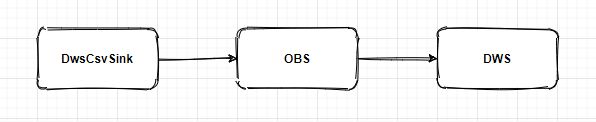
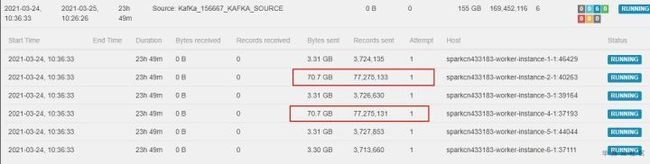
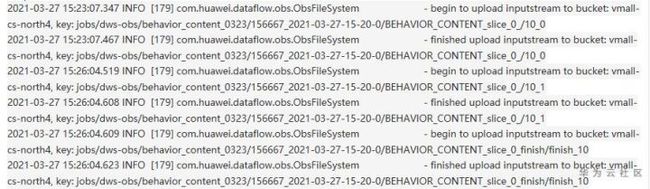
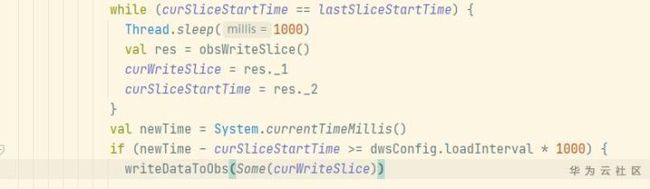
- Long类型前后端数据不一致
igotyback
前端
响应给前端的数据浏览器控制台中response中看到的Long类型的数据是正常的到前端数据不一致前后端数据类型不匹配是一个常见问题,尤其是当后端使用Java的Long类型(64位)与前端JavaScript的Number类型(最大安全整数为2^53-1,即16位)进行数据交互时,很容易出现精度丢失的问题。这是因为JavaScript中的Number类型无法安全地表示超过16位的整数。为了解决这个问
- 使用 FinalShell 进行远程连接(ssh 远程连接 Linux 服务器)
编程经验分享
开发工具服务器sshlinux
目录前言基本使用教程新建远程连接连接主机自定义命令路由追踪前言后端开发,必然需要和服务器打交道,部署应用,排查问题,查看运行日志等等。一般服务器都是集中部署在机房中,也有一些直接是云服务器,总而言之,程序员不可能直接和服务器直接操作,一般都是通过ssh连接来登录服务器。刚接触远程连接时,使用的是XSHELL来远程连接服务器,连接上就能够操作远程服务器了,但是仅用XSHELL并没有上传下载文件的功能
- Low Power概念介绍-Voltage Area
飞奔的大虎
随着智能手机,以及物联网的普及,芯片功耗的问题最近几年得到了越来越多的重视。为了实现集成电路的低功耗设计目标,我们需要在系统设计阶段就采用低功耗设计的方案。而且,随着设计流程的逐步推进,到了芯片后端设计阶段,降低芯片功耗的方法已经很少了,节省的功耗百分比也不断下降。芯片的功耗主要由静态功耗(staticleakagepower)和动态功耗(dynamicpower)构成。静态功耗主要是指电路处于等
- nosql数据库技术与应用知识点
皆过客,揽星河
NoSQLnosql数据库大数据数据分析数据结构非关系型数据库
Nosql知识回顾大数据处理流程数据采集(flume、爬虫、传感器)数据存储(本门课程NoSQL所处的阶段)Hdfs、MongoDB、HBase等数据清洗(入仓)Hive等数据处理、分析(Spark、Flink等)数据可视化数据挖掘、机器学习应用(Python、SparkMLlib等)大数据时代存储的挑战(三高)高并发(同一时间很多人访问)高扩展(要求随时根据需求扩展存储)高效率(要求读写速度快)
- JVM、JRE和 JDK:理解Java开发的三大核心组件
Y雨何时停T
Javajava
Java是一门跨平台的编程语言,它的成功离不开背后强大的运行环境与开发工具的支持。在Java的生态中,JVM(Java虚拟机)、JRE(Java运行时环境)和JDK(Java开发工具包)是三个至关重要的核心组件。本文将探讨JVM、JDK和JRE的区别,帮助你更好地理解Java的运行机制。1.JVM:Java虚拟机(JavaVirtualMachine)什么是JVM?JVM,即Java虚拟机,是Ja
- springboot+vue项目实战一-创建SpringBoot简单项目
苹果酱0567
面试题汇总与解析springboot后端java中间件开发语言
这段时间抽空给女朋友搭建一个个人博客,想着记录一下建站的过程,就当做笔记吧。虽然复制zjblog只要一个小时就可以搞定一个网站,或者用cms系统,三四个小时就可以做出一个前后台都有的网站,而且想做成啥样也都行。但是就是要从新做,自己做的意义不一样,更何况,俺就是专门干这个的,嘿嘿嘿要做一个网站,而且从零开始,首先呢就是技术选型了,经过一番思量决定选择-SpringBoot做后端,前端使用Vue做一
