伪标签还能这样用?半监督力作UPS(ICLR 2021)大揭秘!
点击上方“CVer”,选择加"星标"置顶
重磅干货,第一时间送达
本文作者:罗驳思 | 来源:知乎(已授权)
https://zhuanlan.zhihu.com/p/350701042
论文标题:In Defense Of Pseudo-Labeling: An Uncertainty-Aware Pseudo-Label Selection Framework For Semi-Supervised Learning (ICLR 2021)
作者&单位:

研究动机
近来半监督图像分类任务有两大核心方法:一致性正则(Consistency Regularization)和打伪标签法(Pseudo-Label)。当前SOTA水平的半监督算法,通常是这两种方法的结合产物,比如知名的Match系列方法:MixMatch(NIPS 2019),ReMixMatch(ICLR 2020),FixMatch(NIPS 2020)和FeatMatch(ECCV 2020)。
一致性正则法在目前的半监督学习领域占据主导地位。其中最常用的技术之一,是基于数据增强的一致性正则。这类技术的惊艳表现,是建立在大量先导工作的基础上的:对于特定数据集的分类任务,我们往往要事先花大力气去搜索最合适的(domain-specific)数据增强策略(如图1所示);比如在CIFAR数据集上取得SOTA方法所采用的增强策略,大多源自前1-2年在该数据集上搜出超参的数据增强AutoAugment(CVPR 2019)、RandAugment(CVPRW 2020)。在更多模态的任务,比如视频分类上,由于缺乏十分有效的数据增强策略,这类半监督方法的泛化性就不那么出彩了。
 图1. 数据增强和相应的一致性正则方法的发展历程:红框标记了数据增强方法,蓝框标记了一致性正则的半监督学习算法,黑色箭头指示这些算法用到的数据增强策略。
图1. 数据增强和相应的一致性正则方法的发展历程:红框标记了数据增强方法,蓝框标记了一致性正则的半监督学习算法,黑色箭头指示这些算法用到的数据增强策略。
打伪标签法常被诟病的一点是:无论样本被贴上的伪标签正确与否,这些标签都有很高的置信度。如果大量的无标注样本被贴上错的标签并用作训练,将导致训练集中存在大量的噪声样本,从而严重影响模型的性能(这就是带噪学习(Learning with noisy labels)研究的范畴)。因此,校正网络模型(calibration of Neural Networks)的输出势在必行。仅凭网络softmax层输出的概率值作为置信度唯一的依据显然不够——作者参考了深度网络不确定性估计的技术(MC-dropout, ICML 2016),计算输出值的不确定性作为另一种置信度(如图2所示),和softmax层输出的概率双管齐下,筛出可靠的贴伪标签的样本。
 图2. 用Dropout计算输出不确定性的示意图
图2. 用Dropout计算输出不确定性的示意图
此外,作者还顺着带噪学习的藤,摸到了Negative Learning的瓜:如图3所示,我们虽不知道样本属于哪类,但对它不属于哪类还是蛮有把握的(Negative learning for noisy labels,ICCV 2019)。这样的伪标签相比传统的Positive Learning的伪标签更为准确,因而能很好地降低标签的带噪率,起到校正模型的作用。
 图3. Negative Learning的思想
图3. Negative Learning的思想
本文提出的Uncertainty-Aware Pseudo-Label Selection Framework (UPS)策略,正是结合了不确定性估计(Uncertainty estimation)和Negative learning的技术,不仅在传统的半监督学习任务上与一致性正则法达到旗鼓相当的水平,而且在视频半监督分类和图片多标签半监督分类领域打破了一致性正则的垄断,取得了更优的效果。
算法研读
1. 兼顾Positive & Negative Pseudo Label的打伪标签法
传统的Pseudo Label方法,通常设定一个阈值,当模型预测样本属于某类的概率超过阈值时,给样本贴上相应的伪标签并用于训练;或者,直接选取模型预测的最大概率所在的类作为伪标签,其公式如下:

其中 表示样本 关于第c类的伪标签, 是模型输出的第c类的概率, 表示阈值。若伪标签的值域为 ,则该标签指示了样本属于/不属于第c类——传统C分类问题中的one-hot label形式,即可转换为由该类标签组成的,1 x C维的标签: 。
既然可以用卡阈值的方法生成Positive Pseudo Label(意即:伪标签指示样本属于某类),何不用类似的方法生成Negative Pseudo Label昵?
