Prometheus 简介
Prometheus 是一套开源的系统监控报警框架。它启发于 Google 的 borgmon 监控系统,由工作在 SoundCloud 的 google 前员工在 2012 年创建,作为社区开源项目进行开发,并于 2015 年正式发布。2016 年,Prometheus 正式加入 Cloud Native Computing Foundation,成为受欢迎度仅次于 Kubernetes 的项目。
作为新一代的监控框架,Prometheus 具有以下特点:
强大的多维度数据模型,时间序列数据通过 metric 名和键值对来区分。
所有的 metrics 都可以设置任意的多维标签,数据模型更随意,不需要刻意设置为以点分隔的字符串。
可以对数据模型进行聚合,切割和切片操作,支持双精度浮点类型,标签可以设为全 unicode。
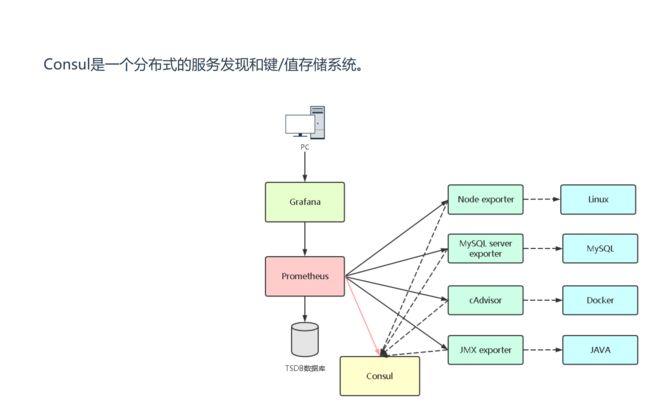
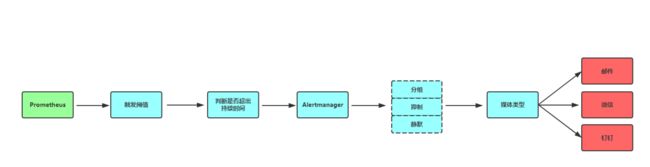
下面这张图说明了Prometheus的整体架构,以及生态中的一些组件作用:
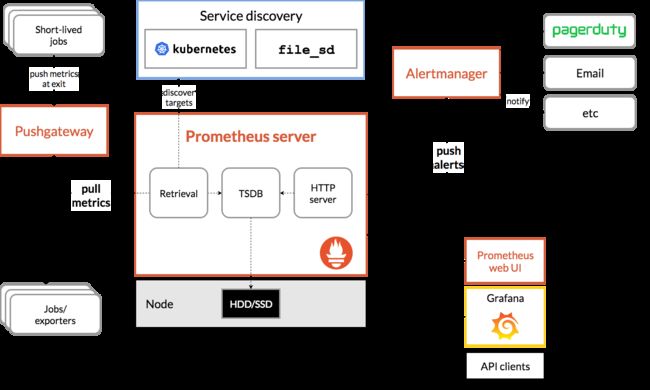
Prometheus可以直接通过目标拉取数据,或者间接地通过中间网关拉取数据。它在本地存储抓取的所有数据,并通过规则从现有数据中聚合记录新的时间序列或者产生警告,Grafana 和其他API可用于可视化收集的数据。
在上面流程中,Prometheus通过配置文件中指定的服务发现方式来确定要拉取监控指标的目标(Target),接着从要拉取的目标(应用容器和Pushgateway)发起HTTP请求到特定的端点(Metric Path),将指标持久化至本身的TSDB中,TSDB最终会把内存中的时间序列压缩落到硬盘,除此之外,Prometheus会定期通过PromQL计算设置好的告警规则,决定是否生成告警到Alertmanager,后者接收到告警后会负责把通知发送到邮件或企业内部群聊中
