本文首发于:行者AI
随着各行各业数字化的不断推进,AI需要处理的数据越来越多,单一服务器已经难以满足当前产业的发展需求,服务器集群成为企业用AI处理数据的标配硬件,而分布式计算成为人工智能应用的标配软件。
从图1可以看出,现今有很多开源的分布式计算框架,从模型的训练、调参到部署;从NLP、CV到RS;这些框架覆盖到了AI产业生命周期的各个方面。本文就选取其中的Ray框架进行简单的介绍。

图1. 各种分布式计算框架
Ray 是伯克利大学在2017年开源的分布式计算框架,对应的论文是《Ray: A Distributed Framework for Emerging AI Applications》。强化学习任务需要与环境进行大量的交互(毫秒级),且在时间上支持异构性。该框架专门为机器学习与强化学习设计,相较于其他框架,ray具有以下优势:
- 轻量级
- 可快速构建
- 通用性强
- 性能优异
下面就这四个优点为大家进行详细介绍。
1. Ray框架的优势
1.1 轻量级
相较于传统的分布式框架(尤其是hadoop、spark等),Ray可以直接通过pip进行安装,且对系统版本无要求。
pip install -U rayRay是一个简单的分布式策略,而非完整的生态,因而不需要复杂的构建。
另一方面,轻量而优秀的框架往往可以作为企业数据处理的基础框架,企业不断在该框架的基础上增加生态,从而形成企业独有的应用生态。
1.2 可快速构建
如hadoop等传统框架,要对原有的单机程序进行分布式化,需要修改整个代码逻辑,以MapReduce的编程方案重构各个计算模块,这使得hadoop等传统框架有着良好的可编辑性,算法工程师可以根据业务需求进行详细的修改。强大的可编辑性也带来了学习成本高,代码重构困难等诸多问题。人工智能日新月异,模型在不断更迭,敏捷开发成为了很多AI企业的开发模式,AI应用的复杂构建会大大影响整个项目的推进。
如下代码,将一个简单的单机程序函数,转换为Ray分布式的函数,只是在原有函数的基础上加入了ray.remote的装饰器,便完成了分布式化的工作。
### 原始单机代码
def f(x):
return x * x
futures = [f.remote(i) for i in range(4)]
print(ray.get(futures))
### Ray分布式代码
import ray
ray.init()
@ray.remote
def f(x):
return x * x
futures = [f.remote(i) for i in range(4)]
print(ray.get(futures))1.3 通用性强
近年tensorflow、torch等深度学习框架成为人工智能应用的模型框架,考虑到产业应用场景,这些框架都给出了各自分布式训练和部署的方案,且这些方案的计算资源利用率较高。大型的项目往往由数个算法模型组成,为了快速开发,算法工程师往往采用开源的代码构建,而这些开源的代码采用的深度学习框架很可能互不相同,针对单一框架的分布式方案难以适用。
除此之外,ONNIX等为代表的框架,倾向于将所有框架的模型统一到单一的解决方案上,由于很多前沿的深度学习模型对神经元进行了复杂的修改,无法适配到通用的算子上,需要算法工程师手写算子,从而拖慢了开发速度。Ray将机器学习模型、numpy数据计算、单一的函数抽象成通用的计算,实现了对各种深度学习框架、机器学习框架的适配。
另外,Ray对强化学习的应用进行了专门的生态构建。
1.4 性能优异
图2为Ray、Horovod以及tensorflow原生的分布式方案训练ResNet-101模型的比较,纵轴为每秒平均迭代的图片数,可以看出Ray略微优于Horovod框架。

