最近,加州大学伯克利分校和谷歌的科研团队共同提出了一个概念上非常简单,但是功能很强大的骨架网络,该网络将自注意力机制纳入了各种计算机视觉任务,包括图像分类、目标检测和实例分割,指标都有了很大的提升,该网络叫做 BoTNet(Bottleneck Transformer)。
为什么要使用 BoTNet?设计思想
近年来,卷积骨架网络在计算机视觉的各个领域取得了非常大的进展,这得益于卷积能够有效捕捉图像中局部的信息,但是对于实例分割、目标检测和关键点检测之类的视觉任务,需要对长期的依赖进行建模。
一、为什么要引入注意力机制?传统基于卷积的体系结构,需要堆叠很多个卷积层,以全局汇总捕捉局部信息的计算结果。尽管堆叠更多的层可能能够提高这些骨架网络的性能,但是显式的对全局依赖性进行建模可能是一种更强大且更具扩展性的解决方案。
二、为什么不全部替换成注意力机制?目标检测领域的输入图像(1024像素)相比于图像分类(224像素)来说非常大。而对于自注意力机制,消耗的显存和计算量与输入的大小成4倍增长,导致训练和测试效率太低,不切实际。
因此,作者提出利用自注意力机制来替换 ResNet 的最后三个 BottleNeck Layer ,这样的结构,使用卷积提取图像中局部的信息,然后利用自注意力机制来对全局的依赖性进行建模,能够解决上述的两个问题。

网络设计

Bottleneck Transformer
该所提方法基于ResNet网络,与ResNet的唯一区别,是在 c5 中,将 3×3 卷积替换成了 MHSA(Multi-Head Self Attention)结构。可以看到,参数量相比于ResNet减少了18.4%,加乘操作的数量增加了20%。

实验部分
作者在实例分割和目标检测上进行了实验。
相比ResNet,提升了COCO 实例分割上的性能

其中,R50 代表 ResNet-50。
相对的位置编码能够提升性能
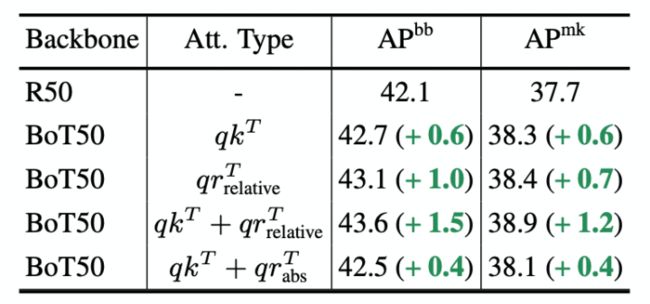
MHSA层中有两种交互:内容和内容的交互(qk^T),以及内容和位置的交互(qr^T)。而使用相对位置进行交互,带来的性能提升是非常明显的。
三个卷积都替换成 MHSA 吗?
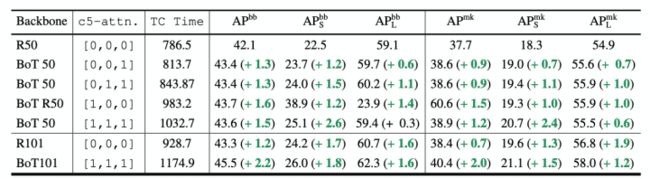
c5中有三个卷积层,作者进行消融实验,来看是否需要三个都替换成MHSA

结论是:三个卷积层全都替换,在小目标上效果非常好,但是大目标上效果就不太行了。作者说这可能是优化得不好,把这个留给了未来工作。
通过替换引入了全局依赖,那么性能是否与更深的卷积网络相当?
随着卷积网络的不断加深,更容易关注到全局的信息。而使用自注意力机制直接就关注的是全局的信息,所以说使用自注意力的网络不那么深,也能够达到类似的性能。作者通过实验也说明了这一点。
通过上表,我们可以看出,当配置是[0,1,1]时,BoT 50的效果要好于 R101的效果。
可以得出结论:替换为自注意力比卷积的堆叠更加有效。
BoTNet可以提升所有ResNet家族网络的性能
这里就是增加了152层的ResNet的结果,性能也有一定的提升。

除此之外,作者还进行了非常多详细的实验,有兴趣的可以参考原论文。
使用方式
这里官方都为我们实现好了,话不多说,直接上代码。这个实现方式是基于PyTorch的,基于TensorFlow的代码在最下面有。
安装
pip install bottleneck-transformer-pytorch使用
import torch
from torch import nn
from torchvision.models import resnet5
from bottleneck_transformer_pytorch import BottleStack
layer = BottleStack(
dim = 256, # 输入通道数
fmap_size = 56, # 对于imagenet 224 x 224的图,特征图大小为56 x 56
dim_out = 2048, # 输出通道数
proj_factor = 4, # 压缩通道的倍数,压缩后的通道数 = 输入通道数 / proj_factor
downsample = True, # 第一层是否下采样
heads = 4, # MHSA 的头数
dim_head = 128, # 每个头的维度,默认128维
rel_pos_emb = False, # 是否使用相对的位置嵌入
activation = nn.ReLU() # 激活函数
)
resnet = resnet50() # 定义ResNet模型
backbone = list(resnet.children())
# 修改ResNet模型的最后几层
model = nn.Sequential(
*backbone[:5],
layer,
nn.AdaptiveAvgPool2d((1, 1)),
nn.Flatten(1),
nn.Linear(2048, 1000)
)
# 使用 “BotNet”
img = torch.randn(2, 3, 224, 224)
preds = model(img) # (2, 1000)是否有开源预训练模型?
大家知道,训练注意力模型需要非常大的显存,原始论文是使用TPU进行训练的,但是很遗憾,目前并没有公开的预训练模型。
参考资料:
- 原始论文:https://arxiv.org/abs/2101.11605
- TensorFlow 1实现:https://gist.github.com/aravindsrinivas/56359b79f0ce4449bcb04ab4b56a57a2
- PyTorch实现:https://github.com/lucidrains/bottleneck-transformer-pytorch/blob/main/bottleneck_transformer_pytorch/bottleneck_transformer_pytorch.py
写在后面:关于BotNet的介绍就到这里了,如果觉得这篇文章对您有帮助,欢迎三连支持我,谢谢!
我的知乎:https://www.zhihu.com/people/...
我的公众号:算法小哥克里斯,欢迎来撩!