- uniapp map组件自定义markers标记点
以对_
uni-app学习记录uni-appjavascript前端
需求是根据后端返回数据在地图上显示标记点,并且根据数据状态控制标记点颜色,标记点背景通过两张图片实现控制{{item.options.labelName}}exportdefault{data(){return{storeIndex:0,locaInfo:{longitude:120.445172,latitude:36.111387},markers:[//标点列表{id:1,//标记点idin
- 笋丁网页自动回复机器人V3.0.0免授权版源码
希希分享
软希网58soho_cn源码资源笋丁网页自动回复机器人
笋丁网页机器人一款可设置自动回复,默认消息,调用自定义api接口的网页机器人。此程序后端语言使用Golang,内存占用最高不超过30MB,1H1G服务器流畅运行。仅支持Linux服务器部署,不支持虚拟主机,请悉知!使用自定义api功能需要有一定的建站基础。源码下载:https://download.csdn.net/download/m0_66047725/89754250更多资源下载:关注我。安
- 博客网站制作教程
2401_85194651
javamaven
首先就是技术框架:后端:Java+SpringBoot数据库:MySQL前端:Vue.js数据库连接:JPA(JavaPersistenceAPI)1.项目结构blog-app/├──backend/│├──src/main/java/com/example/blogapp/││├──BlogApplication.java││├──config/│││└──DatabaseConfig.java
- 深入浅出 -- 系统架构之负载均衡Nginx的性能优化
xiaoli8748_软件开发
系统架构系统架构负载均衡nginx
一、Nginx性能优化到这里文章的篇幅较长了,最后再来聊一下关于Nginx的性能优化,主要就简单说说收益最高的几个优化项,在这块就不再展开叙述了,毕竟影响性能都有多方面原因导致的,比如网络、服务器硬件、操作系统、后端服务、程序自身、数据库服务等,对于性能调优比较感兴趣的可以参考之前《JVM性能调优》中的调优思想。优化一:打开长连接配置通常Nginx作为代理服务,负责分发客户端的请求,那么建议开启H
- 计算机毕业设计PHP仓储综合管理系统(源码+程序+VUE+lw+部署)
java毕设程序源码王哥
php课程设计vue.js
该项目含有源码、文档、程序、数据库、配套开发软件、软件安装教程。欢迎交流项目运行环境配置:phpStudy+Vscode+Mysql5.7+HBuilderX+Navicat11+Vue+Express。项目技术:原生PHP++Vue等等组成,B/S模式+Vscode管理+前后端分离等等。环境需要1.运行环境:最好是小皮phpstudy最新版,我们在这个版本上开发的。其他版本理论上也可以。2.开发
- 微信小程序开发注意事项
jun778895
微信小程序小程序
微信小程序开发是一个融合了前端开发、用户体验设计、后端服务(可选)以及微信小程序平台特性的综合性项目。这里,我将详细介绍一个典型的小程序开发项目的全过程,包括项目规划、设计、开发、测试及部署上线等各个环节,并尽量使内容达到或超过2000字的要求。一、项目规划1.1项目背景与目标假设我们要开发一个名为“智慧校园助手”的微信小程序,旨在为学生提供一站式校园生活服务,包括课程表查询、图书馆座位预约、食堂
- 【Golang】实现 Excel 文件下载功能
RumIV
Golanggolangexcel开发语言
