完全分布式集群搭建
-
虚拟机准备
在上一篇里,我已经详细的讲解了虚拟机的准备工作。
在这里需要重要提醒,一定要三台集群没有启动过的,没有初始化过的!!!
你需要准备三个虚拟机,首先先创建一台JDK、Hadoop都安装完成的虚拟机,剩下的两台只需要修改主机名、修改ip即可.
-
编写集群分发脚本xsync
-
配置一台完全的虚拟机就很耗时间,更别说配置三台,所以这里会利用scp安全拷贝和 rsync 远程同步工具。rsync和scp区别:用rsync做文件的复制要比scp的速度快,rsync只对差异文件做更新。scp是把所有文件都复制过去.所以这里用rsync进行。

-
接下来,就开始实际操作了.
1.先进入/root,然后在root下创建一个新的bin文件 [root@hadoop101 ~]# cd /root/ [root@hadoop101 ~]# mkdir bin 2.进入bin,并在bin文件下开始编辑脚本 [root@hadoop101 ~]# cd bin [root@hadoop101 bin]# vim xsync 3.在脚本下写入如下指令(因为我另外两台虚拟机是hadoop102、hadoop103,所以在循环的条件host=102) #!/bin/bash #1 获取输入参数个数,如果没有参数,直接退出 pcount=$# if ((pcount==0)); then echo no args; exit; fi #2 获取文件名称 p1=$1 fname=`basename $p1` echo fname=$fname #3 获取上级目录到绝对路径 pdir=`cd -P $(dirname $p1); pwd` echo pdir=$pdir #4 获取当前用户名称 user=`whoami` #5 循环 for((host=102; host<103; host++)); do echo ------------------- hadoop$host -------------- rsync -av $pdir/$fname $user@hadoop$host:$pdir done 4.编写成功后,赋予最高权限,启用脚本 [root@hadoop101 bin]# chmod 777 xsync [root@hadoop101 bin]# xsync /etc/profile下面你会输入两次密码,然后出现这样的结果
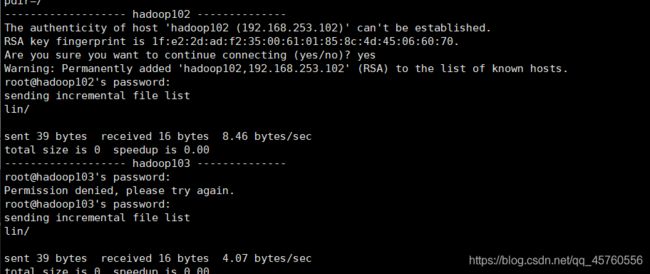
这样,分发脚本就写好啦.
-
集群配置
-
下面是配置的结构图
hadoop101 hadoop102 hadoop103 HDFS NameNode DataNode DataNode SecondaryNameNode DataNode YARN NodeManager ResourceManager NodeManager NodeManager 根据这个,我们开始进行集群的配置
-
配置集群
-
配置core-site.xml
1. 1.打开hadoop文件夹下的etc/hadoop [root@hadoop101 etc]# cd /opt/module/hadoop-2.7.2/etc/hadoop/ 2.配置core-site.xml [root@hadoop101 hadoop]# vim core-site.xml 在最后一行和倒数第二行的中间输入如下内容fs.defaultFS hdfs://hadoop102:9000 hadoop.tmp.dir /opt/module/hadoop-2.7.2/data/tmp -
配置HDFS
-
配置hadoop-env.sh
[root@hadoop101 hadoop]# vim hadoop-env.sh
#添加以下内容
export JAVA_HOME=/opt/module/jdk1.8.0_144

-
配置hdfs-site.xml
[root@hadoop101 hadoop]# vim hdfs-site.xml
跟配置core-site.xml一样,在指定位置插入
dfs.replication
3
dfs.namenode.secondary.http-address
hadoop103:50090
-
-
配置均衡管理框架Yarn
-
配置yarn-env.sh
相同的
[root@hadoop101 hadoop]# vim yarn-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_144

-
配置yarn-site.xml
[root@hadoop101 hadoop]# vim yarn-site.xml
添加如下内容
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.hostname
hadoop102
-
-
配置MapReduce
-
配置mapred-env.sh
[root@hadoop101 hadoop]# vim mapred-env.shexport JAVA_HOME=/opt/module/jdk1.8.0_144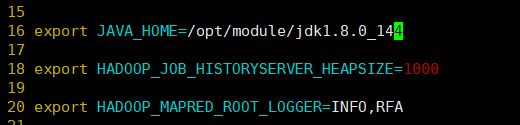
-
配置mapred-site.xml
先将文件名字修改一下
[root@hadoop101 hadoop]# cp mapred-site.xml.template mapred-site.xml
在文件中增加
mapreduce.framework.name yarn
-
-
配置完成,将hadoop分发出去
[root@hadoop101 module]# xsync /opt/module/hadoop-2.7.2/
查看分发情况
[root@hadoop102 module]# cat /opt/module/hadoop-2.7.2/etc/hadoop/core-site.xml
-
-
-
集群单点启动
这里不建议启动,后面群起还要初始化一次,就会出现问题,所以这一步就不进行讲解了.
