作者:rickiyang
www.cnblogs.com/rickiyang/p/12178644.html
短链接,通俗来说,就是将长的 URL 网址,通过程序计算等方式,转换为简短的网址字符串。
大家经常会收到一些莫名的营销短信,里面有一个非常短的链接让你跳转。新浪微博因为限制字数,所以也会经常见到这种看着不像网址的网址。短链的兴起应该就是微博限制字数激起了大家的创造力。
如果创建一个短链系统,我们应该做什么呢?
- 将长链接变为短链;
- 用户访问短链接,会跳转到正确的长链接上去。
查找到对应的长网址,并跳转到对应的页面。
短链生成方法
短码一般是由[a - z, A - Z, 0 - 9]这 62 个字母或数字组成,短码的长度也可以自定义,但一般不超过 8 位。比较常用的都是 6 位,6 位的短码已经能有 568 亿种的组合:(26+26+10)^6 = 56800235584,已满足绝大多数的使用场景。
目前比较流行的生成短码方法有:自增id、摘要算法、普通随机数。分布式ID生成器的解决方案总结,这篇也参考看下。
自增 id
该方法是一种无碰撞的方法,原理是,每新增一个短码,就在上次添加的短码 id 基础上加 1,然后将这个 10 进制的 id 值,转化成一个 62 进制的字符串。
一般利用数据表中的自增 id 来完成:每次先查询数据表中的自增 id 最大值 max,那么需要插入的长网址对应自增 id 值就是 max+1,将 max+1 转成 62 进制即可得到短码。
但是短码 id 是从一位长度开始递增,短码的长度不固定,不过可以用 id 从指定的数字开始递增的方式来处理,确保所有的短码长度都一致。同时,生成的短码是有序的,可能会有安全的问题,可以将生成的短码 id,结合长网址等其他关键字,进行 md5 运算生成最后的短码。
摘要算法
摘要算法又称哈希算法,它表示输入任意长度的数据,输出固定长度的数据。相同的输入数据始终得到相同的输出,不同的输入数据尽量得到不同的输出。
算法过程:
- 将长网址 md5 生成 32 位签名串,分为 4 段, 每段 8 个字节;
- 对这四段循环处理, 取 8 个字节, 将他看成 16 进制串与 0x3fffffff(30 位 1)与操作, 即超过 30 位的忽略处理;
- 这 30 位分成 6 段, 每 5 位的数字作为字母表的索引取得特定字符, 依次进行获得 6 位字符串;
- 总的 md5 串可以获得 4 个 6 位串;取里面的任意一个就可作为这个长 url 的短 url 地址;
这种算法,虽然会生成 4 个,但是仍然存在重复几率。
虽然几率很小,但是该方法依然存在碰撞的可能性,解决冲突会比较麻烦。不过该方法生成的短码位数是固定的,也不存在连续生成的短码有序的情况。
普通随机数
该方法是从 62 个字符串中随机取出一个 6 位短码的组合,然后去数据库中查询该短码是否已存在。如果已存在,就继续循环该方法重新获取短码,否则就直接返回。
该方法是最简单的一种实现,不过由于Math.round()方法生成的随机数属于伪随机数,碰撞的可能性也不小。在数据比较多的情况下,可能会循环很多次,才能生成一个不冲突的短码。
算法分析
以上算法利弊我们一个一个来分析。
如果使用自增 id 算法,会有一个问题就是不法分子是可以穷举你的短链地址的。原理就是将 10 进制数字转为 62 进制,那么别人也可以使用相同的方式遍历你的短链获取对应的原始链接。
打个比方说:http://tinyurl.com/a3300和 http://bit.ly/a3300,这两个短链网站,分别从a3300 - a3399,能够试出来多次返回正确的 url。所以这种方式生成的短链对于使用者来说其实是不安全的。
摘要算法,其实就是 hash 算法吧,一说 hash 大家可能觉得很 low,但是事实上 hash 可能是最优解。比如:http://www.sina.lt/ 和 http://mrw.so/ 连续生成的 url 发现并没有规律,很有可能就是使用 hash 算法来实现。