令 指示样本 的伪标签是否被用作训练模型, ,其计算公式为:
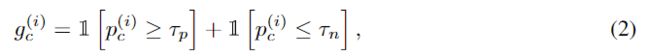
其中, 和 分别表示Positive、Negative Pseudo Label的选取阈值( ),这样就得到了Negative Pseudo Label。
对于单标签分类任务来说,仿照只有Positive Label时常用的交叉熵损失,可设计出Negative Label的损失函数,其中 是样本的伪标签数目, 表示模型的原始输出概率:
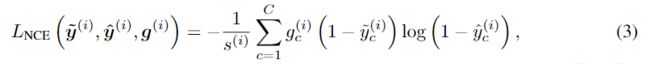
进一步可得到融合Positive & Negative Pseudo Label的损失函数,该损失函数同样可用于多标签分类任务:

2. 基于不确定性的伪标签选择法
前文提到,我们希望把网络模型预测的不确定性用作模型输出的校正。首先,我们要分析网络校正与模型对个体样本输出不确定性的关系。Expected Calibration Error(ECE)是一种衡量网络校正的常用指标,其计算公式如下:
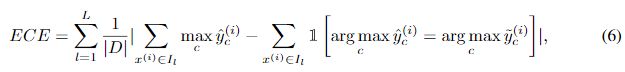
数据集 被等分为 份, 是第 份中的样本。每份的校正偏差(calibration gap),是通过计算其平均置信度和平均准确率的差异来衡量的。计算各个等分的校正偏差的均值,即可得到ECE的值。
在参照MC dropout计算出网络的不确定性以后,就能绘制出训练过程中ECE和不确定性关系曲线,如图4所示:
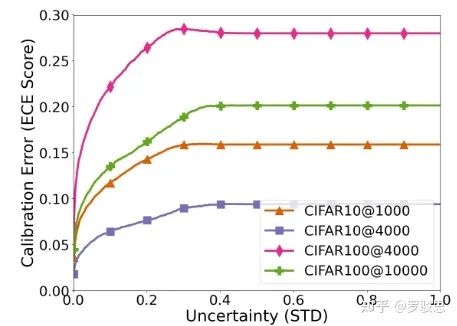 图4. 网络不确定性与网络校正(用ECE值来表示)的关系曲线
图4. 网络不确定性与网络校正(用ECE值来表示)的关系曲线
这直观地说明:如果打上伪标签时模型的不确定性越低,网络校正的误差就越小——也就是说,我们可以计算模型对每个样本输出的不确定性,来判断该样本的伪标签是否可靠!
