ClickHouse 是俄罗斯最大的搜索引擎Yandex在2016年开源的数据库管理系统(DBMS),主要用于联机分析处理(OLAP)。其采用了面向列的存储方式,性能远超传统面向行的DBMS,近几年受到广泛关注。
本文将介绍ClickHouse MergeTree系列表引擎的相关知识,并通过示例分析MergeTree存储引擎的数据存储结构。
1 MergeTree表引擎简介
MergeTree(合并树)系列表引擎是ClickHouse提供的最具特色的存储引擎。MergeTree引擎支持数据按主键、数据分区、数据副本以及数据采样等特性。官方提供了包括MergeTree、ReplacingMergeTree、SummingMergeTree、AggregatingMergeTree、CollapsingMergeTree、VersionedCollapsingMergeTree、GraphiteMergeTree等7种不同类型的MergeTree引擎的实现,以及与其相对应的支持数据副本的MergeTree引擎(Replicated*)。
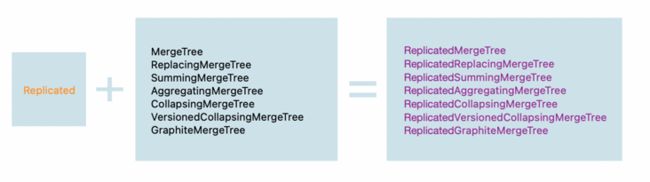
首先来介绍一下MergeTree核心引擎:
ReplacingMergeTree:在后台数据合并期间,对具有相同排序键的数据进行去重操作。
SummingMergeTree:当合并数据时,会把具有相同主键的记录合并为一条记录。根据聚合字段设置,该字段的值为聚合后的汇总值,非聚合字段使用第一条记录的值,聚合字段类型必须为数值类型。
AggregatingMergeTree:在同一数据分区下,可以将具有相同主键的数据进行聚合。
CollapsingMergeTree:在同一数据分区下,对具有相同主键的数据进行折叠合并。
VersionedCollapsingMergeTree:
基于CollapsingMergeTree引擎,增添了数据版本信息字段配置选项。在数据依据ORDER BY设置对数据进行排序的基础上,如果数据的版本信息列不在排序字段中,那么版本信息会被隐式的作为ORDER BY的最后一列从而影响数据排序。
GraphiteMergeTree:用来存储时序数据库Graphites的数据。
MergeTree是该系列引擎中最核心的引擎,其他引擎均以MergeTree为基础,并在数据合并过程中实现了不同的特性,从而构成了MergeTree表引擎家族。下面我们通过MergeTree来具体了解MergeTree表系列引擎。
2 MergeTree引擎
2.1 表创建
创建MergeTree的DDL如下所示:
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1] [TTL expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2] [TTL expr2],
...
) ENGINE = MergeTree()
ORDER BY expr
[PARTITION BY expr]
[PRIMARY KEY expr]
[SAMPLE BY expr]
[TTL expr [DELETE|TO DISK 'xxx'|TO VOLUME 'xxx'], ...]
[SETTINGS name=value, ... 这里说明一下MergeTree引擎的主要参数:
必填选项
ENGINE:引擎名字,MergeTree引擎无参数。
ORDER BY:排序键,可以由一列或多列组成,决定了数据以何种方式进行排序,例如ORDER BY(CounterID, EventDate)。 如果没有显示指定PRIMARY KEY,那么将使用ORDER BY作为PRIMARY KEY。通常只指定ORDER BY即可。
选填选项
PARTITION BY:分区键,指明表中的数据以何种规则进行分区。分区是在一个表中通过指定的规则划分而成的逻辑数据集。分区可以按任意标准进行,如按月、按日或按事件类型。为了减少需要操作的数据,每个分区都是分开存储的。
PRIMARY KEY:主键,设置后会按照主键生成一级索引(primary.idx),数据会依据索引的设置进行排序,从而加速查询性能。默认情况下,PRIMARY KEY与ORDER BY设置相同,所以通常情况下直接使用ORDER BY设置来替代主键设置。
SAMPLE BY:数据采样设置,如果显示配置了该选项,那么主键配置中也应该包括此配置。例如 ORDER BY CounterID / EventDate / intHash32(UserID)、SAMPLE BY intHash32(UserID)。
TTL:数据存活时间,可以为某一字段列或者一整张表设置TTL,设置中必须包含Date或DateTime字段类型。如果设置在列上,那么会删除字段中过期的数据。如果设置的是表级的TTL,那么会删除表中过期的数据。如果设置了两种类型,那么按先到期的为准。例如,TTL createtime + INTERVAL 1 DAY,即一天后过期。使用场景包括定期删除数据,或者定期将数据进行归档。
