前言
我们用两篇文章介绍了树的相关概念,分别介绍了树的概述,将树与数组和链式的存储结构做了相应的对比;然后又介绍了二叉树的相关概念,包括满二叉树和完全二叉树的相关概念,接着介绍了二叉树的遍历和实现,其中包括二叉树指定节点的查找、二叉树叶子节点和非叶子节点删除。最后还介绍了顺序存储二叉树、线索二叉树的相关操作。本文开始给大家介绍树的具体应用。主要的应用包括堆排序、赫夫曼树、赫夫曼编码、二叉排序树、平衡二叉树以及最后的多路查找树,其中包括B树以及B+树。首先给大家详细介绍堆排序。
一、堆排序
其实,我们在前面介绍的排序算法中介绍过堆排序,为了本文的完整性,我们通过另外一种方式实现堆排序。
1、堆排序基本介绍
堆排序是利用堆这种数据结构而设计的一种排序算法,堆排序其实是一种选择排序,它的最坏、最好、平均时间复杂度均为O(nlogn),它是一种不稳定排序。其实堆是具有以下的完全二叉树的性质:
- 1、每个结点的值均大于或等于其左右孩子结点的值,称为大顶堆。
- 没有要求结点的左孩子的值和有孩子的值大小关系
- 每个结点的值都小于或等于其左右孩子结点的值,称为小顶堆。
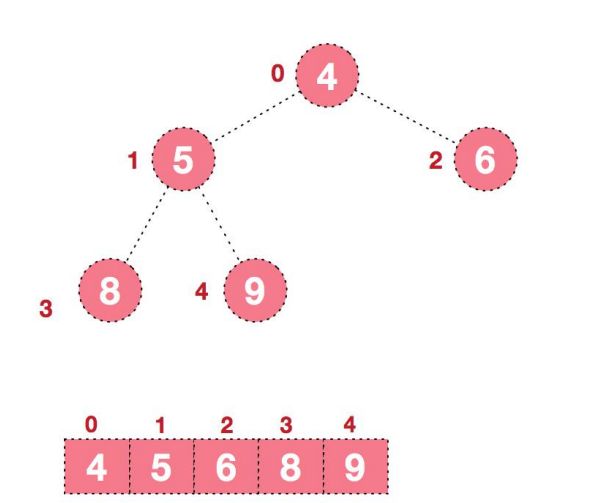
以下就是大顶堆:
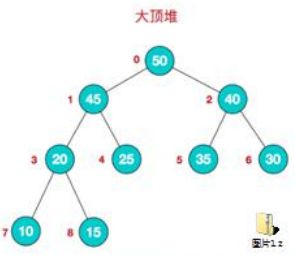
我们对堆中的结点按层次进行编号,映射到数组中具体如下:

同理,以下是小顶堆:
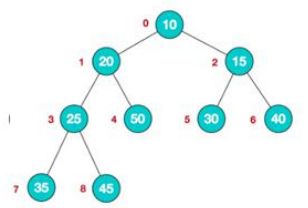
小顶堆。
2、堆排序基本思想
堆排序的基本思想是:
- 1、将待排序序列构造大顶堆
- 2、此时,整个序列的最大值就是堆顶的根节点
- 3、将其与末尾元素进行交换,此时末尾就为最大值
- 4、然后将剩余