于是乎,我们依葫芦画瓢,再次用万能的卡阈值技术来筛选可靠的伪标签,只不过这次卡的指标呢,是网络输出的不确定性。我们只需修改一下公式(2)中 的计算方式:
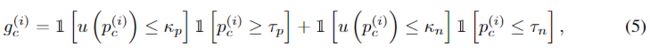
其中 表示模型预测结果 的不确定性估计值, 、 则表示不确定性的阈值。
图5则显示了本文筛选伪标签的方法(UPS)的优越性,可以看到用上不确定性信息前后,筛选标签准确率的显著变化(黄线 > 紫线):
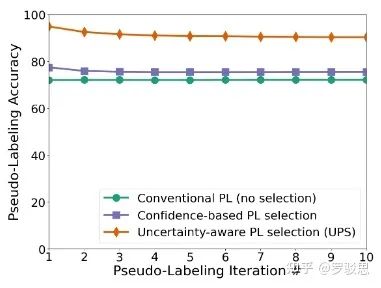 图5
图5
3.1 算法流程
本文的算法整体流程如图6所示:
 图6
图6
总体来说分为3步:
(1) 只用有标注的数据训练一个模型;
(2) 用训练得到的模型结合UPS方法筛选出样本打伪标签;
(3) 拿打上伪标签的数据和有标注数据一起训练模型(重新随机初始化),然后跳至(2)继续执行,直至循环到最大迭代次数。之所以要重新随机初始化,是为了避免打上错误伪标签的样本带来的误差在迭代训练中不断传播。
图7显示了各个阶段选取打伪标签样本的数量,可以发现:UPS方法在训练即将结束时,模型选出的样本数目是最多的。
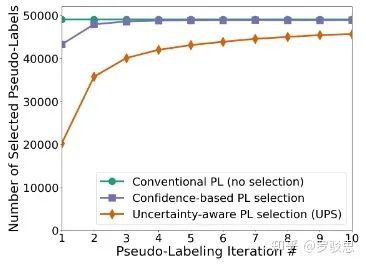 图7
图7
实验结果
实验一:说明方法优异性能的实验
如图8所示,在传统的半监督图片分类任务CIFAR-10和CIFAR-100上,基于打伪标签的UPS算法取得了媲美一致性正则方法MixMatch的性能(backbone为13层的CNN)。
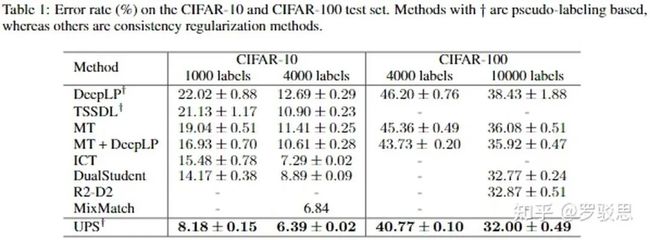 图8. UPS在CIFAR数据集上有着准SOTA的性能
图8. UPS在CIFAR数据集上有着准SOTA的性能
当有标注数据量非常少时,UPS方法也有着稳定的性能表现,如图9所示:
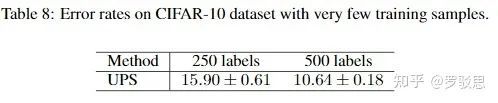 图9.
图9.
图10、11附上其他近年SSL方法的性能以供参考:
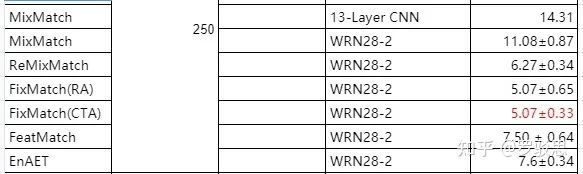 图10. CIFAR-10数据集上其他半监督方法的表现(有标注样本为250个)
图10. CIFAR-10数据集上其他半监督方法的表现(有标注样本为250个)
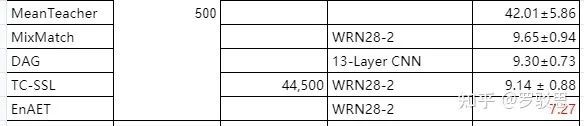 图11. CIFAR-10数据集上其他半监督方法的表现(有标注样本为500个)
图11. CIFAR-10数据集上其他半监督方法的表现(有标注样本为500个)
即便把backbone替换成其他模型,UPS依旧有着出色的表现,如图12所示:
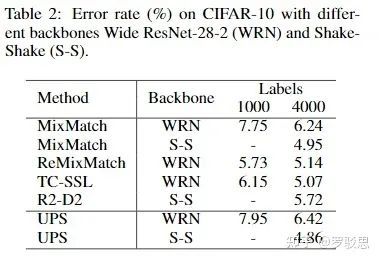 图12.
图12.
