论文:

论文地址:https://dl.acm.org/doi/pdf/10.1145/3340531.3412162
论文题目:《Sample Optimization For Display Advertising》
这篇论文是百度发表在CIKM上面的一篇关于召回模型如何选取训练样本的佳作,主要围绕着怎么在召回任务中构建负样本展开,通过几种方式来确定训练的负样本。在我看来,如果排序阶段是模型的艺术,那么召回阶段就是样本选择的艺术,这篇论文跟我们前面提到的FB的EBR论文的负样本选择有着异曲同工之妙,对于做排序算法的人来看也可以受益匪浅。
一 、背景
一段小故事,之前我问过我们公司做排序算法的一个员工,我问他“排序算法中的负样本怎么选取”,他回答的是“曝光未点击”,我又问他“那么召回模型中的负样本该怎么选呢”,他思考了下“也是曝光未点击”。
这是真真切切我身边发生的事情,在整个推荐系统的全链路中,每个人都会负责自己的模块,有专门做排序算法的,有专门做召回的,虽然都是链路中的一环,但是还是大相径庭的。比如,排序算法中的模型往往更复杂,特征更多,召回中模型会更加简单,特征用的也比较少。当然,除了在模型和特征方面的不同外,两个任务在训练样本的选择上也是有很大的不同的。
在排序算法中,负样本一般情况是选择曝光未点击,虽然曝光未点击不一定是用户不喜欢,但是总体上也较为符合负样本的特质的,而且这部分的样本也很容易获取到。
在召回算法中,我们的负样本该如何选取呢?可以跟排序模型一样选择曝光未点击嘛?
答案是不可以。
有人这时候可能就会问为什么排序模型可以选取曝光未点击,召回就不行呢,未点击的样本不就是天生的负样本吗?
这里给出几个解释:
1.排序算法是优中选优,曝光未点击天生就是负样本,召回算法面对的候选样本太多,鱼龙混杂,更需要具备在更大的数据集中增加自己的“见识”,也就是更需要见见那些曝光没那么高的样本
2.曝光未点击的样本已经是经过召回,排序选出来的系统认为的用户喜欢的物品,也就是说这些样本已经是上一个版本召回模型选出来正样本了,如果我们把这些样本当作新召回模型的负样本,就有矛盾了
3.如果选择曝光未点击的样本作为负样本,那么召回模型就会陷入“一叶障目,不见泰山”的困境,也就是说模型只会鉴别那些高曝光的样本了,对于那些没出现过,少出现的样本,它根本区分不出来这是正样本还是负样本
4.最重要的还是因为实验中,这么做的话效果很差
这里给出的四个原因都是一些经验之谈和看各个博客知道的结论,现在你应该有了一点对于召回模型应该如何选取负样本的猜想了,没错,一般我们对于召回的负样本,都是用随机负采样的方式,这也是大多数做召回算法的人会选择的办法。在fb的ebr论文中还加入了hard sample作为负样本,也就是那些跟正样本比较相近的样本作为负样本,用以增加模型对于正负样本的区分能力。
回过来说一下我们今天要介绍的这篇论文,论文的题目也通过两个单词来告知了这篇论文的主要工作就是:样本的优化,所以我们待着刚刚对于召回样本选取的理解来看看百度是如何进行样本优化的。
二 、广告系统中的一些挑战
首先,我们来看一下整个广告系统的架构图:

总体还是分成召回跟排序两部分,召回会使用itemcf,usercf以及神经网络等多种方式。我们在第一章的时候已经提到了在召回模型是本论文的重点,训练好一个召回模型面临着一下几个挑战:
1.训练数据跟线上数据的分布不一致,也可以称为样本选择偏差问题。由于用户点击的广告只占总广告的一小部分,也就是我们训练只用到的一小部分数据集,但是我们在线上预测的时候是在整个数据集上预测,所以就有了样本选择偏差问题。
2.长尾分布问题。这个问题不管是在推荐系统还是广告系统中都是存在的,在广告系统中bid price高的广告会占据很大的曝光,有一些bid price很高的物品也会被标记为负样本,这就会导致这些原本定义上是正样本的广告被当成了负样本,这样这些广告的曝光点击自然就降低了,平台赚的钱也就少了。
3.曝光未点击的广告不一定是用户不喜欢的。
4.数据稀疏问题。正负样本比例太大
针对这些问题,百度提出了几种样本优化的方法。
三、样本优化的方法
3.1 Weighted Random Negative Sampling
一般可以对一个正样本通过随机负采样的方法选取k个负样本,但是由于数据呈长尾分布,所以百度采用的是加权的随机负采样,也叫做分片加权负采样:a piece-wise weighted negative sampling method,具体而言:
我们根据广告的曝光频率,以为分解点,把广告分成两部分,然后我们随机生成一个0到1之间的随机数p,如果p < ,我们就从中随机选取一个广告作为负样本,其中
如果p > ,从中基于一元模型分布(unigram distribution)采样一个负样本广告,具体的采样概率如下:

跟word2vec中的采样一样。
由于Al的数量远大于Ah的数量,与原始的负采样方法相比,我们的策略在保留原始属性的同时显着减少了内存使用。
3.2 Real-Negative Subsampling
在百度的凤巢系统统计中,总的ctr值大概只有0.03%,少数的头部广告会占据很大的曝光,它们可能同时出现在正样本(曝光并点击)和真实负样本(曝光但未点击)中。 我们不希望这些头部广告过多出现在负样本中,因为它们通常具有很高的商业价值,所以会对这些头部广告的负样本进行降采样,具有高曝光的广告的负样本,基于以下的概率进行抛弃:

f是曝光的频率,也就是说曝光越多的广告的p就越大,那么它从负样本集合中被抛弃的概率就越大。
实验中也证明了,这种样本优化方法可以显着改善离线召回率和在线CPM指标。
3.3 Sample refinement with PU Learning
对于曝光为点击的样本,我们之前在第一章中已经说了,是不能直接拿来作为召回的负样本的,那么如果这真的要使用这些样本,应该怎么做呢,来看看百度的处理方式吧。
由于曝光未点击的广告我们并不能直接的定性为真正的负样本,所以百度将样本划分为了标记的样本 (点击的广告,这部分已经完全的确定了是正样本),另一部分为未标记样本,这部分由可靠的负样本和有可能是正样本的广告组成。百度要做的就是针对未标记的样本,将真正的负样本从中划分出来。
使用的方法是"spy technique":

具体而言:
1.从正样本集合P中选取spy set:S,然后把S加入到为标记的集合U中
2.正样本集合P剔除S后的样本作为正样本,的样本作为负样本,然后训练一个SVM分类模型
3.用训练好的SVM分类器给U中的样本打分,看看这些样本有多大的概率称为正样本
4. 计算spy set中样本的平均点击率
5.将U中点击率小于spy set平均点击率的样本的作为真正的负样本RN
最后即用RN和P来训练召回模型。
可以看到百度针对我们在前面说的不能把曝光未点击的广告直接作为负样本的改进方法是:选取那些真正的负样本。
3.4 Fuzzy Positive Sample Augmentation
为了缓解数据稀缺问题,百度引入了模糊逻辑来增加正样本。 在最终广告列表中,仅向用户显示前几个广告,而其余的则可能不会显示。 尽管这些隐藏的广告不能直接用作训练样本,但它们已经通过了候选集生成和排序阶段,并且更有可能满足用户的兴趣。
为了增加正样本,我们解析未显示的事件日志,并在最终列表中收集所有三元组(用户,广告,CPM),并且CPM高于预定义的阈值。 我们将这些三元组(用户,广告,每千次展示费用/出价)称为“模糊的正样本”,并将其添加到正样本的训练集中。 值得注意的是,由于模糊正样本的标签不是单击记录,因此其标签小于1。
这个做法跟FB在ebr中的做法一样,通过把曝光的物品也作为正样本太扩大正样本集。
3.5 Sampling with Noise Contrastive Estimation (NCE)
NCE论文中详细的描述了如何构建生成模型来生成负样本,感兴趣的可以自己去看看这论文,这里简单的说一下百度的做法,针对每个正样本,我们生成k=5的负样本来扩大训练集。
关于这种方法,本人觉得还是不太靠谱,因为负样本的选取在广告或者推荐中都有很大的选择空间,还不至于用到NCE来人工生成负样本。
四、实验结果
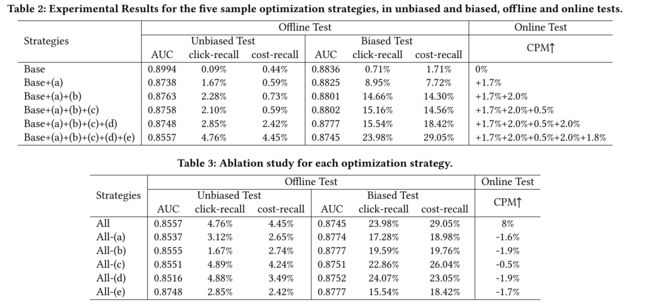
评价标准是:


可以看到如果用上所有的方法后,auc是不断减少,CPM是增加的,这也说明了这些样本方法的叠加可以带来收益上的提升。