n - 1个元素重新构造成一个堆,这样会得到n个元素的次小值。如此反复执行,便可以得到一个有序的数列。
其实在上述的思想叙述中,可以得出在构建大顶堆的过程中,元素的个数逐渐减少,最后得到一个有序序列了。
3、堆排序步骤图解说明
我们通过一个案例来说明堆排序的步骤。我们的以数组 {4,6,5,8,9},我们接下来将数组进行升序排序:
1、构造初始堆。将给定无序序列构造成一个大顶堆(一般升序采用大顶堆,降序采用小顶堆)。
-
2、假设给定无序序列结构如下:
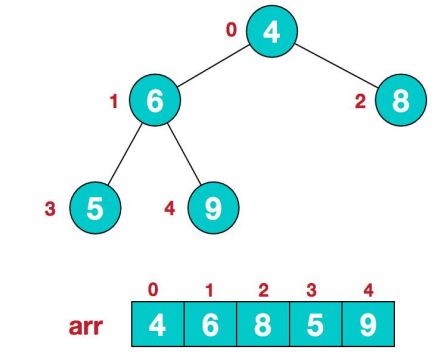
-
3、此时我们从最后一个非叶子节点开始,从左到右,从下到上进行调整。具体过程如下:
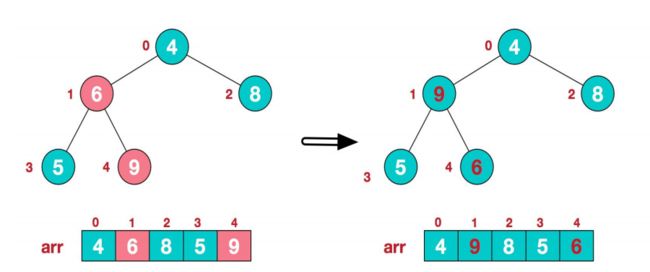
-
4、找到第二个非叶子结点
4,由于[4,9,8]中9元素最大,4和9交换,结果如下:
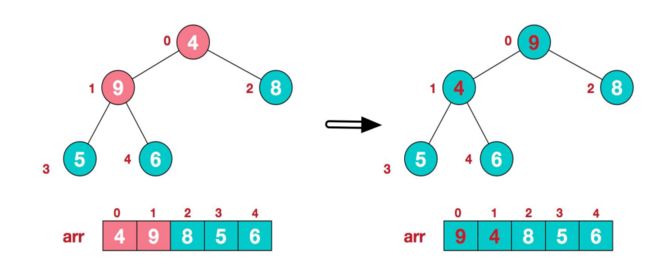
-
这时我们继续交换,导致了子根
[4,5,6]结果混乱,继续调整,交换4和6。
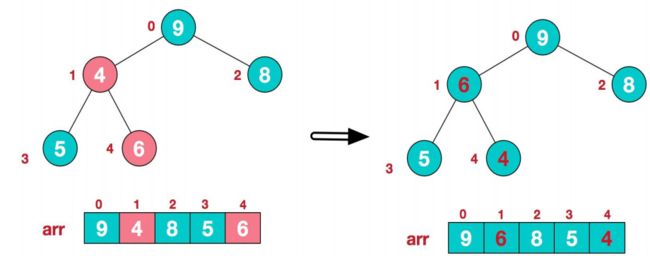
此时,我们就将一个无序序列构造了一个大顶堆。 将堆顶元素与末尾元素进行交换,使末尾元素最大。然后继续调整堆,再将堆元素与末尾元素交换,得到第二大元素。如此反复进行交换、重建、交换。
-
1、将堆顶元素9和末尾元素4进行交换,具体过程如下:
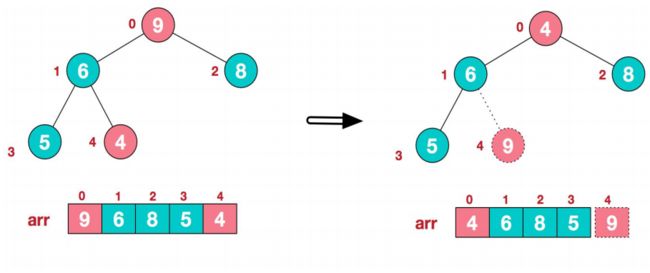
-
重新调整结构,使其继续满足堆定义。
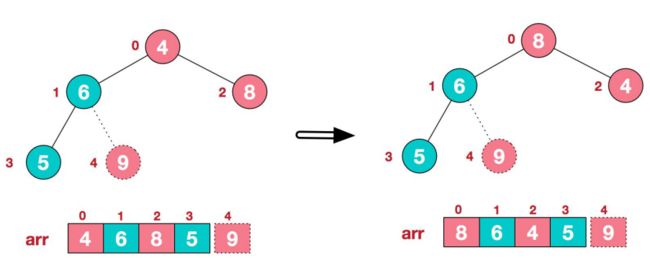
-
再将堆顶元素8与末尾元素5进行交换,得到第二大元素8.

