摘要:协议兼容问题、性能问题、数据备份问题、数据容量问题……这些都是数据库在使用过程中必然会遇见的问题。就好比选择结婚对象,你需要去对比不同的方面,最后选出最好的、最合适的。
本文分享自华为云社区《【云驻共创】Redis与计算存储分离四部曲:相识相惜,相辅相成》,原文作者:启明。
近期全国两会正在轰轰烈烈的召开,各人大代表也基于自己的一些实践提出了自己的意见,例如“出台手机设备适老标准”、“老师奖励不与升学率挂钩”、“提高留学生招生标准”等等。这些问题必不可少地引来了网上用户的各种讨论声音,你甚至可以想象出网上用户深夜在努力敲键盘的样子……
当然,我们今天来不是来讲全国两会的。我们技术人,技术魂,要讲的是这“网上讨论的声音”背后的技术——Redis。现如今我们网上聊天已经是家常便饭了,那么你有没有意识到,在我们聊天的背后,其实是有一个非常复杂的聊天系统的呢?在这复杂的聊天系统中的消息推送功能,更是其非常重要的一个模块。一般来说,消息推送,是采用Redis的历史数据结构来实现的。这个功能的简单运用,就是用户可以通过历史的顺序查找,实现查看历史消息的功能。
与Redis相遇
相信到这里,大家对Redis的功能强大已经有一定认知了。那么我们来正式介绍一下Redis:Redis(Remote Dictionary Server ),即远程字典服务,是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。Redis本身有三个优点:快、稳、准,也就是时延低、性能好、数据结构丰富。如此强大的Redis,是“电商秒杀”等业务场景中的“熟客”:将秒杀商品的库存数量存入Redis,通过Redis来提供一个全局库存的实时扣减和查询服务。
但是,没有任何技术是完美无瑕的,Redis亦如此。Redis本身有几个缺点:
- Redis的bgsave影响性能;
- Redis的集群管理的一致性非常弱;
- Redis的内存限制了它的存储容量
- Redis的内存利用率只有一半;
- Redis没有冷热分离机制。
以上都是Redis的一些缺点,是不是看完觉得Redis又被“拉下神坛”,不如不用了?不要放弃,针对开源Redis的这些缺点,华为云数据库团队,做了“亿点”努力!
与GaussDB(for Redis)相识
经过千难万险,千辛万苦,千锤百炼,华为云自研出了一款全新的Redis数据库,也即是GaussDB ( for Redis )!!!
华为云的自研Redis源自于GaussDB,采用了最先进的计算存储分离架构和多模架构——属于业界首创。而GaussDB,则是华为云数据库的亮点品牌,是华为云引以为傲的数据库架构。
针对华为云的GaussDB,我们来做一个简单的介绍吧(架构图如下):其是基于DFV架构来构建的。而DFV则是华为内部自研的超级DataLake(分布式存储池),可用于构建全栈数据服务架构,比如存储部分支持FusionStorage、云盘ECS、对象存储OBS,数据库部分支持的NoSQL、OLTP,大数据部分则支持HDFS的生态、Hadoop、Hbase、Hive等等。
通过下图可以看到,在上层的数据服务和下层的存储之间,是通过RDMA的高性能网络来连接,从而能够起到一个降低时延的作用。作为最底下的存储层,被分成了不同的存储介质,如SCM、NVMe SSD、HDD、众核/多核等等。不同的存储介质是用来满足不同的服务对于性能的不同的需求的。
这里可以看出,其实GaussDB NoSQL就是一套成熟的DFV架构,也是集华为整个公司的力量去构建的一个架构最后孵化出的一个产品。其背后的心血、可用性,以及价值,都是难以估量的。
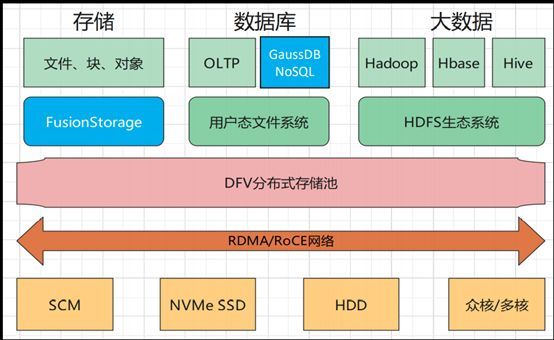
OK,我们再来看看NoSQL的“全家福”(见下图)。可以看到,下图已经囊括了NoSQL的全栈的数据库,包括Redis、Influx、Cassandra、Mongo在内,都是基于GaussDB相同的架构去实现的。
拆解来看,这整套架构分为三个层次,从上往下分别是:
- 服务层(Service Layer),主要负责数据库的协议的解析、处理、执行以及回包等等;
- 索引层(Index Layer),主要负责中间的路由及元数据管理等等;
- 持续化存储层(Persistent Layer),也即是DFV POOL。

