
当起终点距离超过500公里,性能基本就不可接受了,虽然有启发式A star算法,但是A star算法有可能丢最优解,并不是完美解决性能问题的方法。
解决性能问题的思路,一个是分布式,一个是Cache,而最短路线搜索并不像网页搜索,分布式并不能很好的解决性能问题,所以目前工业界实际使用的算法都是基于Cache的方法。
Cache的方法就是提前把一些起终点对之间的最短路线计算好(Shortcuts),在用户请求过来的时候,利用好这些Shortcuts,达到加快求路的目的(简单举例子,比如从北京到广州,如果提前计算好了从北京到济南,济南到南京,南京到广州的最短路径,那就可以在计算北京到广州的时候,利用这些提前计算好的最短路线)。
其中最为经典的一个算法就是CH算法(Contraction Hierarchies),在预处理阶段,对所有节点进行了重要性排序,逐渐把不重要的点去掉,然后增加Shortcuts;Query查询阶段,从起点和终点分别开始双向求路,只找重要性高的点,来达到加速的目的。
既然是Cache,就会面临一个更新的问题,比如原始路网的路况变化了,或者原始路网某条路封路了,那么提前缓存好的Shortcuts也需要更新。
这个时候CH的算法,由于Shortcuts结构设计不够规律,更新就很慢,无法响应实时路况的变化。于是,路线规划算法推进到了下一代,CBR算法(Cell based Routing),这个算法通过分而治之的思想,在预处理阶段,把全国路网切分成n个子图,切分的要求是子图之间连接的边(边界边)尽可能的少。
在每个子图内,再继续往下切分,进而形成金字塔结构,预处理阶段就是把边界边之间的最短路径都提前算好,Cache下来求路的时候,就可以利用这些Shortcuts了。
CBR的优点是,在预处理阶段,路网的切分是分层的,每一层都足够小,在更新这一层的Shortcuts的时候,可以把数据都放到CPU的L1 Cache里去,所以计算速度特别快。
总结一下CBR和CH的区别:
- Query查询性能,CH更快,CH是0.1ms级别,CBR是1-2ms级别。
- Shortcuts更新性能,CH全国路网更新最快能做到10分钟,而CBR能做到15秒更新全国,可以满足实时路况变化和路网实时更新的需求。
- CH的Shortcuts不规律,导致不同策略之间(躲避拥堵,高速优先等)不能很好的复用Shortscuts的起终点结构,所以不同策略需要单独重建Shortcuts,内存占用非常大。
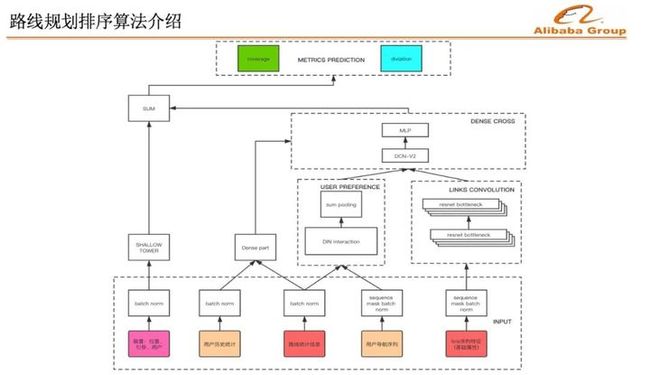
这是我们排序的网络结构,左边是用户偏置网络,把路线排序的顺序,以及引导路线之间的相似度信息输入进去,期望尽可能消除掉偏置带来的影响。中间输入的用户历史统计信息和用户导航序列信息,用来提取用户的个性化偏好。优化的主要目标是实走覆盖率。
新一代的路线规划算法,要求提供随时间推演的能力。比如8:00从起点出发,后面要走 1 2 3 ..n条路到达目的地,假设8:10走到第2条道路,8:20走到第3条道路,那么我们在8:00计算Shortcuts的时候,就不能只用到8:00的路况,需要把后续进入某个道路的时刻考虑进来,用那个时刻的路况来计算,这就是TDR求路算法,目前是高德首创的,能真正实现躲避未来的拥堵,并利用未来的畅通来规划路径。
出行前-ETA(预估到达时间)

