原创 侯龙

一个好的软件,功能和性能都至关重要,这当然离不开产品同学的开光脑瓜、研发同学的灵巧小手,也离不开测试同学的金晶火眼。说到测试,可能大家就会想到页面点点点呀,接口验证呀,业务联调呀等等,其实还有一个很重要的环节,那就是性能测试。
那么,什么是性能测试?如何衡量系统性能?系统响应时间是怎么计算的?如何进行性能调优?带着这些问题,咱们今天就来简单地聊一聊性能调优那些事儿。
1.性能测试是什么
性能测试就是通过特定的方式,对被测系统按照一定的测试策略施加压力,获取该系统的响应时间、吞吐量、资源利用率等性能指标,来检验系统上线后能否满足用户需求的过程,主要包括测试需求/目的、测试环境/工具、测试方案、测试执行、测试结果与分析。
2.衡量系统的四大指标
衡量一个系统的性能,主要有以下四大指标:
响应时间
指应用执行一个操作所需的时间,包括从发出请求开始到最后收到响应所需要的时间。响应时间是系统最重要的性能指标,直观的反映了系统的快慢。
吞吐量
指单位时间内系统处理的请求数,体现系统的整体处理能力。TPS(Transaction per second)是吞吐量的一个常用量化指标,此外还有HPS(Hits per second)、QPS(Query per second)等。
资源利用率
指应用服务器、数据库服务器及被测系统包含的中间件服务器的CPU、内存、磁盘、网络等系统资源的使用情况。
并发数
指的是同时提交请求的用户数目。这四个指标之间的关系如图1。
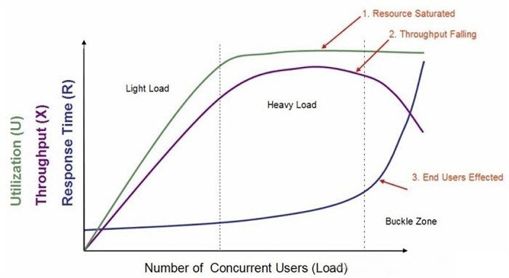
图1
吞吐量= 并发数/平均响应时间吞吐量= 并发数/平均响应时间。
从图1我们可以看到:
- 当系统压力较小时,响应时间几乎无变化,吞吐量和系统资源随并发数的增加呈线性增长趋势;
- 当系统压力较大时,随着并发数增加,响应时间也逐渐增加,系统资源达到极限,吞吐量不再增长;
- 继续增加并发数,响应时间快速增长,系统资源仍然在极限状态,吞吐量迅速下降。
一般情况下,我们希望系统能够支持更大的并发和更大的吞吐量。但是,从上面的分析我们可以看到,并发数的增长不会一直带来吞吐量的增长,因为系统资源使用率达到极限后,响应时间将会是决定吞吐量的更大因素,那么,时间都去哪儿了呢?
3.时间都去哪儿了
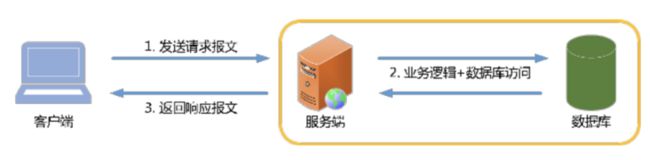
图2
一个请求从发出到接收响应,如图2所示。大致流程如下:
- 客户端发送请求报文。客户端发送请求报文,经过网络传输后到达服务端;
- 服务端处理。服务端接收到请求报文后,进行业务逻辑处理和必要的数据读写操作;
- 服务端返回响应报文。服务端处理完后,将响应报文发送到客户端。
我们通常说的响应时间是第1步、第2步、第3步消耗的总时间。第1步主要是客户端请求耗时和网络耗时;第2步主要是业务逻辑、数据读写和网络耗时;第3步主要是客户端渲染和网络耗时。
第1、2、3步每一步都有可能存在性能问题,导致响应时间变长。第1步中如客户端主机配置低,反应慢等,第二步中如业务线程阻塞、数据库查询慢;第3步中如网络传输延迟。根据各种问题的类型,我们又可以把问题归为硬件问题、网络问题、代码问题、中间件问题等。不同问题也有不同的调优方法,下面我们简单聊一聊性能调优。
4.抓住时间的小偷-性能调优
常用的调优方法有:
- 空间换时间。如数据缓存,提前从磁盘上读取数据缓存到内存中,CPU请求数据直接从内存中获取,从而达到更高的效率;
- 时间换空间,如上传大附件,将数据分批次处理,用更少的空间完成任务处理;
- 分而治之,把任务切分,分开执行,也方便并行执行来提高效率;
- 异步处理,如互联网应用最常见的MQ消息队列,将业务链路上比较耗时的业务拆分出来,通过异步处理减少阻塞影响;
- 并行,多个进程或者线程同时处理业务,缩短业务处理时间;
- 离用户更近一点,如CDN技术,把用户请求的静态资源放在离用户更近的地方;
- 一切可扩展,业务模块化、服务化(同时无状态化)、良好的水平扩展能力。
下面我们举几个案例进行说明。
案例1
问题描述:压测某接口时,随着压测执行,响应时间越来越长。
问题分析:
- 打印线程堆栈,对比线程堆栈信息,发现线程堆栈中FailoverEvent的线程数越来越多,最终内存溢出;
- 查看代码发现,程序中未判断FailoverEvent线程队列是否已经存在,导致FailoverEvent线程队列重复创建。
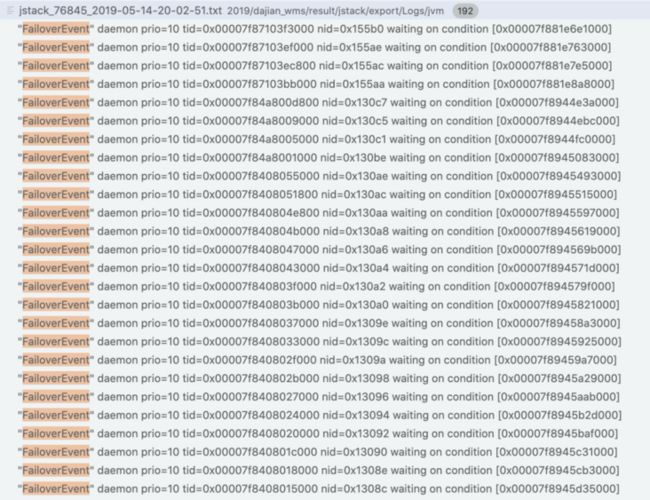
解决方案:创建FailoverEvent线程队列前,判断其是否存在,如果不存在则创建,如果存在,则使用现有对象。
优化结果:内存溢出问题解决,响应时间正常。
调优建议:
- 尽早释放无用对象的引用;
- 程序进行字符串处理时,尽量避免使用String,而应使用StringBuffer;
- 尽量少用静态变量;
- 避免集中创建对象尤其是大对象;
- 尽量运用对象池技术以提高系统性能;
- 不要在经常调用的方法中创建对象,尤其是忌讳在循环中创建对象。
案例2
问题描述:某批量处理接口,无积压的情况下,10000订单,4500sku种类处理时间耗时433秒。
问题分析:接口中采用单线程方式调用下游服务,查询次数=sku种类数/11,4500sku种类约410次,且每次调用耗时约519ms。
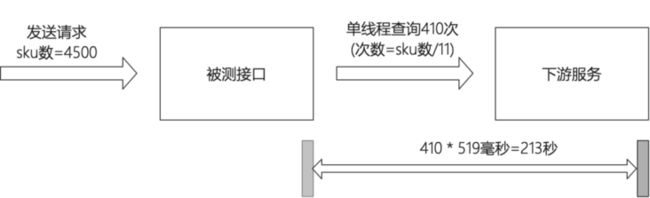
解决方案:调用下游服务改用多线程方式。