综合来看,UPS在CIFAR-10上的表现与MixMatch不分伯仲。
实验二:突出UPS在视频分类任务上的有效性实验
在UCF-101视频分类数据集上,以UPS为代表的、基于打伪标签法的SSL算法也有着出色的表现,如图13所示(MT表示Mean Teacher,PL表示Pseudo Label,S4L表示Self-Supervised Semi-Supervised Learning),且性能更胜基于一致性正则的方法MT:
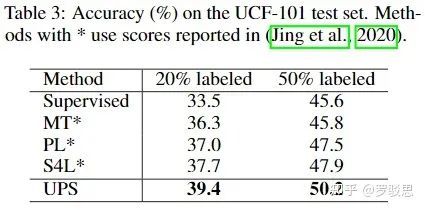 图13.
图13.
实验三:突出UPS在多标签图片分类任务上的有效性实验
在Pascal VOC2007数据集上,UPS方法取得了SOTA的水平。值得一提的是,UPS是第一篇做多标签图片半监督分类的工作;由于UPS与传统的打伪标签法不同,它并未预设每张图片只属于一个类别的条件(MT也是如此),因而在该任务上有着更出色的表现。
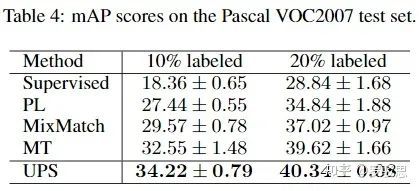 图14.
图14.
实验四:消融实验
在CIFAR-10上作者做了UPS各个模块的消融实验,如图15所示。可以看到,作者提出的UA(Uncertainty Aware)模块起着至关重要的作用,而NL(Negative Learning)模块也带来了一定的性能增益。
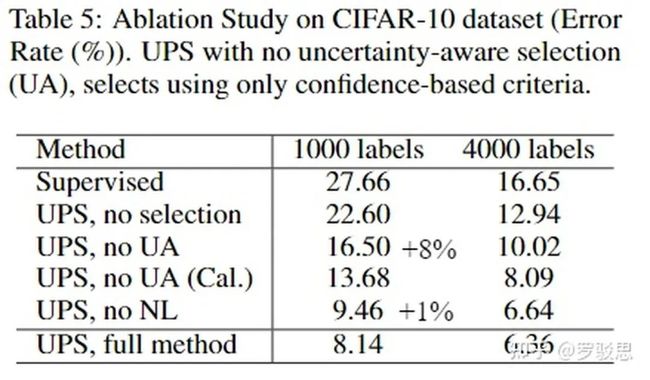 图15.
图15.
实验五:说明UA模块对超参数鲁棒的实验
作者在CIFAR-10上验证了UA模块对于超参数 的鲁棒性,如图16所示,当 时,模型有着出色的性能。
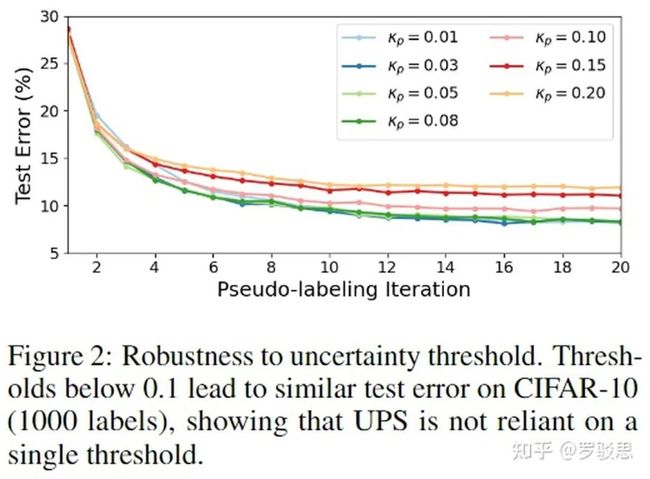 图16.
图16.
实验六:说明不确定性估计模块具有通用性的实验
在CIFAR-10数据集上,作者用SpatialDropout、DropBlock等方法替代Dropout计算模型输出的不确定性,发现实验结果相差仿佛(如图17所示),这说明用不确定性估计筛选伪标签的方法是有着通用性的。
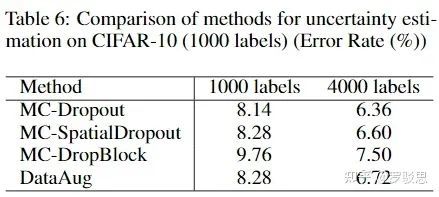 图17.