Prometheus 组成及架构
Prometheus 生态圈中包含了多个组件,其中许多组件是可选的:
Prometheus Server: 用于收集和存储时间序列数据。
Client Library: 客户端库,为需要监控的服务生成相应的 metrics 并暴露给 Prometheus server。当 Prometheus server 来 pull 时,直接返回实时状态的 metrics。
Push Gateway: 主要用于短期的 jobs。由于这类 jobs 存在时间较短,可能在 Prometheus 来 pull 之前就消失了。为此,这次 jobs 可以直接向 Prometheus server 端推送它们的 metrics。这种方式主要用于服务层面的 metrics,对于机器层面的 metrices,需要使用 node exporter。
Exporters: 用于暴露已有的第三方服务的 metrics 给 Prometheus。
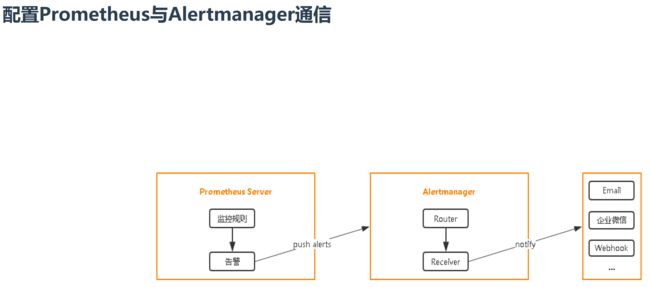
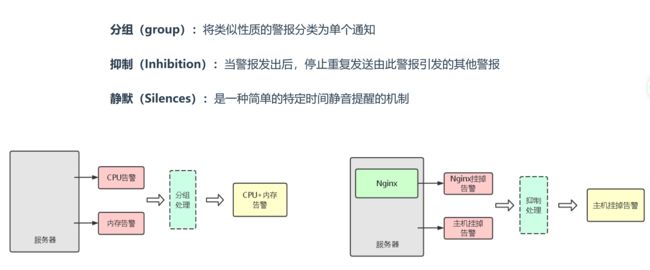
Alertmanager: 从 Prometheus server 端接收到 alerts 后,会进行去除重复数据,分组,并路由到对收的接受方式,发出报警。常见的接收方式有:电子邮件,pagerduty,OpsGenie, webhook 等。
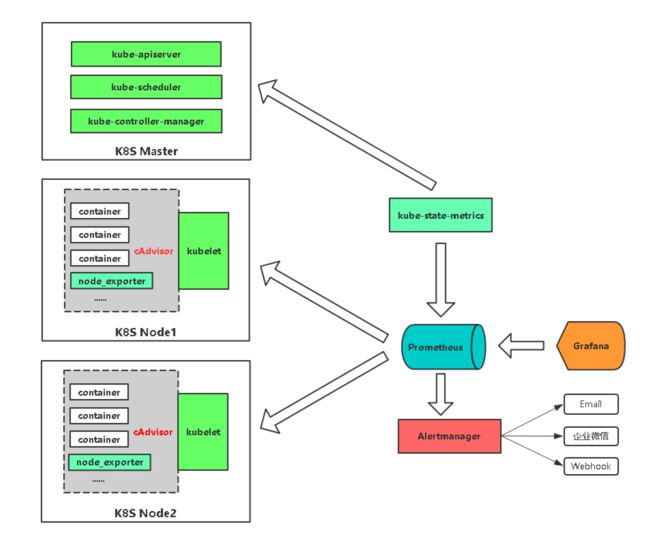
Prometheus 架构图
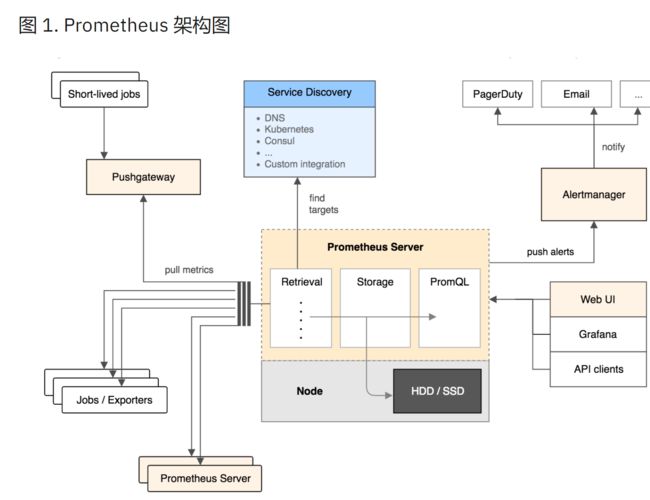
从上图可以看出,Prometheus 的主要模块包括:Prometheus server, exporters, Pushgateway, PromQL, Alertmanager 以及图形界面。.