-
SSH 无秘登陆配置
-
SSH:SSH 为建立在应用层基础上的安全协议。SSH 是较可靠,专为远程登录会话和其他网络服务提供安全性的协议。
-
SSH使用的是非对称加密算法:
即: 1.A要向B发送信息,A和B都要产生一对用于加密和解密的公钥和私钥 2.A的私钥保密,A的公钥告诉B;B的私钥保密,B的公钥告诉A。 3.A要给B发送信息时,A用B的公钥加密信息,因为A知道B的公钥。 4.A将这个消息发给B(已经用B的公钥加密消息)。 5.B收到这个消息后,B用自己的私钥解密A的消息。其他所有收到这个报文的人都无法解密,因为只有B才有B的私钥。 -
配置无密登录
1.生成秘钥 [root@hadoop101 hadoop]# ssh-keygen -t rsa 三次回车,就会生成两个文件id_rsa(私钥)、id_rsa.pub(公钥) 2.将公钥拷贝到要免密登录的目标机器上(在这里我的虚拟机是hadoop101,102,103,每台虚拟机都需要进行相应的操作) [root@hadoop101 hadoop]# ssh-copy-id hadoop101 [root@hadoop101 hadoop]# ssh-copy-id hadoop102 [root@hadoop101 hadoop]# ssh-copy-id hadoop103 3.完成后,测试一下,在hadoop102上输入 [root@hadoop102 hadoop]# ssh hadoop101 这个时候就会转到hadoop101了,成功完成配置.ssh文件夹下(~/.ssh)的文件功能解释
表2-4
known_hosts 记录ssh访问过计算机的公钥(public key) id_rsa 生成的私钥 id_rsa.pub 生成的公钥 authorized_keys 存放授权过得无密登录服务器公钥
-
-
群起集群
现在到了,搭建的最后,同样也是很重要的一步。
-
配置slaves
1.进入 hadoop下: [root@hadoop101 hadoop]# cd /opt/module/hadoop-2.7.2/etc/hadoop 2.编辑文件 [root@hadoop101 hadoop]# vim slaves 3.添加一下内容(注意:该文件中添加的内容结尾不允许有空格,文件中不允许有空行。将localhost 删除) hadoop101 hadoop102 hadoop103 4.同步到另外的虚拟机 [root@hadoop101 hadoop]# xsync slaves -
启动集群
-
如果集群是第一次启动,需要格式化NameNode(注意格式化之前,一定要先停止上次启动的所有namenode和datanode进程,然后再删除data和log数据)
[root@hadoop101 hadoop-2.7.2]# bin/hdfs namenode -format
-
启动HDFS
[root@hadoop101 hadoop-2.7.2]# sbin/start-dfs.sh [root@hadoop101 hadoop-2.7.2]# jps 5029 NameNode 5420 Jps 5135 DataNode [root@hadoop102 hadoop]# jps 4792 DataNode 4891 Jps [root@hadoop103 module]# jps 4865 DataNode 4946 SecondaryNameNode 5046 Jps
-
-
启动YARN
[root@hadoop102 hadoop]# sbin/start-yarn.sh
注意:NameNode和ResourceManger如果不是同一台机器,不能在NameNode上启动 YARN,应该在ResouceManager所在的机器上启动YARN。
启动成功后 ,看看自己是不是配置好了
-
查看
在浏览器中输入
hadoop101:50070
点击Datanodes
·
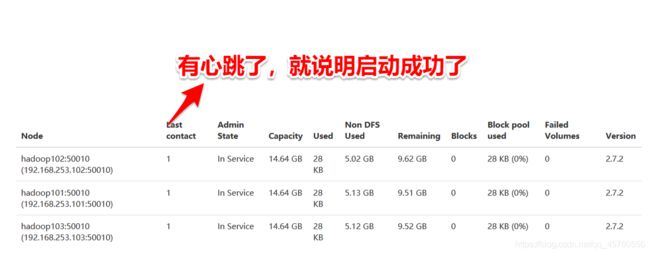
如图所示,启动就成功了
-
-
集群测试
在这里,我们用官方Wordcount案例来进行测试
1.在 hadoop-2.7.2下创建一个wcinput [root@hadoop101 hadoop-2.7.2]# mkdir wcinput 2.在wcinput文件下创建一个wc.input文件 [root@hadoop101 hadoop-2.7.2]# cd wcinput [root@hadoop101 hadoop-2.7.2]# touch wc.input 3.编辑wc.input文件 [root@hadoop101 hadoop-2.7.2]# vim wc.input 在文件中输入下面的内容: hadoop yarn hadoop mapreduce atguigu atguigu 4.回到hadoop-2.7.2下,紧接着将cinput上传 [root@hadoop101 hadoop-2.7.2]# hadoop fs -put wcinput / 这个时候打开你的hadoop101.50070,效果如图1 5.开始执行程序 [root@hadoop101 hadoop-2.7.2]# hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /wcinput /wcountput 网页刷新一下 就可以看见多了内容,如图2