-
后序过程继续进行调整、交换,如此反复进行,最终使得整个序列有序。
因此,通过上面的建立堆得过程,我们不难发现堆排序的基本思路:
- 1、将无序序列构建一个堆,根据升序降序需求选择大顶堆或者小顶堆
- 2、将堆顶元素与末尾元素交换,将最大元素“称”到数组末端
- 3、重新调整结构,使其满足堆定义,然后继续交换堆顶元素与当前末尾元素,反复执行调整,然后交换步骤,使得整个数组整体有序。
4、堆排序代码实现
通过上述我们的排序过程的演示,接下来,通过java代码实现堆排序,具体代码如下:
import java.text.SimpleDateFormat;
import java.util.Arrays;
import java.util.Date;
public class HeapSort {
public static void main(String[] args) {
int[] arr = new int[8000000];
for (int i = 0; i < 8000000; i++) {
arr[i] = (int) (Math.random() * 8000000); // 生成一个[0, 8000000) 数
}
System.out.println("排序前");
Date data1 = new Date();
SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
String date1Str = simpleDateFormat.format(data1);
System.out.println("排序前的时间是=" + date1Str);
heapSort(arr);
Date data2 = new Date();
String date2Str = simpleDateFormat.format(data2);
System.out.println("排序前的时间是=" + date2Str);
}
public static void heapSort(int arr[]) {
int temp = 0;
System.out.println("堆排序!!");
for(int i = arr.length / 2 -1; i >=0; i--) {
adjustHeap(arr, i, arr.length);
}
for(int j = arr.length-1;j >0; j--) {
//交换
temp = arr[j];
arr[j] = arr[0];
arr[0] = temp;
adjustHeap(arr, 0, j);
}
}
public static void adjustHeap(int arr[], int i, int lenght) {
int temp = arr[i];//先取出当前元素的值,保存在临时变量
for(int k = i * 2 + 1; k < lenght; k = k * 2 + 1) {
if(k+1 < lenght && arr[k] < arr[k+1]) { //说明左子结点的值小于右子结点的值
k++; // k 指向右子结点
}
if(arr[k] > temp) { //如果子结点大于父结点
arr[i] = arr[k]; //把较大的值赋给当前结点
i = k; //!!! i 指向 k,继续循环比较
} else {
break;//!
}
}
arr[i] = temp;//将temp值放到调整后的位置
}
}
具体的执行效果如下:
二、赫夫曼树
给定n个权值作为n个叶子节点,构成一颗二叉树,若该树的带权路径长度达到最小,称这样的二叉树为最优二叉树,也称为哈弗曼树。在赫夫曼树是带权路径长度最短的树。权值较大的结点离根较近。接下来介绍赫夫曼树中常用的常用术语:
路径和路径长度:在一棵树中,从一个节点可以到达孩子或孙子结点之间的通路称为路径。通路中分支数目称为路径长度。通常情况下:根节点的层数为1,则从根节点到第L层的路径长度为L-1。
