python网络爬虫入门 —— 学习笔记(1)
以下内容来自:python网络采集和python爬虫入门课程。
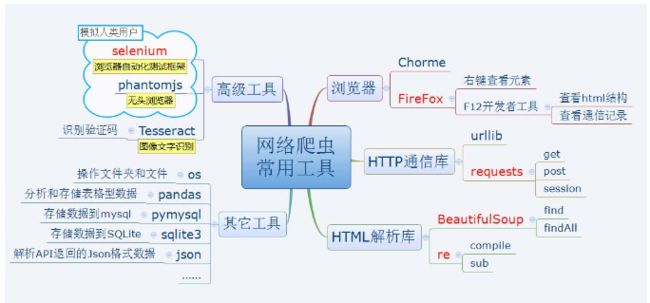
1. 网络采集工具
参考学习链接:
视频链接(两个免费课程很好): https://study.163.com/courses-search?keyword=%E7%BD%91%E7%BB%9C%E7%88%AC%E8%99%AB
requests库: https://requests.readthedocs.io/zh_CN/latest/
BeautifulSoup库: https://beautifulsoup.readthedocs.io/zh_CN/v4.4.0/
正则表达式: https://www.runoob.com/regexp/regexp-tutorial.html
selenium库: https://python-selenium-zh.readthedocs.io/zh_CN/latest/2.%E5%BC%80%E5%A7%8B/#_2


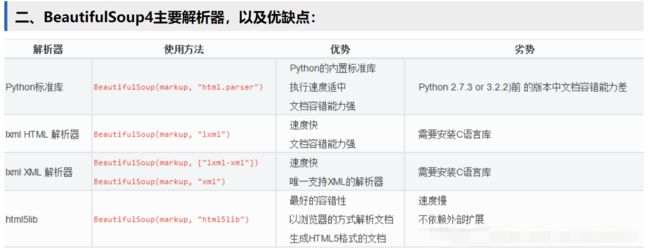
Beautiful Soup将复杂HTML文档转换成一个复杂的树形结构,每个节点都是Python对象,所有对象可以归纳为4种:
- Tag 标签对象
- NavigableString 用来查找 HTML 文档的注释标签,
- BeautifulSoup 对象表示的是一个文档的全部内容
- Comment 用来表示标签里的文字。
from urllib.request import urlopen
from bs4 import BeautifulSoup
html = urlopen('http://www.pythonscraping.com/pages/warandpeace.html')
"""
bs对象 = BeautifulSoup(要解析的文本,‘解析器’)
注意:
1.括号里面第0个参数是被解析的文本,必须是字符串
2.括号里第1个参数用来标识解析器,使用python内置库,html.parser
解
"""
bs = BeautifulSoup(html, 'html.parser')
print(bs)

2. 常用的两个函数
第一种方法: select函数是通过css查找,可参考链接select函数用法
第二种方法: 使用find函数,通过html的节点关系查找。
find_all(tag, attributes, recursive, text, limit, keywords):取出的是所有满足要求的数据。
find(tag, attributes, recursive, text, keywords):只提取首个满足要求的数据。
1、标签参数 tag
2、属性参数 attributes 是用一个 Python 字典封装一个标签的若干属性和对应的属性值。
3、递归参数 recursive 是一个布尔变量。你想抓取 HTML 文档标签结构里多少层的信息?如果 recursive 设置为 True ,findAll 就会根据你的要求去查找标签参数的所有子标签,以及子标签的子标签。如果 recursive 设置为 False ,findAll 就只查找文档的一级标签。findAll 默认是支持递归查找的(recursive 默认值是 True );一般情况下这个参数不需要设置,除非你真正了解自己需要哪些信息,而且抓取速度非常重要,那时你可以设置递归参数。
4、文本参数 text 有点不同,它是用标签的文本内容去匹配,而不是用标签的属性。
5、关键字
get_text() 会把你正在处理的 HTML 文档中所有的标签都清除,然后返回一个只包含文字的字符串。假如你正在处理一个包含许多超链接、段落和标签的大段源代码,那么get_text() 会把这些超链接、段落和标签都清除掉,只剩下一串不带标签的文字。
2.1 使用标签和属性
import requests
from bs4 import BeautifulSoup
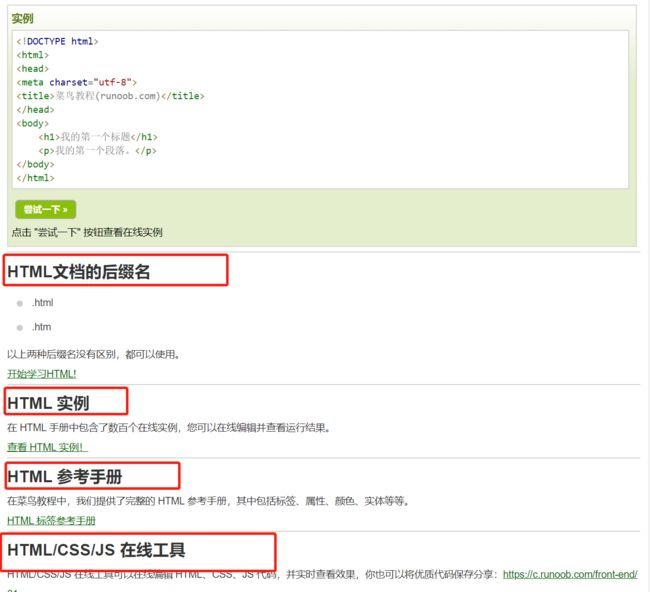
res=requests.get("https://www.runoob.com/html/html-tutorial.html")
#查看编码方式 :res.encoding----'UTF-8'
#也可以按网页本身自动编码
html=res.text.encode(res.encoding).decode()
soup=BeautifulSoup(html,'lxml')
print(soup)
#使用标签
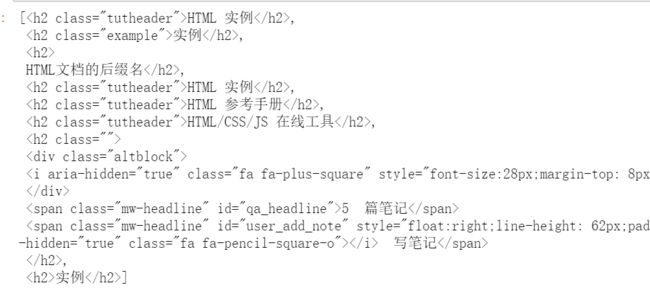
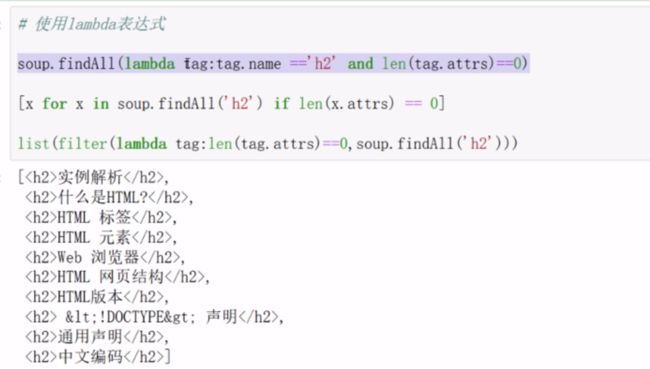
soup.findAll(name={
'h1','h2','h3','h4'})#获取一级标题,二级标题,。。。

