从零开始的Node.js新闻爬虫实验项目(四)东方财富网、网易新闻、Pixiv的爬取思路
这是计划的第3步
有了前篇雪球网新闻的爬取代码,可以同样的爬取其他各类网站
1)东方财富网
1、一级页面
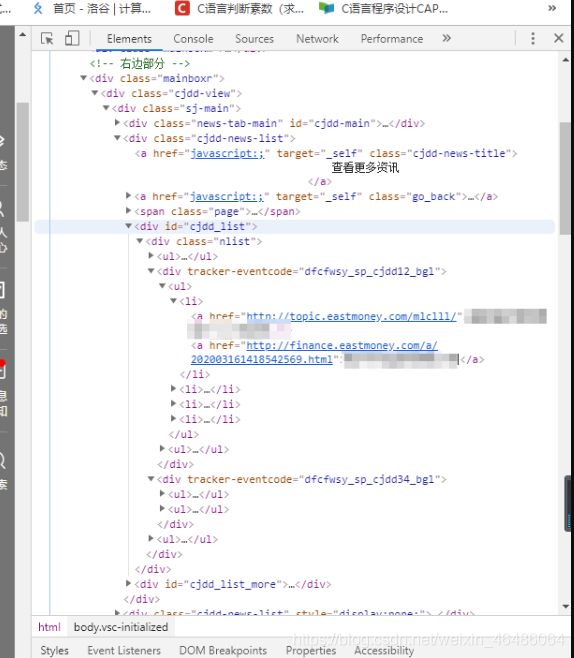
在这里,选择信息较为集中,内容丰富的“右边部分”开始分析。
观察到每一条消息均在各自的 li 项下的 a 中,于是主体部分非常好写
var item = $('.nlist', 'div').find('li').children('a')
item.map(function (idx, element) {
var news = {
};
news.title = $(element).text();
news.link = $(element).attr('href');
console.log(news);
})

输出非常漂亮
2、二级页面

可以看到,我们感兴趣的内容均在class=“newsContent”下,可以分类爬取信息,爬取二级地址内容的代码如下:
rp(options).then(function ($) {
var item = $('.newsContent', 'div');
news.time = item.find('.time', 'div').first().text();
news.editor = item.find('.author', 'div').first().text();
news.source = item.find('.source', 'div').text();
var source = news.source;
news.source = source.replace(/\s*/g, '');
news.comment = item.find('.num', 'span').text();
news.contain = item.find('.b-review', 'div').text();
var maintext = '';
$('.newsContent', 'div').find('.Body', 'div').children('p').each(function (idx, element) {
maintext = maintext.concat($(element).text());
})
news['texts'] = maintext;
console.log(news);
})
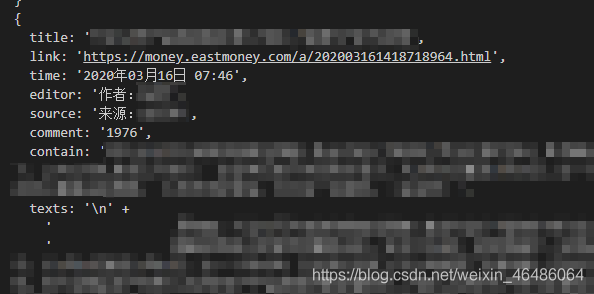
绝大部分网页可以正确爬取,部分网页链接至其他网站,故html结构有所不同,不做考虑。
2)网易新闻
1、一级页面

注意,该网站采用的是GBK编码,需要使用iconv-lite转码,与此同时,options中将encoding设置为null,如下
var options = {
uri: 'https://news.163.com',
encoding: null,
transform: function (body) {
body = iconv.decode(body, 'gbk');
return cheerio.load(body);
}
}
var item = $('.mod_top_news2', 'div').find('li');
item.map(function (idx, element) {
var news = {
};
news.title = $(element).find('a').text();
news.link = $(element).find('a').attr('href');
console.log(news);
})
使用类似的办法,同样爬取出标题和二级页面url
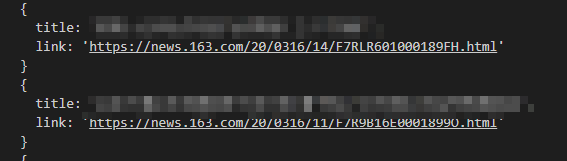
2、二级页面