优化结果:TP99由212秒下降到33秒,TPS由87笔/秒提升到127笔/秒。
调优建议:本案例采用多线程降低了响应时间,但并不是说多线程一定比单线程快,因为干活的是CPU,不是线程。我们可以通过确认系统有无磁盘/网络IO来进行选择,有,多线程;无,单线程。并且采用多线程时,一定要使用线程池。
案例3
问题描述:数据查询接口,TP99=727ms,加大并发,吞吐量无法提升,应用服务器CPU使用率始终不到40%。
问题分析:通过调用链分析我们发现,一次请求,调用了11次selectList方法,导致接口总耗时飙升。

解决方案:去掉冗余调用,一次请求调用一次selectList方法。

优化结果:TP99由727ms下降到19ms,提升38倍,TPS由17.5笔/秒提升至163.4笔/秒,提升9倍。
调优建议:
- 设计先于代码;
- 基本原则:把数据库操作放在循环之外;
- 如果是查询,使用IN查询替换for循环(空间换时间);
- 如果是新增,使用批量插入。
案例4
问题描述:某接口提交数据库操作,更新数据时产生死锁。
问题分析:产生死锁的事务如表1:

解决方案:将事务1拆分,先查询,然后根据查询的结果批量删除。
优化结果:死锁问题解决。
调优建议:
- 避免大事务;
- 按同一顺序访问数据对;
- 避免编写包含用户交互的事务;
- 酌情使用低隔离级别,如RC;
- 为表添加合理的索引,如果不走索引将会为表的每一行记录加锁,死锁的概率就会大大增大;
- 避免在同一时间点运行多个对同一表进行读写的脚本,特别注意加锁且操作数据量比较大的语句;
- 设置锁等待超时参数,innodb_lock_wait_timeout。
5.总结
响应时间通常只是问题的表现,根本原因在于各种资源的利用是否合理,这里的资源是指广义的资源,包括硬件/软件资源、系统/线程/数据等不同级别的资源。调优本身,就是对各种资源进行更合理的配置。调优的目的通常也是为了满足业务需求,因此我们不必追求过早和过度优化,并且我们应该认识到,性能调优不可能一劳永逸,随着业务的迭代,总会有新的问题出现,因此我们应该具备打持久战的共识和能力。
推荐阅读
欢迎点击【京东科技】,了解开发者社区
更多精彩技术实践与独家干货解析
欢迎关注【京东科技开发者】公众号