结点的权及带权路径长度:若将树中结点赋给一个有着某个含义的值,则这个数值称为该节点的权。结点的带权路径长度为:从根节点到该节点之间的路径长度为:从根节点到该节点之间的路径长度与该节点的权的乘积。
树的带权路径长度:树的带权路径长度规定为:所有叶子节点的带权路径长度之和,记为WPL(weighted path length),权值越大的结点离根节点越近的二叉树才是最优的二叉树。
WPL最小的就是赫夫曼树,具体计算如下:
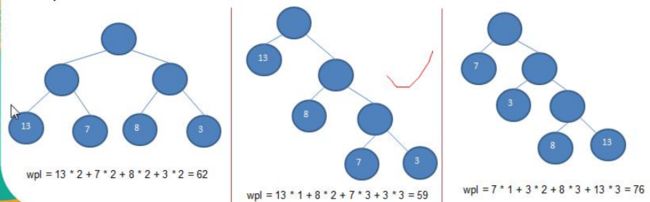
赫夫曼树的创建过程如下:
- 1、 从小到大进行排序, 将每一个数据,每个数据都是一个节点 , 每个节点可以看成是一颗最简单的二叉树
- 2、 取出根节点权值最小的两颗二叉树
- 3、组成一颗新的二叉树, 该新的二叉树的根节点的权值是前面两颗二叉树根节点权值的和
- 4、再将这颗新的二叉树,以根节点的权值大小 再次排序, 不断重复 1-2-3-4 的步骤,直到数列中,所有的数据都被处理,就得到一颗赫夫曼树
具体的哈弗曼树如下图所示:
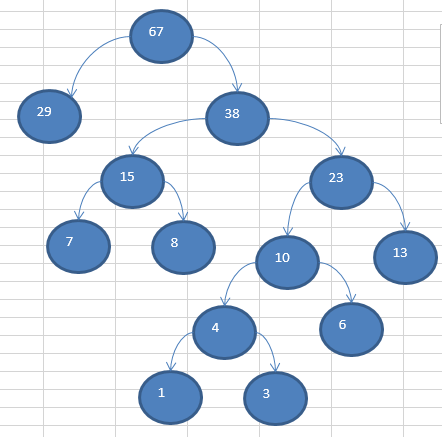
根据上述的哈弗曼树构建的过程,我们用java代码实现如下:
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
public class HuffmanTree {
public static void main(String[] args) {
int arr[] = { 13, 7, 8, 3, 29, 6, 1 };
Node root = createHuffmanTree(arr);
preOrder(root);
}
public static void preOrder(Node root) {
if(root != null) {
root.preOrder();
}else{
System.out.println("是空树,不能遍历~~");
}
}
public static Node createHuffmanTree(int[] arr) {
List nodes = new ArrayList();
for (int value : arr) {
nodes.add(new Node(value));
}
while(nodes.size() > 1) {
Collections.sort(nodes);
System.out.println("nodes =" + nodes);
Node leftNode = nodes.get(0);
//(2) 取出权值第二小的结点(二叉树)
Node rightNode = nodes.get(1);
//(3)构建一颗新的二叉树
Node parent = new Node(leftNode.value + rightNode.value);
parent.left = leftNode;
parent.right = rightNode;
//(4)从ArrayList删除处理过的二叉树
nodes.remove(leftNode);
nodes.remove(rightNode);
//(5)将parent加入到nodes
nodes.add(parent);
}
//返回哈夫曼树的root结点
return nodes.get(0);
}
}
class Node implements Comparable {
int value; // 结点权值
char c; //字符
Node left; // 指向左子结点
Node right; // 指向右子结点
public void preOrder() {
System.out.println(this);
if(this.left != null) {
this.left.preOrder();
}
if(this.right != null) {
this.right.preOrder();