图17.
实验七:说明UPS与基于数据增强方法带来增益的正交性
在CIFAR-10数据集上,作者先验证了MixUp这一数据增强策略与UPS带来增益的正交性,如图18所示:
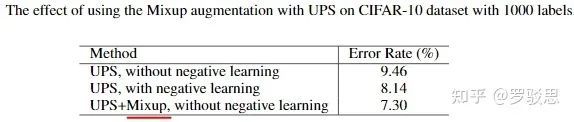 图18.
图18.
随后,作者验证了UPS不采用数据增强策略所能取得的性能,如图19所示:
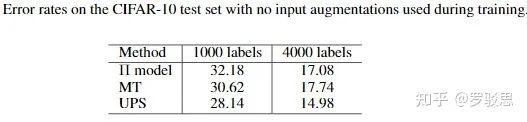 图19.
图19.
回顾上文提及的UPS加上数据增强的总体效果可知,该方法与数据增强带来的增益是正交的。
实验八:说明基于打伪标签法的SSL方法中保持类别均衡的重要性的实验
由于有标注数据非常少,在生成伪标签时,网络更倾向于给较容易区分的类“倾斜”——这种情况在最初的迭代训练周期中尤为显著。图20显示了在CIFAR-10数据集上,第一个迭代周期中选出的伪标签样本的分布:
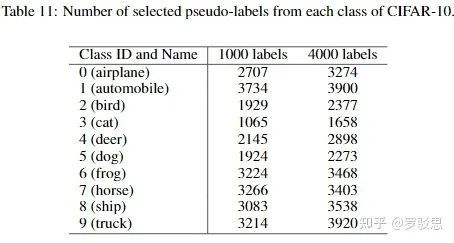 图20.
图20.
可以看到,伪标签最多的类和最少的类的样本之比可达3734:1065=3.5!
为了解决该问题,作者在CIFAR-10的前10个迭代周期强制要求选出的各类伪标签样本数目相当;在Pascal VOC上,作者也采用了类似的策略。作者在这俩数据集上分别做实验,验证了类别均衡策略的必要性,如图21所示:
 图21.
图21.
实验九:定性说明UA模块的有效性
作者在CIFAR-10数据集上选出部分高置信度(置信度超过0.9,按照UPS方法的置信度超参 ,基于置信度的筛选策略无法筛除)且高不确定性(不确定性高于0.1,按照UPS的不确定性超参 ,UPS的UA模块可以筛除)的打上错误伪标签的样本进行可视化,部分结果如图22所示:
 图22.
图22.
参考文献
[1] Rizve, M. N., Duarte, K., Rawat, Y. S., & Shah, M. (2021). In Defense of Pseudo-Labeling: An Uncertainty-Aware Pseudo-label Selection Framework for Semi-Supervised Learning.arXiv preprint arXiv:2101.06329.
[2] Gal, Y., & Ghahramani, Z. (2016, June). Dropout as a bayesian approximation: Representing model uncertainty in deep learning. Ininternational conference on machine learning(pp. 1050-1059). PMLR.
[3] Kim, Y., Yim, J., Yun, J., & Kim, J. (2019). Nlnl: Negative learning for noisy labels. InProceedings of the IEEE/CVF International Conference on Computer Vision(pp. 101-110).
CV资源下载
后台回复:CVPR2020,即可下载代码开源的论文合集
后台回复:ECCV2020,即可下载代码开源的论文合集
后台回复:YOLO,即可下载YOLOv4论文和代码
后台回复:Transformer综述,即可下载两个最新的视觉Transformer综述PDF,肝起来!
重磅!CVer-细分垂直交流群成立
扫码添加CVer助手,可申请加入CVer-细分垂直方向 微信交流群,也可申请加入CVer大群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、Transformer、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测+上海+上交+卡卡),根据格式备注,才能通过且邀请进群

▲长按加微信群
▲点击上方卡片,关注CVer公众号
整理不易,请给CVer点赞和在看!