简明扼要;非常好处理
rp(options).then(function ($) {
var item = $('.post_content_main', 'div');
news.time = item.find('.post_time_source', 'div').text().slice(0, 36).replace(/\s*/g, '');
news.editor = item.find('.ep-editor', 'span').text();
news.source = item.find('.post_time_source', 'div').children('a').first().text();
news.comment = item.find('.post_cnum_tie', 'a').text();
var maintext = '';
$('.post_text', 'div').children('p').each(function (idx, element) {
maintext = maintext.concat($(element).text()).replace(/\s*/g, '');
})
news['texts'] = maintext;
console.log(news);
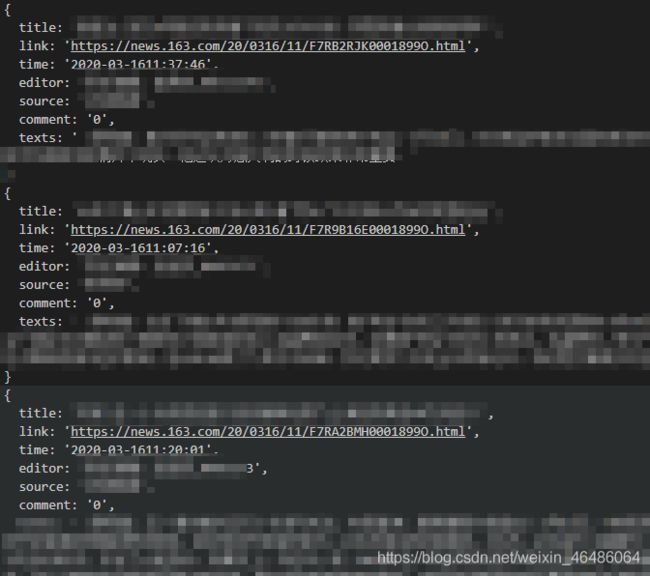
吐槽一下用了两次去除字符串中的空字符的方法 .replace(/\s*/g, ‘’)
3)Pixiv
1、一级页面
Pixiv是一个图片网站,这里不再对主页进行爬取,而是直接对某个关键词的搜索页进行爬取
https://www.pixiv.net/tags/比那名居天子/artworks?s_mode=s_tag
我们随机挑一个关键词进行搜索,可以看见url的组成方式非常简单,可以直接利用字符串操作
在这里插入图片描述
同样是每张图片都在各自 class=sc-prOVx jMjpVy 中

然而事与愿违,这是因为Pixiv是需要代理的。同时,pixiv需要登录才能使用会员搜索等功能。
a. 使request使用代理
首先安装ss5代理需要的模块
npm install socks5-https-client
然后你需要一个可以使用的 socks 代理,并且先测试一下代理是否能生效,首先选取登录界面的一段文字尝试爬取
var cheerio = require('cheerio')
var rp = require('request-promise')
var Agent = require('socks5-https-client/lib/Agent');
var headers = {
"Content-Type": "application/x-www-form-urlencoded; charset=UTF-8",
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.65 Safari/537.36'
}
var options = {
strictSSL: true,
agentClass: Agent,
agentOptions: {
socksHost: '*.*.*.*', //代理的IP或者域名!
socksPort: *, //代理的端口!
socksUsername: '*', //代理的用户名!
socksPassword: '*' //该用户的密码!
},
uri:'https://www.pixiv.net/',
headers: headers,
transform: function (body) {
return cheerio.load(body);
}
}
rp(options).then(function ($) {
console.log('Tip: ' + $('.signup-form__catchphrase', 'div').text());
})
![]()
代理成功生效!
b. 对某个搜索结果的爬取
uri: encodeURI('https://www.pixiv.net/tags/'+tag),
首先,我们写的tag都是汉字形式,需要利用 encodeURI 函数转化为UTF-8格式
console.log($('body').html());
![]()
然而,在获取整个 body 的时候,发现里面的内容是空的。如果用浏览器直接打开这个页面,会发现内容是分步骤加载的,也就是动态加载的,直接request页面,是缺少了很多信息的。

打开控制台的 Network ,选择 XMR ,可以发现网站向四个不同的url发送了请求。在一个个尝试之后,发现其中一个页面: https://www.pixiv.net/ajax/search/top/比那名居天子 是如下json内容:

通过敏锐的嗅觉不难发现,选中的 “id”:“80511208”正是搜索结果中的图片的ID,实际打开之后也确实如此,于是我们改为爬取 “https://www.pixiv.net/ajax/search/top/ + tag” 的内容。
这里另外找到了一个json更加简洁的页面 “https://www.pixiv.net/ajax/search/manga/” + tag + “?word=” + tag + “&order=date_d&mode=all&p=1&s_mode=s_tag_full&type=manga”