在当今的网络应用开发中,提供数据导出功能是一项常见的需求。Excel作为一种广泛使用的电子表格格式,通常是数据导出的首选格式之一。在本教程中,我们将学习如何使用Go语言和GinWeb框架来创建一个Excel文件,并允许用户通过HTTP请求下载该文件。准备工作在开始之前,请确保您的开发环境中已经安装了Go语言和相关的开发工具。此外,您还需要安装GinWeb框架和excelize包,这两个包都将用于我
- VUE3 + xterm + nestjs实现web远程终端 或 连接开启SSH登录的路由器和交换机。
焚木灵
node.jsvue
可远程连接系统终端或开启SSH登录的路由器和交换机。相关资料:xtermjs/xterm.js:Aterminalfortheweb(github.com)后端实现(NestJS):1、安装依赖:npminstallnode-ssh@nestjs/websockets@nestjs/platform-socket.io2、我们将创建一个名为RemoteControlModule的NestJS模块,
- uniapp实现动态标记效果详细步骤【前端开发】
2401_85123349
uni-app
第二个点在于实现将已经被用户标记的内容在下一次获取后刷新它的状态为已标记。这是什么意思呢?比如说上面gif图中的这些人物对象,有一些已被该用户添加为关心,那么当用户下一次进入该页面时,这些已经被添加关心的对象需要以“红心”状态显现出来。这个点的难度还不算大,只需要在每一次获取后端的内容后对标记对象进行状态更新即可。II.动态标记效果实现思路和步骤首先,整体的思路是利用动态类名对不同的元素进行选择。
- 后端开发刷题 | 把数字翻译成字符串(动态规划)
jingling555
笔试题目动态规划java算法数据结构后端
描述有一种将字母编码成数字的方式:'a'->1,'b->2',...,'z->26'。现在给一串数字,返回有多少种可能的译码结果数据范围:字符串长度满足0=10&&num<=26){if(i==1){dp[i]+=1;}else{dp[i]+=dp[i-2];}}}returndp[nums.length()-1];}}
- 第三十一节:Vue路由:前端路由vs后端路由的了解
曹老师
1.认识前端路由和后端路由前端路由相对于后端路由而言的,在理解前端路由之前先对于路由有一个基本的了解路由:简而言之,就是把信息从原地址传输到目的地的活动对于我们来说路由就是:根据不同的url地址展示不同的页面内容1.1后端路由以前咱们接触比较多的后端路由,当改变url地址时,浏览器会向服务器发送请求,服务器根据这个url,返回不同的资源内容后端路由的特点就是前端每次跳转到不同url地址,都会重新访
- 如何建设数据中台(五)——数据汇集—打破企业数据孤岛
weixin_47088026
学习记录和总结中台数据中台程序人生经验分享
数据汇集——打破企业数据孤岛要构建企业级数据中台,第一步就是将企业内部各个业务系统的数据实现互通互联,打破数据孤岛,主要通过数据汇聚和交换来实现。企业采集的数据可以是线上采集、线下数据采集、互联网数据采集、内部数据采集等。线上数据采集主要载体分为互联网和移动互联网两种,对应有系统平台、网页、H5、小程序、App等,可以采用前端或后端埋点方式采集数据。线下数据采集主要是通过硬件来采集,例如:WiFi
- 【C#生态园】深度剖析:C#嵌入式开发工具大揭秘
friklogff
C#生态园c#开发语言
C#嵌入式开发:全面了解六大框架与库前言随着物联网和嵌入式系统的快速发展,越来越多的开发者开始关注使用C#语言进行嵌入式开发。本文将介绍几种用于C#的嵌入式开发框架和相关库,以及它们的核心功能、安装配置方法和API概览,帮助读者了解并选择适合自己项目的工具和资源。欢迎订阅专栏:C#生态园文章目录C#嵌入式开发:全面了解六大框架与库前言1.nanoFramework:一个用于C#的嵌入式开发框架1.