index_granularity:索引间隔粒度。MergeTree索引为稀疏索引,每index_granularity个数据产生一条索引。index_granularity默认设置为8092。
enable_mixed_granularity_parts:是否启动index_granularity_bytes来控制索引粒度大小。
index_granularity_bytes:索引粒度,以字节为单位,默认10Mb。
merge_max_block_size:数据块合并最大记录个数,默认8192。
merge_with_ttl_timeout:合并频率最小时间间隔,默认1天。
2.2 数据存储结构
首先创建一个test表,DDL如下:
CREATE TABLE test.test
(
id UInt64,
type UInt8,
create_time DateTime
) ENGINE = MergeTree()
PARTITION BY toYYYYMMDD(create_time)
ORDER BY (id)
SETTINGS index_granularity = 4;test表包括id、type、create等三个字段,其中以create_time日期字段作为分区键,并将日期格式转化为YYYYMMDD。按照id字段进行排序。由于没有显式设置主键,所以引擎默认使用ORDER BY设置的id列作为索引字段,并生成索引文件。index_granularity设置为4,意味着每4条数据产生一条索引数据。
插入一条测试数据:
insert into test.test(id, type, create_time) VALUES (1, 1, toDateTime('2021-03-01 00:00:00'));使用如下命令查看test表分区相关信息:
SELECT
database,
table,
partition,
partition_id,
name,
active,
path
FROM system.parts
WHERE table = 'test' 返回结果如下图所示:
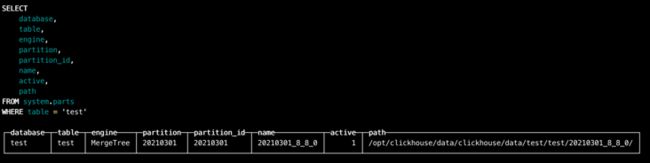
从上图中可以看到test表中返回了一条partitionid为20210301的数据分区的记录,从name字段中我们可以得知,此分区的目录名为20210301_8_8_0。 20210301_8_8_0这个目录名字到底有什么含义呢?下面来介绍一下分区规则以及分区目录的命名规则。
2.2.1 数据分区ID生成规则
数据分区规则由分区ID决定,分区ID由PARTITION BY分区键决定。根据分区键字段类型,ID生成规则可分为:
未定义分区键
没有定义PARTITION BY,默认生成一个目录名为all的数据分区,所有数据均存放在all目录下。
整型分区键
分区键为整型,那么直接用该整型值的字符串形式做为分区ID。
日期类分区键
分区键为日期类型,或者可以转化成日期类型。
其他类型分区键
String、Float类型等,通过128位的Hash算法取其Hash值作为分区ID。
上面我们插入一条日期为2021-03-01 00:00:00的数据,对该字段格式化后生成的数据分区id就是20210301。
2.2.2 数据分区目录命名规则
目录命名规则如下:
PartitionId_MinBlockNum_MaxBlockNum_LevelPartitionID
分区id,例如20210301。
MinBlockNum
最小分区块编号,自增类型,从1开始向上递增。每产生一个新的目录分区就向上递增一个数字。
MaxBlockNum
最大分区块编号,新创建的分区MinBlockNum等于MaxBlockNum的编号。
Level
合并的层级,被合并的次数。合并次数越多,层级值越大。
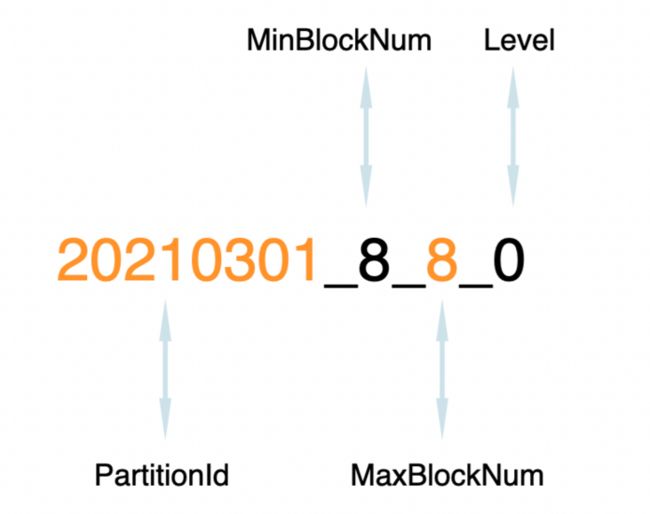
从上图可知,此分区的分区id为20210301,当前分区的MinBlockNum和MinBlockNum均为8,而level为0,表示此分区没有合并过。
2.3 数据分区文件组织结构
在了解了分区目录名字的生成规则后,下面来看看数据分区目录下的文件组织结构。以2021030188_0分区为例:
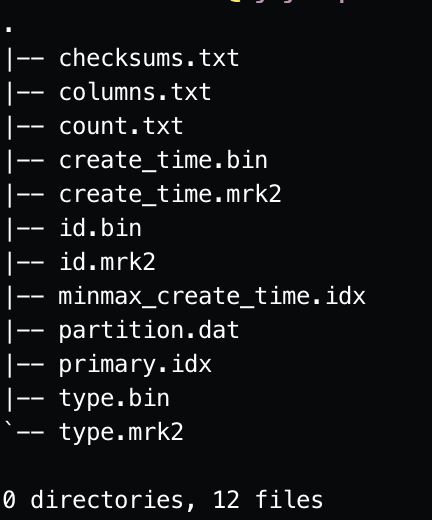
从图中可以看到,目录中的文件主要包括bin文件、mrk文件、primary.idx文件以及其他相关文件。
bin文件
数据文件,存储的是某一列的数据。数据表中的每一列都对应一个与其字段名相同的bin文件,例如id.bin存储的是表test中id列的数据。
mrk文件
标记文件,每一列都对应一个与其字段名相同的标记文件,标记文件在idx索引文件和bin数据文件之间起到了桥梁作用。以mrk2结尾的文件,表示该表启用了自适应索引间隔。