len(soup.body.findAll('div',recursive=False)) #3个分区

#使用属性
divs=soup.findAll('div',attrs={
'class':'article'})
divs[0].findAll('h2')
2.2. 使用关键字和文本
#使用文本
import re
#查看以html开头的信息,限制在标题类中
soup.findAll({
'h1','h2','h3','h4'},text=re.compile("^HTML"))

#使用关键字
#因为class是关键字,为避免冲突,此处需要添加下划线
soup.findAll(class_={
'article'})
#**kwarg参数和attrs参数可以互相替代
soup.findAll('div',id={
'footer'})
#1.各个子标题
titles = bs.find_all(['h1', 'h2','h3','h4','h5','h6'])
print([title for title in titles])
#2.在span限制下,查找关键字class为{'green', 'red'}
allText = bs.find_all('span', {
'class':{
'green', 'red'}})
print([text for text in allText])
#4查找文本the prince
nameList = bs.find_all(text='the prince')
print(len(nameList))
#5查找id为text
allText = bsObj.findAll(id="text")
print(allText[0].get_text())
3. 导航树


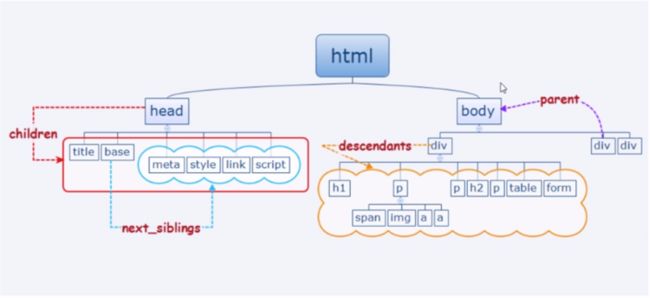

1.处理子标签和其他后代标签
在 BeautifulSoup 库里,孩子 (child)和后代 (descendant)有显著的不同:和人类的家谱一样,子标签就是一个父标签的下一级,而后代标签是指一个父标签下面所有级别的标签。例
如,tr 标签是 table 标签的子标签,而 tr 、th 、td 、img 和 span 标签都是 table 标签的后代标签(我们的示例页面中就是如此)。所有的子标签都是后代标签,但不是所有的后代标签都是子标
签。
2. 处理兄弟标签
BeautifulSoup 的 next_siblings() 函数可以让收集表格数据成为简单的事情,尤其是处理带标题行的表格,可以选择表格中除了标题行以外的所有行。
3. 父标签处理
from urllib.request import urlopen
from bs4 import BeautifulSoup
html = urlopen('http://www.pythonscraping.com/pages/page3.html')
bs = BeautifulSoup(html, 'html.parser')
print(bs.find('img',
{
'src':'../img/gifts/img1.jpg'})
.parent.previous_sibling.get_text())

4. 正则表达式


如果我们想抓取所有图片的 URL 链接,非常直接的做法就是用 findAll(“img”) 抓取所有图片,对吗?
但是,有个问题。除了那些明显“多余的”图片(比如,LOGO)之外,新式的网站里都有一些隐藏图片,用于网页布局留白和元素对齐的空白图片,以及一些不容易察觉到的图片标签。总之,你不能仅用商品图片来统计网页上所有的图片。而且网页的布局也可能会变化,或者,因为某些原因,我们不想通过图片在网页中的位置来查找标签。那么当你想抓取随机分布在网站里的某个元素或数据时,就会出现问题。例如,一些网页的最上面可能有一张商品图片,但是在另一些网页上没有。
解决这类问题的办法,就是直接定位那些标签来查找信息。在本例中,我们直接通过商品图片的文件路径来查找:
from urllib.request import urlopen
from bs4 import BeautifulSoup
import re
html = urlopen('http://www.pythonscraping.com/pages/page3.html')
bs = BeautifulSoup(html, 'html.parser')
images = bs.find_all('img', {
'src':re.compile('\.\.\/img\/gifts\/img[0-9]+\.jpg')})
for image in images:
print(image['src'])