- 创建一个完整的购物商城系统是一个复杂的项目,涉及前端(用户界面)、后端(服务器逻辑)、数据库等多个部分。由于篇幅限制,我无法在这里提供一个完整的系统代码,但我可以分别给出一些关键部分的示例代码,涵盖几
uthRaman
前端ui服务器
前端(HTML/CSS/JavaScript)grsyzp.cnHTML页面结构(index.html)html购物商城欢迎来到购物商城JavaScript(Ajax请求商品数据,app.js)javascriptdocument.addEventListener('DOMContentLoaded',function(){fetch('/api/products').then(response=
- 手机小游戏开发
红匣子实力推荐
随着智能手机的普及,手机小游戏已经成为人们日常生活中不可或缺的一部分。从简单的消除游戏到复杂的策略游戏,手机小游戏为玩家提供了丰富的娱乐体验。本文将为您介绍手机小游戏开发的基本概念、工具和技术。开发-联系电话:13642679953(微信同号)1.游戏类型手机小游戏可以分为多种类型,如益智游戏、休闲游戏、动作游戏、策略游戏等。开发者可以根据自己的兴趣和技能选择合适的游戏类型进行开发。2.开发工具手
- 若依后端正常启动但是uniapp移动端提示后端接口异常
大可大可抖
uni-app
pc端能用模拟器也能正常连接接口,手机端真机调试连不上接口解决:1.先看config.js的填自己的ip地址module.exports={//baseUrl:'https://vue.ruoyi.vip/prod-api',baseUrl:"http://192.168.101.5:8080",}2.网络环境问题(防火墙)点击属性然后选择专用
- Lombok:Java开发者的代码简化神器【后端 17】
终末圆
Java后端java开发语言mysql数据库后端springbootpython
Lombok:Java开发者的代码简化神器在Java开发中,我们经常需要编写大量的样板代码,如getter、setter、equals、hashCode、toString等方法。这些代码虽然基础且必要,但往往占据了大量开发时间,且容易在属性变更时引发错误。幸运的是,Lombok这个Java库通过注解的方式,为我们提供了一种高效的解决方案。本文将详细介绍Lombok的使用及其优势。什么是Lombok
- 后端开发刷题 | 最长回文子串
jingling555
笔试题目java算法javascript数据结构后端
描述对于长度为n的一个字符串A(仅包含数字,大小写英文字母),请设计一个高效算法,计算其中最长回文子串的长度。数据范围:1≤n≤1000要求:空间复杂度O(1),时间复杂度O(n2)进阶:空间复杂度O(n),时间复杂度O(n)示例1输入:"ababc"返回值:3说明:最长的回文子串为"aba"与"bab",长度都为3示例2输入:"abbba"返回值:5示例3输入:"b"返回值:1思路分析:该题可以
- 哪些网站用python开发
hakesashou
python基础知识python
国内的话,知乎,网易,腾讯,搜狐,金山,豆瓣这些属于用Python比较知名的。大型的项目的话,网易的许多游戏,腾讯的某些网站,搜狐的邮箱,金山的测试框架等等都是或多或少使用了Python。YouTube-视频分享网站,在某些功能上使用到python。Quora-社交问答网站。Google-谷歌在很多项目中用python作为网络应用的后端,如GoogleGroups、Gmail、GoogleMaps
- 2019-05-29 vue-router的两种模式的区别
Kason晨
1、大家都知道vue是一种单页应用,单页应用就是仅在页面初始化的时候加载相应的html/css/js一单页面加载完成,不会因为用户的操作而进行页面的重新加载或者跳转,用javascript动态的变化html的内容优点:良好的交互体验,用户不需要刷新页面,页面显示流畅,良好的前后端工作分离模式,减轻服务器压力,缺点:不利于SEO,初次加载耗时比较多2、hash模式vue-router默认的是hash
- 计算机毕设Node.js+Vue校园易购二手交易平台(程序+LW+部署)
Node程序源码强子
vue.js课程设计node.js
项目运行环境配置:Node.js最新版+Vscode+Mysql5.7+HBuilderX+Navicat11+Vue。项目技术:Express框架+Node.js+Vue等等组成,B/S模式+Vscode管理+前后端分离等等。环境需要1.运行环境:最好是Nodejs最新版,我们在这个版本上开发的。其他版本理论上也可以。2.开发