primary.idx文件
主键索引文件,用于加快查询效率。
count.txt
数据分区中数据总记录数。上述20210301_8_8_0的数据分区中,该文件中的记录总数为1。
columns.txt
表中所有列数的信息,包括字段名和字段类型。
partion.dat
用于保存分区表达式的值。上述20210301_8_8_0的数据分区中该文件中的值为20210301。
minmax_create_time.idx
分区键的最大最小值。
checksums.txt
校验文件,用于校验各个文件的正确性。存放各个文件的size以及hash值。
2.3.1 数据文件
MergeTree中,每列都对应一个bin文件单独存放该列数据。例如,id.bin存放的是id列的数据。所有数据都经过数据压缩、排序,最后以数据块的形式写入bin文件中。 bin中数据以压缩数据块为单位写入文件中。每个数据块由头信息和压缩数据组成。头部信息包括校验和、数据压缩算法、数据压缩前大小和压缩后大小组成。压缩数据由granule组成,granule大小与index_granularity相关。
2.3.2 索引文件
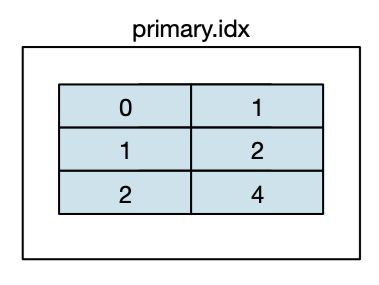
MergeTree索引为稀疏索引,它并不索引单条数据,而是索引一定范围的数据。也就是从已排序的全量数据中,间隔性的选取一些数据记录主键字段的值来生成primary.idx索引文件,从而加快表查询效率。间隔设置参数为index_granularity。
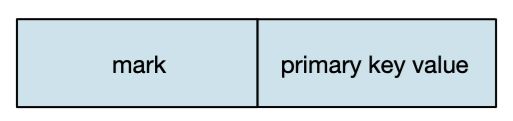
我们向表test中插入9条数据,
insert into test.test(id, type, create_time) VALUES (1, 1, toDateTime('2021-03-01 00:00:00'));
insert into test.test(id, type, create_time) VALUES (1, 2, toDateTime('2021-03-01 00:00:00'));
insert into test.test(id, type, create_time) VALUES (1, 3, toDateTime('2021-03-01 00:00:00'));
insert into test.test(id, type, create_time) VALUES (2, 1, toDateTime('2021-03-01 00:00:00'));
insert into test.test(id, type, create_time) VALUES (2, 1, toDateTime('2021-03-01 00:00:00'));
insert into test.test(id, type, create_time) VALUES (3, 1, toDateTime('2021-03-01 00:00:00'));
insert into test.test(id, type, create_time) VALUES (3, 1, toDateTime('2021-03-01 00:00:00'));
insert into test.test(id, type, create_time) VALUES (4, 1, toDateTime('2021-03-01 00:00:00'));
insert into test.test(id, type, create_time) VALUES (5, 1, toDateTime('2021-03-01 00:00:00'));因为index_granularity设置为4,所以每4条数据就会生成一条索引记录,即使用插入的第1、5、9条数据id字段的值生成索引文件记录。
2.3.3 标记文件
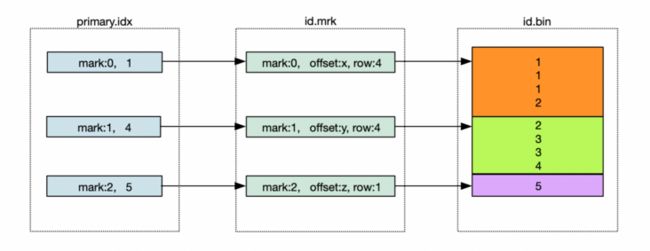
mrk标记文件在primary.idx索引文件和bin数据文件之间起到了桥梁作用。primary.idx文件中的每条索引在mrk文件中都有对应的一条记录。一条记录的组成包括:
offset-compressed bin file
表示指向的压缩数据块在bin文件中的偏移量。
offset-decompressed data block
表示指向的数据在解压数据块中的偏移量。
row counts
代表数据记录行数,小于等于index_granularity所设置的值。

索引,标记和数据文件下图所示:
作者:TalkingData 张凯
参考文档:
1.https://clickhouse.tech/docs
2.http://www.clickhouse.com.cn/...
3.《ClickHouse原理解析与应用实践》(机械工业出版社出版,作者朱凯)