普通随机数算法,这种算法生成的东西和摘要算法一样,但是碰撞的概率会大一些。因为摘要算法毕竟是对 url 进行 hash 生成,随机数算法就是简单的随机生成,数量一旦上来必然会导致重复。
综合以上,我选择最 low 的算法:摘要算法。
实现
存储方案
数据库存储方案
短网址基础数据采用域名和后缀分开存储的形式。另外域名需要区分 HTTP 和 HTTPS,hash 方案针对整个链接进行 hash 而不是除了域名外的链接。域名单独保存可以用于分析当前域名下链接的使用情况。
增加当前链接有效期字段,一般有短链需求的可能是相关活动或者热点事件,这种短链在一段时间内会很活跃,过了一定时间热潮会持续衰退。所以没有必要将这种链接永久保存增加每次查询的负担。
对于过期数据的处理,可以在新增短链的时候判断当前短链的失效日期,将每天到达失效日期的数据在 HBase 单独建一张表,有新增的时候判断失效日期放到对应的 HBase 表中即可,每天只用处理当天 HBase 表中的失效数据。
数据库基础表如下:
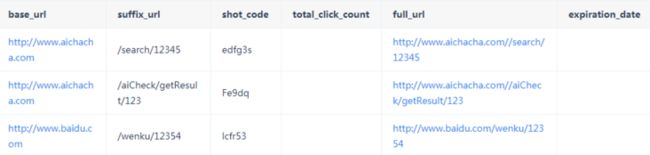
字段释义:
base_url:域名
suffix_url:链接除了域名外的后缀
full_url:完整链接
shot\_code:当前 suffix\_url 链接的短码
expiration_date:失效日期
total\_click\_count:当前链接总点击次数
expiration_date:当前链接失效时间
缓存方案
- 查询需求
个人认为对于几百个 G 的数据量都放在缓存肯定是不合适的,所以有个折中的方案:将最近 3 个月内有查询或者有新增的 url 放入缓存,使用 LRU 算法进行热更新。这样最近有使用的发概率会命中缓存,就不用走库。查不到的时候再走库更新缓存。
- 新增需求
对于新增的链接就先查缓存是否存在,缓存不存在再查库,数据库已经分表了,查询的效率也不会很低。
- 缓存的设计
查询的需求是用户拿着短链查询对应的真实地址,那么缓存的 key 只能是短链,可以使用 KV 的形式存储。
番外
其实也可以考虑别的存储方案,比如 HBase,HBase 作为 NOSQL 数据库,性能上仅次于 redis 但是存储成本比 redis 低很多个数量级,存储基于 HDFS,写数据的时候会先先写入内存中,只有内存满了会将数据刷入到 HFile。
关注微信公众号:Java技术栈,在后台回复:redis,可以获取我整理的 N 篇最新Redis教程,都是干货。
读数据也会快,原因是因为它使用了 LSM 树型结构,而不是 B 或 B+树。HBase 会将最近读取的数据使用 LRU 算法放入缓存中,如果想增强读能力,可以调大 blockCache。
其次,也可以使用 ElasticSearch,合适的索引规则效果不输缓存方案。
是否有分库分表的需要?
对于单条数据 10b 以内,一亿条数据总容量大约为 953G,单表肯定无法撑住这么大的量,所以有分表的需要,如果你对服务很有信心 2 年内能达到这个规模,那么你可以从一开始设计就考虑分表的方案。推荐:大厂在用的分库分表方案,看这篇就够了。
那么如何定义分表的规则呢?
如果按照单表 500 万条记录来算,总计可以分为 20 张表,那么单表容量就是 47G,还是挺大,所以考虑分表的 key 和单表容量,如果分为 100 张表那么单表容量就是 10G,并且通过数字后缀路由到表中也比较容易。可以对 short_code 做 encoding 编码生成数字类型然后做路由。
如何转跳
当我们在浏览器里输入 http://bit.ly/a3300 时
- DNS 首先解析获得 http://bit.ly的
IP地址 - 当
DNS获得IP地址以后(比如:12.34.5.32),会向这个地址发送HTTP`GET请求,查询短码a3300` - [http://bit.ly 服务器会通过短码
a3300获取对应的长 URL - 请求通过
HTTP 301转到对应的长 URL http://www.theaustralian.news...
这里有个小的知识点,为什么要用 301 跳转而不是 302 呐?
知识点:为什么要使用 302 跳转,而不是 301 跳转呢?