- 锋哥写一套前后端分离Python权限系统 基于Django5+DRF+Vue3.2+Element Plus+Jwt 视频教程 ,帅呆了~~
java1234_小锋
Python权限系统django权限系统pythonweb权限系统djangoDRFVUE权限python
大家好,我是java1234_小锋老师,最近写了一套【前后端分离Python权限系统基于Django5+DRF+Vue3.2+ElementPlus+Jwt】视频教程,持续更新中,计划月底更新完,感谢支持。视频在线地址:打造前后端分离Python权限系统基于Django5+DRF+Vue3.2+ElementPlus+Jwt视频教程(火爆连载更新中..)_哔哩哔哩_bilibili项目介绍本课程采
- 外卖霸王餐返利外卖会员卡小程序开发
闹小艾
good506070微信小程序小程序
外卖霸王餐返利外卖会员卡小程序开发"社交电商赋能下的外卖返利小程序"是专为商家与用户双赢而设计的创新平台。以下是其开发方案的详细步骤:一、需求梳理:首先,我们需要明确小程序的核心功能和特色。包括设定活动类型、返利策略,以及用户体验友好的界面设计。二、技术决策:技术选型是关键。我们采用小程序的开发框架,利用JavaScript作为前端开发语言,并结合微信提供的API进行后端接口调用与数据处理。三、账
- 全能第三方支付对接pay-java-parent 2.12.7 发布,支付聚合
egzosn
支付第三方支付支付聚合支付对接支付pay微信
全能第三方支付对接Java开发工具包.优雅的轻量级支付模块集成支付对接支付整合(微信,支付宝,银联,友店,富友,跨境支付paypal,payoneer(P卡派安盈)易极付)app,扫码,网页支付刷卡付条码付刷脸付转账服务商模式、支持多种支付类型多支付账户,支付与业务完全剥离,简单几行代码即可实现支付,简单快速完成支付模块的开发,可轻松嵌入到任何系统里目前仅是一个开发工具包(即SDK),只提供简单W
- web前段跨域nginx代理配置
刘正强
nginxcmsWeb
nginx代理配置可参考server部分
server {
listen 80;
server_name localhost;
- spring学习笔记
caoyong
spring
一、概述
a>、核心技术 : IOC与AOP
b>、开发为什么需要面向接口而不是实现
接口降低一个组件与整个系统的藕合程度,当该组件不满足系统需求时,可以很容易的将该组件从系统中替换掉,而不会对整个系统产生大的影响
c>、面向接口编口编程的难点在于如何对接口进行初始化,(使用工厂设计模式)
- Eclipse打开workspace提示工作空间不可用
0624chenhong
eclipse
做项目的时候,难免会用到整个团队的代码,或者上一任同事创建的workspace,
1.电脑切换账号后,Eclipse打开时,会提示Eclipse对应的目录锁定,无法访问,根据提示,找到对应目录,G:\eclipse\configuration\org.eclipse.osgi\.manager,其中文件.fileTableLock提示被锁定。
解决办法,删掉.fileTableLock文件,重
- Javascript 面向对面写法的必要性?
一炮送你回车库
JavaScript
现在Javascript面向对象的方式来写页面很流行,什么纯javascript的mvc框架都出来了:ember
这是javascript层的mvc框架哦,不是j2ee的mvc框架
我想说的是,javascript本来就不是一门面向对象的语言,用它写出来的面向对象的程序,本身就有些别扭,很多人提到js的面向对象首先提的是:复用性。那么我请问你写的js里有多少是可以复用的,用fu
- js array对象的迭代方法
换个号韩国红果果
array
1.forEach 该方法接受一个函数作为参数, 对数组中的每个元素
使用该函数 return 语句失效
function square(num) {
print(num, num * num);
}
var nums = [1,2,3,4,5,6,7,8,9,10];
nums.forEach(square);
2.every 该方法接受一个返回值为布尔类型
- 对Hibernate缓存机制的理解
归来朝歌
session一级缓存对象持久化
在hibernate中session一级缓存机制中,有这么一种情况:
问题描述:我需要new一个对象,对它的几个字段赋值,但是有一些属性并没有进行赋值,然后调用
session.save()方法,在提交事务后,会出现这样的情况:
1:在数据库中有默认属性的字段的值为空
2:既然是持久化对象,为什么在最后对象拿不到默认属性的值?