丢到 https://www.bejson.com/ 上去格式化一下,可以看见每个id都在“data”内每个对象中的“id”属性内。
rp(options).then(function ($) {
var str = $('body').html(); //将body中的json内容转换为字符串
str = str.replace(/"/g,'"'); //json中的所有引号都显示为了",在此处替换回来
var json = JSON.parse(str); //将字符串转换为json对象
var data = json.body.manga.data; //每个对象内存着一个id的data数组
for(var element in data)
{
console.log(data[element].id); //遍历data数组内的所有对象的id
}
})

id就顺利的都爬取了下来
c. 爬取每个id下的图片
容易发现,每个ID下的图片均为 “https://www.pixiv.net/artworks/” + id
同样地,该网站也是动态加载的,并且在XHR中难以找到图片对应的url,不过,我们可以观察到每一张图片的命名规律:
https://i.pximg.net/img-original/img/2020/02/08/19/09/08/79355941_p0.png
主要信息为日期、时间和id,重新检查上图中的json文件,可以看到这些信息都有很好地保存。
for(var element in data){
var id = data[element].id;
var url = data[element].url;
if (url!=undefined) {
url = url.replace(/c\/250x250_80_a2\/img-master/g,'img-original');
url = url.replace(/_square1200.jpg/g,'.png');
console.log(url);
}
}

图片的地址已经正确的爬取下来了,然而网站直接打开是403,这是因为服务器还验证了用户是从哪个页面转来的,即下图中的referer。

headers: {
'referer': 'http://www.pixiv.net/member_illust.php?mode=big&illust_id=' + id,
"Content-Type": "application/x-www-form-urlencoded; charset=UTF-8",
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.75 Safari/537.36'
},
在headers中加上了referer之后,便不报403了
var writeStream = fs.createWriteStream('image.png');
var readStream = request(ne_options);
readStream.pipe(writeStream);
writeStream.on("finish", function() {
console.log("下载成功!!");
writeStream.end();
});
//临时加上一段通过request下载图片的代码

图片下载成功了,从文件夹打开之后,也发现图片可以正常显示。
d. 使各种格式的图片都能正确下载,优化下载体验
网站上的大部分图片都有JPG和PNG两种格式的URL,但是部分图片只含其中一种。这里的笨办法是两种后缀URL都进行访问,通过判断返回的状态码是否是404,来判断URL是否有效
function download(Jpg_options, Png_options, id) {
request(Jpg_options, function (error, response, body) {
var now_options = Jpg_options;
if(response.statusCode!=404) {
var name = id + '_0.jpg';
var writeStream = fs.createWriteStream("./images/"+name);
var readStream = request(now_options);
readStream.pipe(writeStream);
writeStream.on("finish", function() {
downloading++;
console.log("第 " + downloading + '/' + downloadAmount + " 张下载成功!");
writeStream.end();
});
}
else{
request(Png_options, function (error, response, body) {
var now_options = Png_options;
if(response.statusCode!=404) {
var name = id + '_0.png';
var writeStream = fs.createWriteStream("./images/"+name);
var readStream = request(now_options);
readStream.pipe(writeStream);
writeStream.on("finish", function() {
downloading++;
console.log("第 " + downloading + '/' + downloadAmount + " 张下载成功!");
writeStream.end();
});
}
});
}
});
}
通过简单地if判断来进行下载,Png_options 和 Jpg_options 分别含有这两种后缀的url
function finishDownload() {
//console.log(listArr);
var finallist=JSON.stringify(listArr, '', '\t');
fs.writeFileSync("./images/list.json", finallist);
console.log('全部下载完毕!共抓取到 ' + total + " 张,计划下载 " + downloadAmount + " 张,其中 " + downloaded + " 张已存在,下载成功 " + success + " 张,下载失败 " + fail + " 张。");
if(fail>0) {
console.log('下载失败:' + fails);
}
process.exit();
}
将结束下载重构为函数,并且添加一个文件,用来存储所有下载过的图片的id,以免重复下载图片。同时加入几个变量,用于记录抓取总数、下载计划数、已下载数、下载成功数和下载失败数。最后输出如下:

下载失败的原因可能是链接已失效。完整代码在:
https://github.com/AquariusAQ/Web-Crawler-in-Node.js