图2. 分布式训练速度比较
图3为Clipper和Ray在模型调用上吞吐量的比较,两者均用同一网络模型,可以看出Ray优于Clipper。

图3. 分布式部署吞吐量比较
Ray并没有做到每个分布式场景都优于其他框架,但Ray集合训练、调参以及部署为一体,仍能保持不错的性能,因而值得学习和使用。
得益于Ray框架良好的性能,Ray广泛用于工业界(如蚂蚁金服),要先学会使用Ray必先了解Ray的构成,下一小节就Ray的构成进行介绍。
2. Ray的使用
2.1 Ray的构成
Ray大致由四部分组成:
Ray涉及了AI应用的整个生命周期:训练、调参、部署,并对强化学习场景进行了专门的优化。由于个人使用经验有限,这里只介绍Ray的Serve模块。
2.2 Ray的启动
如图4,Ray由一个头节点(Head node)和一组工作节点(Worker node)组成。启动Ray需要首先启动头节点,并为工作节点提供头节点的地址以形成集群。头节点负责管理和分配工作节点的任务,工作节点负责执行任务并返回结果。经过测试,头节点和工作节点可以为同一台计算机。
Ray的启动由两个步骤组成:启动头节点、注册工作节点到头节点。
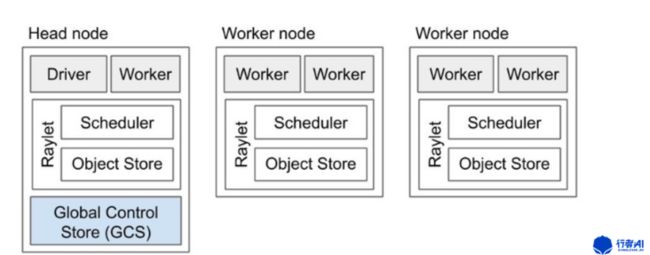
图4. Ray节点示意图
以下是头节点的启动代码和关闭代码。
import ray
ray.init() # 启动
assert ray.is_initialized() == True
ray.shutdown() # 关闭
assert ray.is_initialized() == False注:启动脚本应当加入关闭代码,如果没有,ray程序可能一直在进程中运行。
Ray框架采用Actor模型,相较于传统的共享内存模型,Ray不存在状态竞争、可以方便的组建集群、能更好的控制状态。每个Actor即每个工作节点的注册方式如下。
import ray
ray.init(address=头节点地址) # 启动
assert ray.is_initialized() == True
ray.shutdown() # 关闭
assert ray.is_initialized() == False2.3 Ray Serve
Ray Serve可以类比clipper,主要用于模型的部署服务,并支持多种深度学习框架,官方给出的示例有:
这里以tensorflow2为例,来说一下如何用ray来部署模型服务。
步骤一:定义一个模型服务类
如下是模型服务类的简易代码,和Flask等框架部署AI服务类似。由于Ray使用gRPC作为通信协议,速度更快,Ray还在gRPC基础上进行了优化,有些场景快于原生的gRPC通信。
class TFMnistModel:
def __init__(self, model_path):
import tensorflow as tf
self.model_path = model_path
# 加载模型
self.model = tf.keras.models.load_model(model_path)
async def __call__(self, starlette_request): # 异步调用
# transform HTTP request -> tensorflow input
input_array = np.array((await starlette_request.json())["array"])
reshaped_array = input_array.reshape((1, 28, 28))
# tensorflow input -> tensorflow output
prediction = self.model(reshaped_array)
# 返回结果
# tensorflow output -> web output
return {
"prediction": prediction.numpy().tolist(),
"file": self.model_path
}步骤二:模型部署到Ray Serve
如下代码中,start函数用于启动服务,create_backend函数用于启动模型,create_endpoint函数启动服务。在Ray中,模型和服务是分离的,可以多个服务调用同一个模型,以支持复杂的调用逻辑。
"tf:v1"为模型的名称,"tf_classifier"为服务的名称,route参数为路由,这些参数都可自由定义。
client = serve.start()
client.create_backend("tf:v1", TFMnistModel, TRAINED_MODEL_PATH)
client.create_endpoint("tf_classifier", backend="tf:v1", route="/mnist")步骤三:请求测试
resp = requests.get(
"http://localhost:8000/mnist",
json={"array": np.random.randn(28 * 28).tolist()})
print(resp.json())3. 结语
一个优秀的框架往往包含了众多先进的设计理念。Ray框架在构建时,参考了许多先进的设计理念,如混合调度策略、GCS 管理等等,这些设计理念使得框架本身完善而又先进。Ray广泛用于AI企业的分布式计算场景,从众多框架中脱颖而出,值得学习。