内容导读 AdaptDL 是一个资源自适应深度学习训练和调度框架,是 CASL 开源项目的一部分。AdaptDL 的目标是使分布式 DL 在动态资源环境中变得简单和高效。
本文首发自微信公众号 PyTorch 开发者社区
EDL 全称 Elastic Deep Learning,由 LF AI 基金会孵化,是一个能动态调整并行度的深度神经网络训练框架。它支持多租户集群管理,可以平衡模型训练等待及完成时间,能够提高资源利用率。
训练深度学习模型通常比较耗时,在算力资源、储存空间等方面的花费也比较高昂。
以 BERT 模型为例, GPU 上的训练过程常常超过 2000 小时,而训练 ResNet 和 VGG 模型,少说也要 100 个小时。
按照现如今的云计算成本核算,模型训练费用可能高达数千甚至上万元。为了控制模型训练的成本,计算资源共享集群应运而生。我们今天介绍的是由 Petuum CASL 团队开发的 AdaptDL,它使得 GPU 集群中的 EDL 得到了极大优化。
共享集群面临的挑战
借助共享集群,多用户可以各自提交模型训练任务。
这不仅减少了计算资源过度供应造成的浪费,而且通过利用空闲资源,用户可以在一个工作站上,只用几天甚至几小时就能训练一个复杂模型。
但是,共享集群本身也存在一些问题。
共享集群面临的典型挑战包括:
1、资源分配:多任务共用一个集群,需要仔细规划 GPU 资源的分配问题。如训练模型时,用同一台机器上的 GPU,比使用多台机器上的 GPU,训练速度要快得多。而且为了避免训练任务之间竞争网络带宽,应该将不同的分布式训练任务,分配给不同机器上的 GPU。
2、训练速度和可扩展性参差不齐 :为训练任务选择合适的 GPU 配置,需要不间断地监控模型的训练速度和可扩展性,这些都是随着时间的变化而变化的。尤其是接近收敛(convergence)时,要使用较大的批尺寸。因此训练开始时,最好占用较少的 GPU 资源。
3、训练配置:通常情况下,我们需要提前知道哪些 GPU 可用,然后才能为一些重要的训练进行配置。这在共享集群中有时候无法实现的。例如,批尺寸以及学习率通常是根据 GPU 的数量来决定的,又或者已知 GPU 在不同的机器上,梯度累加能用来克服网络瓶颈等。
4、公平性和可用性:在 GPU 使用高峰,一些用户可能需要排队等待空闲 GPU,但是一些已经在跑任务的用户为了提速,还想增加 GPU 数量。如何权衡并解决二者矛盾。

AdaptDL 可以简化并加速本地机器和共享集群上的模型训练
AdaptDL让共享集群的问题迎刃而解
为了解决与组织池计算(organizations pool computing)和共享集群相关的缺点,Petuum CASL 团队创建了 AdaptDL,以简化和加快共享集群上的分布式训练。

AdaptDL 是一个资源自适应深度学习(DL)训练和调度框架。它可以实时监控训练任务的性能,并在任务运行期间,弹性地调整资源(如 GPU、计算实例等)分配。
它针对前文在共享集群中存在的问题,具有以下优势:
1、提高共享 GPU 集群的利用率:AdaptDL 可以针对所有模型训练任务进行分析,学习不同任务在不同 GPU 资源配置下的表现。利用学到的知识,AdaptDL 调度器能够公平高效地为不同的训练任务配置 GPU 资源。随着训练任务的增多,对不同任务的性能特征了解的越来越深入,AdaptDL 将学会弹性地再次配置 GPU。
2、降低云端模型训练成本:AdaptDL 可以在云端提供数量适中的 GPU 实例,避免多余的费用。当训练中使用更大的批尺寸时,AdaptDL 也能自动扩展集群。
3、轻松实现大批尺寸训练:使用较大的批尺寸可以在众多 GPU 上加速训练,但是应用起来并不简单。有些模型如果采用过大的批尺寸,可能因为降低统计效率而增加训练时长,但是使用过小的批尺寸又无法有效地利用 GPU。AdaptDL 可以在共享集群、云端环境和本地机器上,自动选择合适的批尺寸。
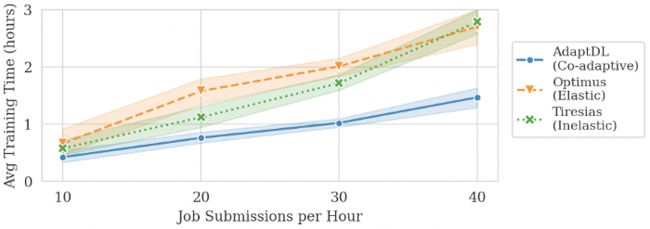
与 Optimus 和 Tiresias 相比,使用 AdaptDL 的模型平均训练用时更少
对于每个模型训练任务,AdaptDL 能自动调整批尺寸、学习率和梯度累加,在云服务平台中,也可以自行控制竞价实例(Spot Instance)的数量。
在 Petuum 的实践表明,借助 AdaptDL 共享集群训练模型,平均完成速度提高 2-3 倍,在 AWS 中使用竞价实例的费用也降低了 3 倍。
开始
AdaptDL 可以在两种模式下使用。
1、集群调度:允许在一个 Kubernetes 集群上运行多个任务。使用 AdaptDL Python 库,AdaptDL 调度程序可以集成到 PyTorch 代码中,自动选用最佳数量的 GPU 和训练批尺寸。
2、独立训练:在任意集群或本地多 GPU 机器上,用自适应批尺寸和学习率训练模型。AdaptDL 可以自动计算出何时可以使用较大的批尺寸来加速模型训练。
用 AdaptDL Python 库进行训练:
Adaptdl Python 库简化了 PyTorch 训练代码,使得批尺寸跟学习率都是自适应的,无需额外设定。
python3 –m pip install adaptdl以 PyTorch MNIST 为例,只需要修改几行代码。如下图所示:

AdaptDL 提供了一个类似于 PyTorch 原生的分布式数据并行接口,可以轻松地修改现有的分布式训练代码。
第一步:
用 adaptdl.torch.AdaptiveDataLoader 替代 torch.utils.data.DataLoader。
根据程序的吞吐量和统计效率,AdaptiveDataLoader 在训练期间可以自动选用最佳批尺寸。执行 checkpoint 时还能保存状态,这样重新启动后就能从停止的地方恢复训练了。
train_loader.autoscale_batch_size(1024) 使得 AdaptDL 能为训练自动选择最有效的批尺寸,在所有训练进程中最大全局批尺寸(global batch size)合计 1024。
接下来:
用 adaptdl.torch.AdaptiveDataParallel 封装模型。
adaptdl.torch.AdaptiveDataParallel 在训练过程中会计算梯度噪声尺度(Gradient Noise Scale),它可以用于计算统计效率。当批尺寸改变时,AdaptiveDataParallel 将根据规则自动调整学习率。
默认情况下,AdaptiveDataParallel 用的是在多种任务中都性能良好的 AdaScale。
在 checkpoint 期间,AdaptiveDataParallel 可以自动保存模型参数、优化器状态和 LR 调度器状态,在重新启动训练后一键恢复这些设置。
通过以上更改,用户可以在本地计算机或分布式集群中运行训练代码。AdaptDL 为更快的分布式训练选择了正确的批尺寸和学习率,并自动执行梯度累加,以克服网络问题。
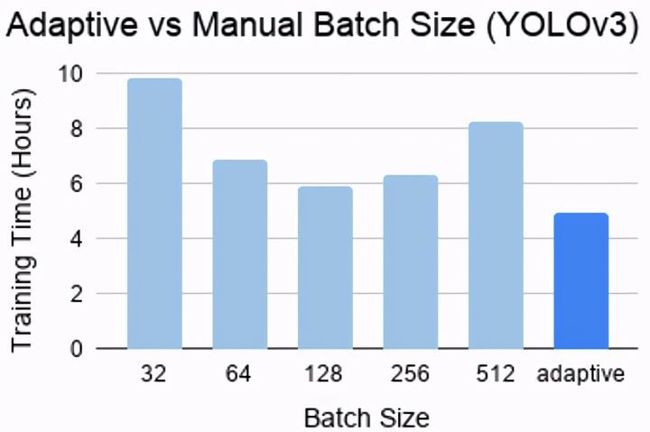
YOLOv3在Adaptive和Manual Batch Size两台机器上的训练时对比,Adaptive在训练时和批尺寸对比方面优势显著
如果不使用 AdaptDL,一旦选择过小的批尺寸,则会因为没有充分利用 GPU,导致训练时延长。相反,如果选择一个过大的批尺寸,也会因为需要更多的 epoch 来收敛,从而导致更长的训练时。对比可知 AdaptDL 无需选择固定的批尺寸,就能自动达到更好的训练性能。
用 AdaptDL 调度器进行集群管理:
AdaptDL 调度器能够自动判断训练任务要使用的 GPU 资源,这使得共享集群中的训练任务变得更智能。
利用灵活性,当集群空闲率较高时,训练任务就会扩展为使用额外 GPU;当集群使用率较高时,将收缩为使用较少的 GPU 资源,而不是暂停训练任务。
AdaptDL 调度器还提供了其他功能,如整理集群以避免不同任务之间的网络争夺,以及保持竞争性训练任务之间的公平性。
由于调度器和每个训练任务之间的协调,AdaptDL 可以让共享集群保持高效利用率。
当一个任务可以有效地使用更大的批尺寸时,AdaptDL 会自动地将更多的 GPU 转移到该工作上以加速训练。另一方面,当只能使用较小的批尺寸时,空闲的 GPU 将更有效地分配给其他任务。
AdaptDL 调度器可以使用 Helm 一键安装在任何一个 Kubernetes 实例上,命令如下:
helm install adaptdl adaptdl-sched
-— repo https://github.com/petuum/adaptdl/raw/helm-repo
-— namespace adaptdl — create-namespace
-— set docker-registry.enabled=true安装 AdaptDL 调度器后,就可以使用 AdaptDL CLI 提交训练任务了。刚开始训练任务会使用一个单一 GPU,然后使用不同数量的 GPU 多次重启,这期间 AdaptDL 会计算出最佳数量的 GPU 使用。不管有多少 GPU,AdaptDL 总能选择最有效的批尺寸,并相应地调整学习率。
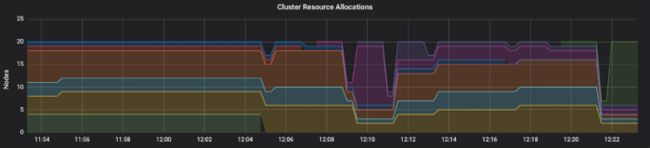
AdaptDL集群跟踪示例
彩色条形图显示分配给不同任务的计算实例数量,AdaptDL 可以动态优化每个任务获得的计算实例数量
借助 AdaptDL,PyTorch 训练任务在共享集群中运行的速度提升了 2-3 倍。此外,AdaptDL 调度器还支持 AWS 竞价实例,使得费用也降低了 3 倍。
最后,还可以使用 AdaptDL 和 NNI 来加速超参数调优工作负载(AdaptDL + NNI Post)。
项目地址:点击此处
本文翻译自 PyTorch Medium 博客。
参考: 点击此处