通过调试后解决方案如下:
对于问题一,如你在数据库里设置了
- WebService调用错误合集
darkranger
webservice
Java.Lang.NoClassDefFoundError: Org/Apache/Commons/Discovery/Tools/DiscoverSingleton
调用接口出错,
一个简单的WebService
import org.apache.axis.client.Call;import org.apache.axis.client.Service;
首先必不可
- JSP和Servlet的中文乱码处理
aijuans
Java Web
JSP和Servlet的中文乱码处理
前几天学习了JSP和Servlet中有关中文乱码的一些问题,写成了博客,今天进行更新一下。应该是可以解决日常的乱码问题了。现在作以下总结希望对需要的人有所帮助。我也是刚学,所以有不足之处希望谅解。
一、表单提交时出现乱码:
在进行表单提交的时候,经常提交一些中文,自然就避免不了出现中文乱码的情况,对于表单来说有两种提交方式:get和post提交方式。所以
- 面试经典六问
atongyeye
工作面试
题记:因为我不善沟通,所以在面试中经常碰壁,看了网上太多面试宝典,基本上不太靠谱。只好自己总结,并试着根据最近工作情况完成个人答案。以备不时之需。
以下是人事了解应聘者情况的最典型的六个问题:
1 简单自我介绍
关于这个问题,主要为了弄清两件事,一是了解应聘者的背景,二是应聘者将这些背景信息组织成合适语言的能力。
我的回答:(针对技术面试回答,如果是人事面试,可以就掌
- contentResolver.query()参数详解
百合不是茶
androidquery()详解
收藏csdn的博客,介绍的比较详细,新手值得一看 1.获取联系人姓名
一个简单的例子,这个函数获取设备上所有的联系人ID和联系人NAME。
[java]
view plain
copy
public void fetchAllContacts() {
- ora-00054:resource busy and acquire with nowait specified解决方法
bijian1013
oracle数据库killnowait
当某个数据库用户在数据库中插入、更新、删除一个表的数据,或者增加一个表的主键时或者表的索引时,常常会出现ora-00054:resource busy and acquire with nowait specified这样的错误。主要是因为有事务正在执行(或者事务已经被锁),所有导致执行不成功。
1.下面的语句
- web 开发乱码
征客丶
springWeb
以下前端都是 utf-8 字符集编码
一、后台接收
1.1、 get 请求乱码
get 请求中,请求参数在请求头中;
乱码解决方法:
a、通过在web 服务器中配置编码格式:tomcat 中,在 Connector 中添加URIEncoding="UTF-8";
1.2、post 请求乱码
post 请求中,请求参数分两部份,
1.2.1、url?参数,
- 【Spark十六】: Spark SQL第二部分数据源和注册表的几种方式
bit1129
spark
Spark SQL数据源和表的Schema
case class
apply schema
parquet
json
JSON数据源 准备源数据
{"name":"Jack", "age": 12, "addr":{"city":"beijing&
- JVM学习之:调优总结 -Xms -Xmx -Xmn -Xss
BlueSkator
-Xss-Xmn-Xms-Xmx
堆大小设置JVM 中最大堆大小有三方面限制:相关操作系统的数据模型(32-bt还是64-bit)限制;系统的可用虚拟内存限制;系统的可用物理内存限制。32位系统下,一般限制在1.5G~2G;64为操作系统对内存无限制。我在Windows Server 2003 系统,3.5G物理内存,JDK5.0下测试,最大可设置为1478m。典型设置:
java -Xmx355
- jqGrid 各种参数 详解(转帖)
BreakingBad
jqGrid
jqGrid 各种参数 详解 分类:
源代码分享
个人随笔请勿参考
解决开发问题 2012-05-09 20:29 84282人阅读
评论(22)
收藏
举报
jquery
服务器
parameters
function
ajax
string
- 读《研磨设计模式》-代码笔记-代理模式-Proxy
bylijinnan
java设计模式
声明: 本文只为方便我个人查阅和理解,详细的分析以及源代码请移步 原作者的博客http://chjavach.iteye.com/
import java.lang.reflect.InvocationHandler;
import java.lang.reflect.Method;
import java.lang.reflect.Proxy;
/*
* 下面
- 应用升级iOS8中遇到的一些问题
chenhbc
ios8升级iOS8
1、很奇怪的问题,登录界面,有一个判断,如果不存在某个值,则跳转到设置界面,ios8之前的系统都可以正常跳转,iOS8中代码已经执行到下一个界面了,但界面并没有跳转过去,而且这个值如果设置过的话,也是可以正常跳转过去的,这个问题纠结了两天多,之前的判断我是在
-(void)viewWillAppear:(BOOL)animated
中写的,最终的解决办法是把判断写在
-(void
- 工作流与自组织的关系?
comsci
设计模式工作
目前的工作流系统中的节点及其相互之间的连接是事先根据管理的实际需要而绘制好的,这种固定的模式在实际的运用中会受到很多限制,特别是节点之间的依存关系是固定的,节点的处理不考虑到流程整体的运行情况,细节和整体间的关系是脱节的,那么我们提出一个新的观点,一个流程是否可以通过节点的自组织运动来自动生成呢?这种流程有什么实际意义呢?