-

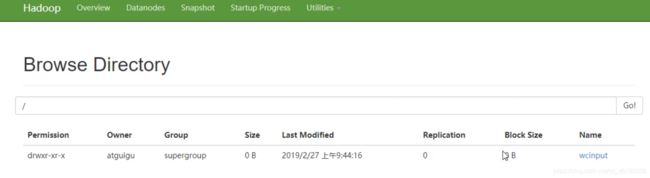 图1
图1
 图2
图2
-
开启历史服务器、日志聚集
为了查看程序的历史运行情况,我们需要配置历史服务器还有日志聚集
1.在配置之前,需要关闭我们的HDFS(在hadoop101中关闭)、还有我们的YARN(在hadoop102中关闭) [root@hadoop101 hadoop]# stop-dfs.sh [root@hadoop102 hadoop-2.7.2]# stop-yarn.sh 2.配置mapred-site.xml [root@hadoop101 hadoop-2.7.2]# vim mapred-site.xml 在里面增加如下配置mapreduce.jobhistory.address hadoop103:10020 mapreduce.jobhistory.webapp.address hadoop103:19888 yarn.log-aggregation-enable true yarn.log-aggregation.retain-seconds 604800 -
集群启动/停止方式总结
- 各个服务组件逐一启动/停止
(1)分别启动/停止HDFS组件
hadoop-daemon.sh start / stop namenode / datanode / secondarynamenode
(2)启动/停止YARN
yarn-daemon.sh start / stop resourcemanager / nodemanager
- 各个模块分开启动/停止(配置ssh是前提)常用
(1)整体启动/停止HDFS
start-dfs.sh / stop-dfs.sh
(2)整体启动/停止YARN
start-yarn.sh / stop-yarn.sh
-
集群时间同步:
-
时间同步的方式:找一个机器,作为时间服务器,所有的机器与这台集群时间进行定时的同步,比如,每隔十分钟,同步一次时间。
-
操作
1.检查ntp是否安装 [root@hadoop101 ~]# rpm -qa|grep ntp ntp-4.2.6p5-10.el6.centos.x86_64 fontpackages-filesystem-1.41-1.1.el6.noarch ntpdate-4.2.6p5-10.el6.centos.x86_64 2.修改ntp配置文件 (1)将#去掉 #restrict 192.168.1.0 mask 255.255.255.0 nomodify notrap为 restrict 192.168.1.0 mask 255.255.255.0 nomodify notrap (2)将#加上 server 0.centos.pool.ntp.org iburst server 1.centos.pool.ntp.org iburst server 2.centos.pool.ntp.org iburst server 3.centos.pool.ntp.org iburst为 #server 0.centos.pool.ntp.org iburst #server 1.centos.pool.ntp.org iburst #server 2.centos.pool.ntp.org iburst #server 3.centos.pool.ntp.org iburst (3)当该节点丢失网络连接,依然可以采用本地时间作为时间服务器为集群中的其他节点提供时间同步 server 127.127.1.0 fudge 127.127.1.0 stratum 10 3.修改/etc/sysconfig/ntpd 文件 [root@hadoop101 ~]# vim /etc/sysconfig/ntpd 增加内容如下(让硬件时间与系统时间一起同步) SYNC_HWCLOCK=yes 4.重新启动ntpd服务 [root@hadoop101 ~]# service ntpd start 5.设置ntpd服务开机启动 [root@hadoop101 ~]# chkconfig ntpd on 6.在另外两台虚拟机上配置: (1)在其他机器配置10分钟与时间服务器同步一次 [root@hadoop102 ~]# crontab -e [root@hadoop103 ~]# crontab -e 编写定时任务如下 */10 * * * * /usr/sbin/ntpdate hadoop101 配置完成到此,完全分布式运行模式就结束了,集群也就搭建好了.
-