301 是永久重定向,302 是临时重定向。短地址一经生成就不会变化,所以用 301 是符合 http 语义的。但是如果用了 301, Google,百度等搜索引擎,搜索的时候会直接展示真实地址,那我们就无法统计到短地址被点击的次数了,也无法收集用户的 Cookie, User Agent 等信息,这些信息可以用来做很多有意思的大数据分析,也是短网址服务商的主要盈利来源。
附上两个算法:
摘要算法:
import org.apache.commons.lang3.StringUtils;
import javax.xml.bind.DatatypeConverter;
import java.security.MessageDigest;
import java.security.NoSuchAlgorithmException;
import java.util.concurrent.atomic.AtomicLong;
import static com.alibaba.fastjson.util.IOUtils.DIGITS;
/**
* @author rickiyang
* @date 2020-01-07
* @Desc TODO
*/
public class ShortUrlGenerator {
public static void main(String[] args) {
String sLongUrl = "http://www.baidu.com/121244/ddd";
for (String shortUrl : shortUrl(sLongUrl)) {
System.out.println(shortUrl);
}
}
public static String[] shortUrl(String url) {
// 可以自定义生成 MD5 加密字符传前的混合 KEY
String key = "dwz";
// 要使用生成 URL 的字符
String[] chars = new String[]{"a", "b", "c", "d", "e", "f", "g", "h",
"i", "j", "k", "l", "m", "n", "o", "p", "q", "r", "s", "t",
"u", "v", "w", "x", "y", "z", "0", "1", "2", "3", "4", "5",
"6", "7", "8", "9", "A", "B", "C", "D", "E", "F", "G", "H",
"I", "J", "K", "L", "M", "N", "O", "P", "Q", "R", "S", "T",
"U", "V", "W", "X", "Y", "Z"
};
// 对传入网址进行 MD5 加密
String sMD5EncryptResult = "";
try {
MessageDigest md = MessageDigest.getInstance("MD5");
md.update((key + url).getBytes());
byte[] digest = md.digest();
sMD5EncryptResult = DatatypeConverter.printHexBinary(digest).toUpperCase();
} catch (NoSuchAlgorithmException e) {
e.printStackTrace();
}
String[] resUrl = new String[4];
//得到 4组短链接字符串
for (int i = 0; i < 4; i++) {
// 把加密字符按照 8 位一组 16 进制与 0x3FFFFFFF 进行位与运算
String sTempSubString = sMD5EncryptResult.substring(i * 8, i * 8 \+ 8);
// 这里需要使用 long 型来转换,因为 Inteper .parseInt() 只能处理 31 位 , 首位为符号位 , 如果不用 long ,则会越界
long lHexLong = 0x3FFFFFFF & Long.parseLong(sTempSubString, 16);
String outChars = "";
//循环获得每组6位的字符串
for (int j = 0; j < 6; j++) {
// 把得到的值与 0x0000003D 进行位与运算,取得字符数组 chars 索引(具体需要看chars数组的长度 以防下标溢出,注意起点为0)
long index = 0x0000003D & lHexLong;
// 把取得的字符相加
outChars += chars[(int) index];
// 每次循环按位右移 5 位
lHexLong = lHexLong >> 5;
}
// 把字符串存入对应索引的输出数组
resUrl[i] = outChars;
}
return resUrl;
}
}数字转为 base62 算法:
/**
* @author rickiyang
* @date 2020-01-07
* @Desc TODO
*
* 进制转换工具,最大支持十进制和62进制的转换
* 1、将十进制的数字转换为指定进制的字符串;
* 2、将其它进制的数字(字符串形式)转换为十进制的数字
*/
public class NumericConvertUtils {
public static void main(String[] args) {
String str = toOtherNumberSystem(22, 62);
System.out.println(str);
}
/**
* 在进制表示中的字符集合,0-Z分别用于表示最大为62进制的符号表示
*/
private static final char[] digits = {'0', '1', '2', '3', '4', '5', '6', '7', '8', '9',
'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm',
'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z',
'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M',
'N', 'O', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z'};
/**
* 将十进制的数字转换为指定进制的字符串
*
* @param number 十进制的数字
* @param seed 指定的进制
* @return 指定进制的字符串
*/
public static String toOtherNumberSystem(long number, int seed) {
if (number < 0) {
number = ((long) 2 \* 0x7fffffff) \+ number + 2;
}
char[] buf = new char[32];
int charPos = 32;
while ((number / seed) > 0) {
buf[--charPos] = digits[(int) (number % seed)];
number /= seed;
}
buf[--charPos] = digits[(int) (number % seed)];
return new String(buf, charPos, (32 \- charPos));
}
/**
* 将其它进制的数字(字符串形式)转换为十进制的数字
*
* @param number 其它进制的数字(字符串形式)
* @param seed 指定的进制,也就是参数str的原始进制
* @return 十进制的数字
*/
public static long toDecimalNumber(String number, int seed) {
char[] charBuf = number.toCharArray();
if (seed == 10) {
return Long.parseLong(number);
}
long result = 0, base = 1;
for (int i = charBuf.length - 1; i >= 0; i--) {
int index = 0;
for (int j = 0, length = digits.length; j < length; j++) {
//找到对应字符的下标,对应的下标才是具体的数值
if (digits[j] == charBuf[i]) {
index = j;
}
}
result += index * base;
base *= seed;
}
return result;
}
}
近期热文推荐:
1.600+ 道 Java面试题及答案整理(2021最新版)
2.终于靠开源项目弄到 IntelliJ IDEA 激活码了,真香!
3.阿里 Mock 工具正式开源,干掉市面上所有 Mock 工具!
4.Spring Cloud 2020.0.0 正式发布,全新颠覆性版本!
觉得不错,别忘了随手点赞+转发哦!