这里有篇论文,摘要是:“针对网格中的服务
- Oracle11.2新特性之INSERT提示IGNORE_ROW_ON_DUPKEY_INDEX
daizj
oracle
insert提示IGNORE_ROW_ON_DUPKEY_INDEX
转自:http://space.itpub.net/18922393/viewspace-752123
在 insert into tablea ...select * from tableb中,如果存在唯一约束,会导致整个insert操作失败。使用IGNORE_ROW_ON_DUPKEY_INDEX提示,会忽略唯一
- 二叉树:堆
dieslrae
二叉树
这里说的堆其实是一个完全二叉树,每个节点都不小于自己的子节点,不要跟jvm的堆搞混了.由于是完全二叉树,可以用数组来构建.用数组构建树的规则很简单:
一个节点的父节点下标为: (当前下标 - 1)/2
一个节点的左节点下标为: 当前下标 * 2 + 1
&
- C语言学习八结构体
dcj3sjt126com
c
为什么需要结构体,看代码
# include <stdio.h>
struct Student //定义一个学生类型,里面有age, score, sex, 然后可以定义这个类型的变量
{
int age;
float score;
char sex;
}
int main(void)
{
struct Student st = {80, 66.6,
- centos安装golang
dcj3sjt126com
centos
#在国内镜像下载二进制包
wget -c http://www.golangtc.com/static/go/go1.4.1.linux-amd64.tar.gz
tar -C /usr/local -xzf go1.4.1.linux-amd64.tar.gz
#把golang的bin目录加入全局环境变量
cat >>/etc/profile<
- 10.性能优化-监控-MySQL慢查询
frank1234
性能优化MySQL慢查询
1.记录慢查询配置
show variables where variable_name like 'slow%' ; --查看默认日志路径
查询结果:--不用的机器可能不同
slow_query_log_file=/var/lib/mysql/centos-slow.log
修改mysqld配置文件:/usr /my.cnf[一般在/etc/my.cnf,本机在/user/my.cn
- Java父类取得子类类名
happyqing
javathis父类子类类名
在继承关系中,不管父类还是子类,这些类里面的this都代表了最终new出来的那个类的实例对象,所以在父类中你可以用this获取到子类的信息!
package com.urthinker.module.test;
import org.junit.Test;
abstract class BaseDao<T> {
public void
- Spring3.2新注解@ControllerAdvice
jinnianshilongnian
@Controller
@ControllerAdvice,是spring3.2提供的新注解,从名字上可以看出大体意思是控制器增强。让我们先看看@ControllerAdvice的实现:
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Component
public @interface Co
- Java spring mvc多数据源配置
liuxihope
spring
转自:http://www.itpub.net/thread-1906608-1-1.html
1、首先配置两个数据库
<bean id="dataSourceA" class="org.apache.commons.dbcp.BasicDataSource" destroy-method="close&quo
- 第12章 Ajax(下)
onestopweb
Ajax
index.html
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/
- BW / Universe Mappings
blueoxygen
BO
BW Element
OLAP Universe Element
Cube Dimension
Class
Charateristic
A class with dimension and detail objects (Detail objects for key and desription)
Hi
- Java开发熟手该当心的11个错误
tomcat_oracle
java多线程工作单元测试
#1、不在属性文件或XML文件中外化配置属性。比如,没有把批处理使用的线程数设置成可在属性文件中配置。你的批处理程序无论在DEV环境中,还是UAT(用户验收
测试)环境中,都可以顺畅无阻地运行,但是一旦部署在PROD 上,把它作为多线程程序处理更大的数据集时,就会抛出IOException,原因可能是JDBC驱动版本不同,也可能是#2中讨论的问题。如果线程数目 可以在属性文件中配置,那么使它成为
- 推行国产操作系统的优劣
yananay
windowslinux国产操作系统
最近刮起了一股风,就是去“国外货”。从应用程序开始,到基础的系统,数据库,现在已经刮到操作系统了。原因就是“棱镜计划”,使我们终于认识到了国外货的危害,开始重视起了信息安全。操作系统是计算机的灵魂。既然是灵魂,为了信息安全,那我们就自然要使用和推行国货。可是,一味地推行,是否就一定正确呢?
先说说信息安全。其实从很早以来大家就在讨论信息安全。很多年以前,就据传某世界级的网络设备制造商生产的交