其大概的工作流程是:
Prometheus server 定期从配置好的 jobs 或者 exporters 中拉 metrics,或者接收来自 Pushgateway 发过来的 metrics,或者从其他的 Prometheus server 中拉 metrics。Prometheus server 在本地存储收集到的 metrics,并运行已定义好的 alert.rules,记录新的时间序列或者向 Alertmanager 推送警报。Alertmanager 根据配置文件,对接收到的警报进行处理,发出告警。在图形界面中,可视化采集数据。
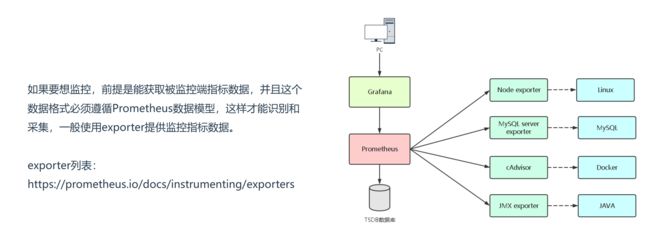


grafana一般是和一些时间序列数据库进行配合来展示数据的,例如:Graphite、OpenTSDB、InfluxDB等
grafana是用于可视化大型测量数据的开源程序,他提供了强大和优雅的方式去创建、共享、浏览数据。dashboard中显示了你不同metric数据源中的数据。
grafana最常用于因特网基础设施和应用分析,但在其他领域也有机会用到,比如:工业传感器、家庭自动化、过程控制等等。
granafa默认端口为3000,可以在浏览器中输入http://localhost:3000/
granafa首次登录账户名和密码admin/admin,可以修改
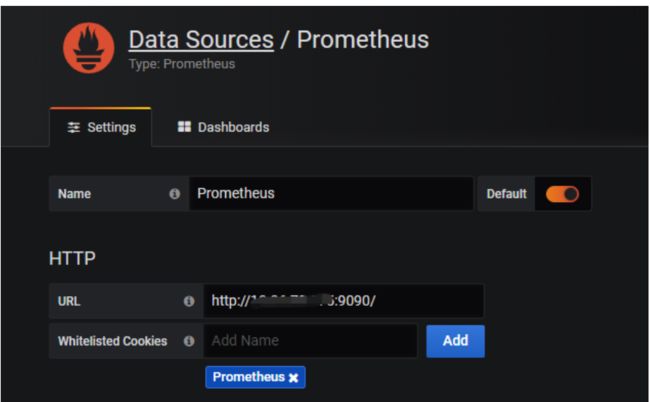
配置数据源Data sources->Add data source -> Prometheus,输入prometheus数据源的信息,主要是输入name和url
添加 Dashboard -> New Dashboard -> Import Dashboard -> 输入11074,导入Linux监控模板. 并配置数据源为Prometheus,即上一步中的name
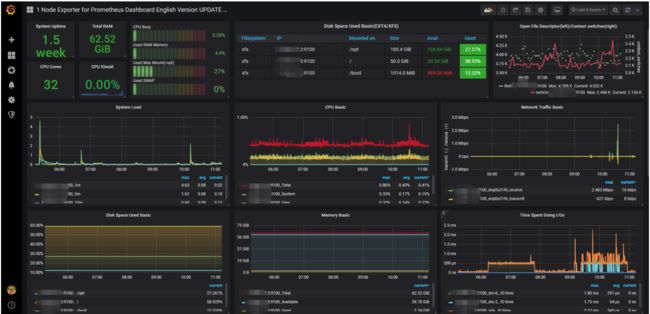
配置完保存后即可看到逼格非常高的系统主机节点监控信息,包括系统运行时间, 内存和CPU的配置, CPU、内存、磁盘、网络流量等信息, 以及磁盘IO、CPU温度等信息。