}
}
public Node(int value) {
this.value = value;
}
@Override
public String toString() {
return "Node [value=" + value + "]";
}
@Override
public int compareTo(Node o) {
// TODO Auto-generated method stub
// 表示从小到大排序
return this.value - o.value;
}
}
执行的结果如图所示:
三、哈夫曼编码
哈夫曼编码也叫赫夫曼编码,是一种编码方式,属于一种程序算法。赫夫曼编码是哈弗曼树在电讯通信中的经典应用之一。当然哈夫曼编码广泛应用于数据文件压缩,一般压缩在20%到90%之间。哈弗曼编码是可变长的一种,称为最佳编码。在通讯域中信息的处理方式1-定长编码,假如传输的字符串如下:
- i like like like java do you like a java
d:1y:1u:1j:2v:2o:2l:4k:4e:4i:5a:5 // 各个字符对应的个数- 按照上面字符出现的次数构建一颗赫夫曼树, 次数作为权值
构成赫夫曼树的步骤如下:
- 从小到大进行排序, 将每一个数据,每个数据都是一个节点 , 每个节点可以看成是一颗最简单的二叉树
- 取出根节点权值最小的两颗二叉树
- 组成一颗新的二叉树, 该新的二叉树的根节点的权值是前面两颗二叉树根节点权值的和
- 再将这颗新的二叉树,以根节点的权值大小再次排序, 不断重复 1-2-3-4 的步骤,直到数列中,所有的数据都被处理,就得到一颗赫夫曼树
形成的赫夫曼树如下图所示:
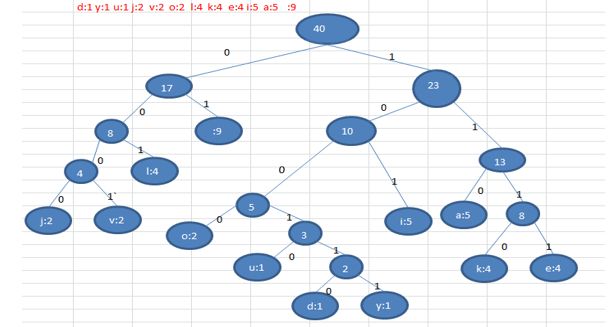
4) 根据赫夫曼树,给各个字符,规定编码 (前缀编码), 向左的路径为0 向右的路径为1 , 编码如下:
o: 1000 u: 10010 d: 100110 y: 100111 i: 101 a : 110 k: 1110
e: 1111 j: 0000 v: 0001 l: 001 : 01
5) 按照上面的赫夫曼编码,我们的"i like like like java do you like a java" 字符串对应的编码为 (注意这里我们使用的无损压缩)
1010100110111101111010011011110111101001101111011110100001100001110011001111000011001111000100100100110111101111011100100001100001110
通过赫夫曼编码处理 长度为 133
6) 长度为 : 133
说明:
原来长度是 359 , 压缩了 (359-133) / 359 = 62.9%
此编码满足前缀编码, 即字符的编码都不能是其他字符编码的前缀,不会造成匹配的多义性赫夫曼编码是无损处理方案。
不过需要我们注意的是:这个赫夫曼树根据排序方法不同,也可能不太一样。这样对应的赫夫曼编码也不完全一样,但是wpl是一样的,都是最小的,最后生成的赫夫曼编码的长度是一样的。例如:如果我们让每次生成的新的二叉树总是排在权值相同的二叉树最后一个,则生成的二叉树如下图:
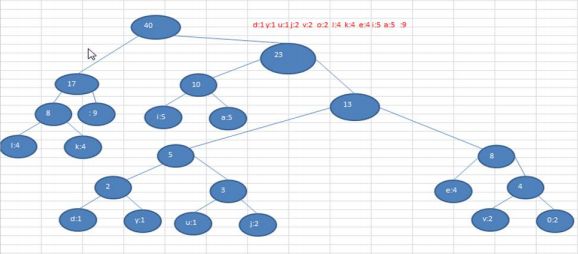
总结
我们前面用两篇文章介绍了树的相关概念,分别介绍了树的概述,将树与数组和链式的存储结构做了相应的对比;然后又介绍了二叉树的相关概念,包括满二叉树和完全二叉树的相关概念,接着介绍了二叉树的遍历和实现,其中包括二叉树指定节点的查找、二叉树叶子节点和非叶子节点删除。另外,还介绍了顺序存储二叉树、线索二叉树的相关操作。本文给大家介绍了树的应用,包括堆排序、哈弗曼树和哈夫曼编码。其实数据结构与算法是特别重要的,在编程中有至关重要的地位,因此,需要我们特别的掌握。生命不息,奋斗不止,我们每天努力,好好学习,不断提高自己的能力,相信自己一定会学有所获。加油!!!