当然,我们今天不会把每个部分都进行讲解,而是要对其中的Redis进行更深入的讲解,其所拥有的强一致、秒扩容、超可用、低成本这四个特点,让它成为了“家族中最靓的仔”。我们来一步步深入了解一下它吧。
与GaussDB (for Redis)相知
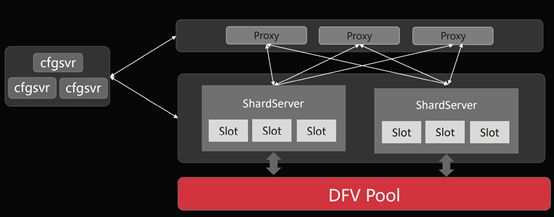
在对Redis的四个特性进行深一步讲解之前,我们先对GaussDB ( for Redis )有一个全面的认识吧。从架构设计上(见下图):
- 设计了中心化的咨询管理--ConfigureSever(cfgsvr):也就说用它来避免的就是社区Redis在集群管理上弱一致的一些问题;
- 设计了proxy的接入方式:让一些非class的用户通过这个proxy接入;
- 设计了Slot的数据管理:在最底层的ShardServer,设计Slot的数据管理。是说每一个项目Server会分别负责不同的Slot,每个Slot又对应不同的数据,最终的数据实际上都是落在最底层的分布式共享存储池(DFV POOL)上。
到这里,相信大家对GaussDB ( for Redis )的架构和性能已经有了一定的印象,那么我们便来详细介绍它的硬实力吧!
硬实力一:强一致
一提到“强一致”,很多业务开发人员会潜意识认为是一个比较高(fu)级(za)的技术,但是对他/她自身的业务逻辑,甚至他/她自身代码能力的提高,其实没有任何帮助。他们会说,“我不需要强一致啊”,或者,“强一致跟我没有关系”。
但我们听听业界大牛对此的看法:强一致不仅仅是一个技术需求,实际上它也是一个业务需求。我们如何去理解这句话呢?我们来举个栗子:三八妇女节刚刚过去,在这个无论大大小小的节日,都要被蹭一波流量的时代,当然少不了电商们的促销活动。电商们在做促销活动的时候,整个平台的流量是非常大的,但是整个系统能够抗住的压力又非常有限,这个矛盾要怎么解决呢?这里依赖的就是Redis的计数器,来构建的一个非常精巧的限流机制。
硬件不够,软件来凑。这是当代电商在承受非常大的并发流量的时候的一个基本手段。那么Redis在这其中是如何发挥作用的呢?我们来详细分析一下这个限流机制:在Redis里是有一个计数器的这么一个功能的。那么我们在运用过程中,会使用其中一个key来做限流。我们会首先对key做一个初始化的赋值,假设赋值1000。那么,当上层的业务调用API的时候,Redis的限流器就会做一个decrement的操作,即进行减1的一个操作。每次调用我们都会减1,直至key的值变为0,调用会暂停。等待一定的周期之后,系统会重新初始化key,而实现电商在固定周期内限制调用次数的功能。
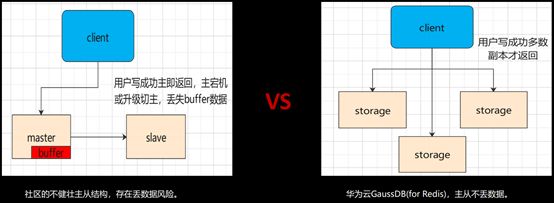
听着很美好是不是?但是在这个过程中,却会有一些“意外”发生,其中主从不一致是核心问题。
电商节当天的流量压力之大,不需要我们赘述。流量压力过大会引发的问题就是,”主”Redis的buffer会产生一定的堆积,如果再加上”主”Redis遇上宕机,就会导致”主”从发生切换。鉴于Redis的”主”从是异步的,一旦主从发生切换,那么之前在“主”上面做的decrement的操作将无法同步到“从”,最后导致“从”上的流控的数值比真实数值少了很多。但是切换过程,对于上层的调用接口来说,是没有感知的,它将继续尝试调用,即使实际已经decrement至0,限流器依然会通过它的请求,最后这些数据都会沉淀到最底层、最薄弱的MySQL数据库,最后导致整个系统的“雪崩”。
这时候,就是我们GaussDB ( for Redis )“强一致”功能出场的时候了。针对主从不一致的问题,GaussDB ( for Redis )在设计之初就是一个强一致的数据库,摒弃了开源社区的异步赋值机制。它被设计成在存储层(DFV层)去进行强一致的数据同步,而非在计算层。这样一来,在一开始便避免了任何中间态下的数据的不一致。妈妈再也不用担心我们宕机导致数据丢失啦~
硬实力二:秒扩容
我们以在疫情期间非常火热的在线教育为例。假设一个在线教育公司使用Redis作为存储介质。Key对应课程ID, Field对应用户ID。公司在设计之初可能没有考虑到疫情会给他们带来爆发式的用户增长,导致哈希膨胀,最后突破Redis所在节点的内存限制。那么针对疫情,他们必须要进行扩容。
可是扩容并不是一个简单的事情,甚至可以说是一个高危的操作。因为Redis的扩容,是阻塞式的,以key by key的方式去进行迁移,效率非常低下。扩容期间,key是不可访问的,并且会持续到扩容结束。
阻塞时间长是它的第一个问题。第二个问题更加严重。大家都知道,Redis不仅有主从,还有HA(哨兵)。一旦阻塞时间过长,你的主节点长期没有响应,HA就会判定你的主节点已经挂掉,然后把主节点“杀掉”,切换主从关系,让“从”接收请求。注意,这里的切换是发生在扩容迁移期间的,而一旦发生切换,就会导致扩容迁移失败,即扩容失败,最后导致哈希的数据一部分分布在源节点,另一部分分布在目标节点。这种现象即使是人工介入也很难修正。
我们来看看GaussDB ( for Redis )是怎么解决这个问题的。GaussDB ( for Redis ) 在设计的时候,借助了存算分离这样一个架构,把CPU和IO资源进行分池,从而实现按需扩容。 这样的话,在迁移的时候,就不需要把数据从一个节点拷贝到另一个节点,那么扩容过程就会变得更加轻量且安全。
计算存储分离的架构,是一个share everything的架构。架构底部共享存储,而基于共享存储,底层的Sever,可以“看”到整个集群的数据全集。当然,这里的看到整个数据全集,只是“看”而非能够“处理”,它只能通过Slot的路由器映射去决定它能够处理的那一部分。换句话说,当我们在做数据扩容和迁移的时候,只需要将前面所说的路由信息从源节点迁移到目标节点即可。轻量、安全、平滑,实现秒扩容。