上面三幅图,选取的是北京西单金融街附近的区域,展示了在三个相邻时间点上的交通状况。其中绿色、黄色、红色代表交通路况不同的状态。
假设现在是18点整,路况预测的目标就是预估未来时刻的交通状况,需要依赖每条道路的历史信息,以及周边邻居的道路拥堵信息,对时空两个维度进行建模。
对时间序列的建模,用RNN,LSTM等SEQ2SEQ的序列,也有采用CNN,TCN等。对空间信息的建模,目前主流的方法是用GRAPH.
尽管模型在不断升级,越来越复杂,但是对于突发事件导致的拥堵,根据历史统计信息,很难预测精准,比如去年9月份在上海世博园区举行外滩大会,世博园平时很少有人去,历史路况都是畅通,而在开会期间,车很多导致很堵。
这个时候靠历史信息是很难预测准确,我们需要一个能代表未来的信号,才能预测,这就是路线规划的信息,如果想去世博园的人很多,那么规划的量就会很多,我们根据规划的量,就能知道未来有很多人想要去世博园,就会导致世博园拥堵。
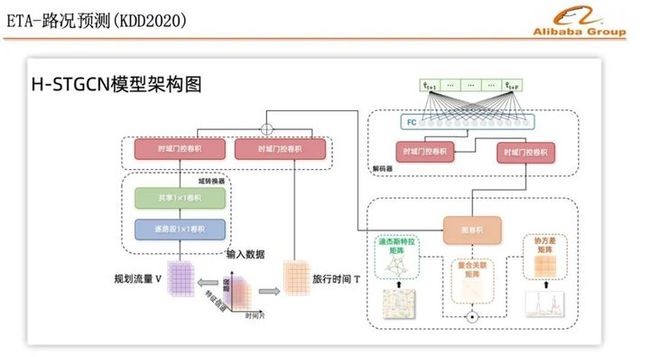
所以,我们把规划的量,通过一个流量往时间域的转换,引入到路况预测模型,效果取得明显提升,尤其是在突发拥堵的时候,高德的这个研究成果被KDD2020收录,并且已经在业务场景中得到了应用,有兴趣的同学可以详细查看我们的论文。
行中-用文本数据挖掘动态交通事件
继续向餐馆前进,导航途中,最怕遇到拥堵,封路等事件,所以高德会想尽一切办法挖掘这些动态事件,帮助用户规避开。现在高德用到了多个维度的数据源,其中的行业和互联网情报都是文本数据,要用到NLP的技术来挖掘。
介绍一下怎么用AI算法来挖掘动态事件。
下面一段文本就是典型的来自于网络媒体的信息:

G0612(西和)高速南绕城路段西山隧道ZK33+844(兰州方向)应急车道停一辆故障大客车暂时封闭,行车道和超车道正常通行,请车辆注意避让、减速慢行。
这段信息是非结构化的,需要我们做预处理,要素提取,再进行事件的组织,组织成架构化的信息,才能自动化的应用。
很自然的,针对要素提取,我们用BERT模型建模,但是BERT模型太复杂,性能比较差,线上实际应用带来很大的挑战。

我们采取了知识蒸馏的方法,训练一个简单的Student的网络,来解决性能问题。知识蒸馏最主要的是如何捕捉潜在语义信息。高德在业界率先提出了用对比学习框架进行知识蒸馏,同时,在计算样本之间距离的时候,提出COS-距离代替欧氏距离的方法,能够让模型有效的学习到潜在语义表达信息。
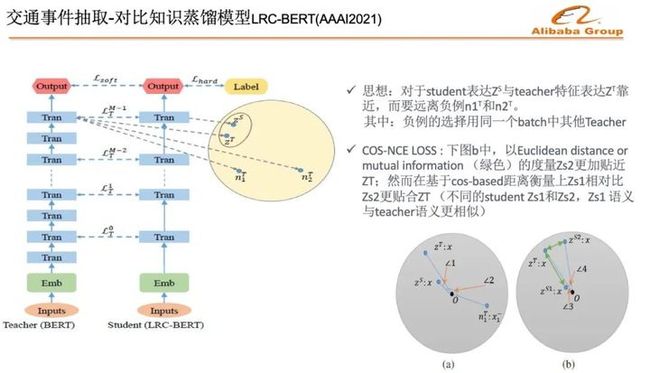
对于Student表达的特征向量与Teacher特征向量距离靠近,而要远离负例。使用余弦距离,比如欧式距离,能够更好适应Teacher网络和Student网络,输出的特征向量长度分布不一致的问题,这个工作成果发表在了AAAI2021上。
出行后-POI数据过期(增强现势性)的问题
人们在高德地图上会看到很多地理位置兴趣点(Point of Interest,缩写为POI),例如餐厅、超市、景点、酒店、车站、停车场等。对POI数据的评价维度包括现势性、准确性、完备性和丰富性。
其中,现势性就是地图所提供的地理空间信息反映当前最新情况的程度,简而言之,增强现势性就是指尽可能快速地发现已停业、搬迁、更名、拆迁的过期冗余POI数据,并将其处理成下线状态的过程。这部分可以参考我们之前发布的文章《高德地理位置兴趣点现势性增强演进之路》。
以上仅是AI算法在出行场景应用的一些举例,更多的技术方案欢迎大家来和我们一起探讨。
出行前景-全局调度
对网页搜索来说,结果是信息,可以无限复制,互不影响;对电商搜索来说,结果是商品,可以认为商品足够多,不够再生产,所以也可以认为互不影响。
不同的是,导航搜索出来的道路资源是有限的,你用的多了,我就用的少。比如,一条路畅通,我们把人导过去,那么这条路就堵死了,所以我们要做全局调度,提高道路资源的使用率。
我们希望全局调度系统能和交通信号灯打通,在一个交通仿真的环境下,用多智能体强化学习的方法,学习到更大规模的交通系统上如何统筹协调车辆、交通灯,充分利用道路资源,进一步缓解拥堵。我们一起来探索!
春招火热进行中,2022届毕业生看过来!
春招火热进行中,2022届毕业生看过来!
春招火热进行中,2022届毕业生看过来!