硬实力三:超可用
在数据库领域,最可怕的事情,莫过于宕机。因为一旦宕机,那么鉴于数据在核心系统里,会导致整个业务系统都不可用,从而影响整个业务。因此,数据库必须解决可用性问题。
华为云数据库推出的可用性解决方案,实际上是比高可用更高,我们称之为“超可用”。它能够容忍N-1个节点挂掉,只要有一个节点活着,那么就能保障整个集群的可用性。
我们仍然以前面的在线教育为例。在线教育的公司会把课程和课程下的用户进行关联,这其中就组成了一个非常大的哈希结构。我们假设,在非常极端的情况下,此哈希所在分片的Master节点和Slave节点同时宕机,这肯定会影响用户的课程观看。在这种情况下,普通的Redis的集群的其他分片虽然看起来还是可用的,但是落到宕机的这个分片的所有请求,都不可用,因为它已经彻底挂掉了且是share nothing的架构,而其他节点也不会看到挂掉节点的数据。那么再来看华为云的GaussDB(for Redis)是怎么处理的。
鉴于它有共享存储的能力,也即share everything,它能过把分片上的路由信息,迁移到剩下的分片,并通过share everything能力看到挂掉分片的那部分数据,现在只需要一把“钥匙”,即可处理这部分数据。而这把“钥匙”就是其中一个Slot的路由信息:Slot的路由信息把宕机分片的信息迁移到“活着”的分片Sever上,最后“活着”的Sever就拥有打开整个集群的“钥匙”。这,就是超可用的设计。

硬实力四:低成本
技术再怎么硬,如果经济成本降本下来,基本是白费。假设我们有一个独角兽公司,它对Redis的依赖非常重:历史订单、地图定位、行程轨迹、用户特征、用户标签等等,都存储在Redis里。那么这里的数据量一定是非常大的,甚至可以达到100TB。那么这么大的一个规模,它里面的成本包括人工运维成本、机房建设、电力供应等等,将会达到千万级/年的数量级,这是非常惊人且非常难落地的。因此,降低成本成了必然的选择。
降低成本的第一步,是要看看成本都花在了什么上面。深入分析过后可以发现,其实这里面有一个“二八原则”。即80%的数据是冷数据, 80%的业务对时延性要求没有那么高。基于这样的分析,就会发现我们只要利用好“二八原则”,节省成本并不是什么难事。
华为云GaussDB(for Redis)利用以下几个方式,用有限的预算给用户提供了无限的可能性:
- 冷热分离,自动交换
- 无备节点,资源省半
- 进程无fork,内存无半折
- 异步压/解,兼顾逻辑核物理算法

与GaussDB(for Redis)相惜
为什么选择华为云GaussDB (for Redis)呢?除了上述我们要记住的四个特性(强一致、秒扩容、超可用、低成本)之外,我们还可以从别的地方来看出它的独特性。具体可见下图。

协议兼容问题、性能问题、数据备份问题、数据容量问题……这些都是数据库在使用过程中必然会遇见的问题。就好比选择结婚对象,你需要去对比不同的方面,最后选出最好的、最合适的。
作为核心数据的存储工具,选对就是商业成功的一半。当Redis遇见计算存储分离,华为云GaussDB(for Redis)为此而生。
本文整理自华为云社区内容共创活动第二期之【线上直播】当Redis遇见计算存储分离。
查看活动详情:https://bbs.huaweicloud.com/forum/thread-111494-1-1.html