
背景
线上问题:业务系统查询,涉及多表关联查询,条件维度较大且有模糊匹配需求,索引无法覆盖,导致查询性能较低。
解决方向:引入搜索引擎,将数据实时同步到ES,提升查询性能。
具体分析:如果是单表同步到ES,然后在ES进行联合查询,这样不但性能有所损耗,而且增加了查询的复杂度。直接多表关联,将数据拉平后同步到ES,这样在ES查询的性能最高,同时对现有系统改造成本较低。
落地方案:
全量离线同步使用DataX,增量同步使用Canal。
方案揭秘
DataX
DataX的工作原理

DataX本身作为离线数据同步框架,采用Framework + plugin架构构建。将数据源读取和写入抽象成为Reader/Writer插件,纳入到整个同步框架中。
Reader:Reader为数据采集模块,负责采集数据源的数据,将数据发送给Framework。
Writer: Writer为数据写入模块,负责不断向Framework取数据,并将数据写入到目的端。
Framework:Framework用于连接reader和writer,作为两者的数据传输通道,并处理缓冲、流控、并发和数据转换等核心技术问题。
目前已经支持的插件

在我们的实际案例中,我们使用mysql的Reader插件和ES的Writer插件,进行一系列的配置,通过Datax的FrameWork进行数据传输,转换,实现数据同步。
DataX具体的细节,官方讲解较详细,可以点击这里查看官方介绍。
https://github.com/alibaba/DataX/blob/master/introduction.mdgithub.com
Canal
Canal的工作原理
描述Canal工作原理前,先回顾下Mysql的主备复制原理:
MySQL主备复制原理
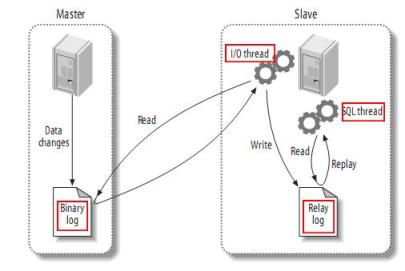
MySQL master 将数据变更写入二进制日志( binary log, 其中记录叫做二进制日志事件binary log events,可以通过 show binlog events 进行查看)。
MySQL slave 将 master 的 binary log events 拷贝到它的中继日志(relay log)。
MySQL slave 重放 relay log 中事件,将数据变更反映它自己的数据。
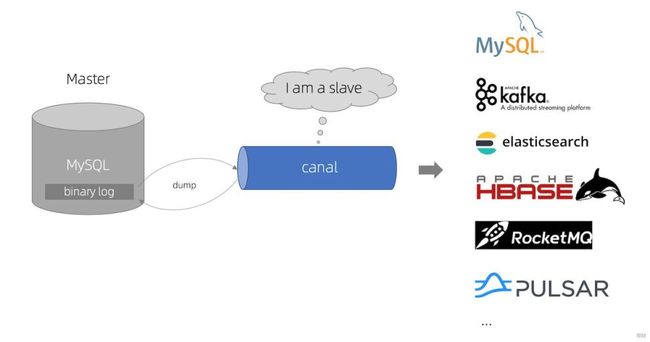
Canal工作原理
Canal 模拟 MySQL slave 的交互协议,伪装自己为 MySQL slave ,向 MySQL master 发送dump 协议
MySQL master 收到 dump 请求,开始推送 binary log 给 slave (即 canal )
Canal 解析 binary log 对象(原始为 byte 流)。
以下描述的实践过程,主要介绍mysql->es多表关联同步的核心过程(以用户表,权限表,用户权限表的场景模拟)。
测试环境:
jdk1.8、python 2.7.1、ES6.3.2
DataX全量同步
DataX的下载
官方提供了两种方式:
直接下载打好的包,下载后直接解压到自己本地的某个目录。
这种方式目前存在问题,里面没有es的插件,需要自己将es的插件进行打包。然后将es的插件安装到DataX中。
a. 打开源码,将elasticsearchwriter模块进行编译,编译后的目录:

b. 打开插件目录{data_home}/plugin/writer
c. 将elasticsearchwriter复制到 datax中
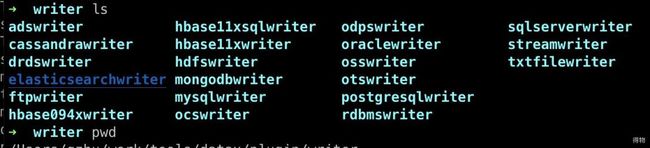
备注:data_home:DataX本地安装目录
下载源码,本地编译,打包。
下载地址:https://github.com/alibaba/DataX
准备job文件
DataX准备好之后,开始准备需要执行的job文件,配置将mysql中的数据同步到es的规则。
打开job目录,编辑job文件,格式为json文件。编辑文件中reader和writer属性部分。
cd {datax_home}/job/
如案例所示:
reader部分:配置插件为mysqlreader,MysqlReader通过JDBC连接器连接到远程的Mysql数据库,并根据用户配置的信息生成查询SELECT SQL语句,然后发送到远程Mysql数据库,并将该SQL执行返回结果使用DataX自定义的数据类型拼装为抽象的数据集,并传递给下游Writer处理。
writer部分:使用elasticsearch的rest api接口, 批量把从reader读入的数据写入elasticsearch。配置中需要注意:reader中querySql中查询的字段和writer中column中的字段必须一一对应,顺序不能错。
datax-user-job.json
{
"job": {
"setting": {
"speed": {
"channel":1
}
},
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "xxx",
"password": "xxx",
"connection": [
{
"querySql": [
"select u.user_id as _id,ur.role_id as role_id,r.id as r_id,u.username as username,u.real_name as real_name,r.name as role_name from sys_user u left join sys_user_role ur on u.user_id = ur.user_id left join sys_role r on ur.role_id = r.id"
],
"jdbcUrl": [
"jdbc:mysql://localhost:3306/test?useUnicode=true&characterEncoding=UTF-8"
]
}
]
}
},
"writer": {
"name": "elasticsearchwriter",
"parameter": {
"endpoint": "http://es-v.elasticsearch.aliyuncs.com:9200",
"accessId": "elastic",
"accessKey": "xxxx",
"index": "kefu_user",
"type": "user_role",
"cleanup": true,
"settings": {"index" :{"number_of_shards": 3, "number_of_replicas": 1}},
"discovery": false,
"batchSize": 1000,
"splitter": ",",
"column": [
{"name": "_id", "type": "id"},
{"name": "r_id", "type": "long"},
{"name": "role_id", "type": "long"},
{ "name": "username","type": "keyword" },
{ "name": "real_name","type": "keyword" },
{ "name": "role_name","type": "keyword" }
]
}
}
}
]
}
}
mysqlreader配置详细介绍
https://github.com/alibaba/DataX/blob/master/mysqlreader/doc/mysqlreader.mdgithub.com
elasticsearchriter配置详细介绍
https://github.com/alibaba/DataX/blob/master/elasticsearchwriter/doc/elasticsearchwriter.mdgithub.com
执行job
执行job,进行全量同步。
打开bin目录
cd {datax_home}/bin
执行
python datax.py /tools/datax/job/datax-user-job.json
结果
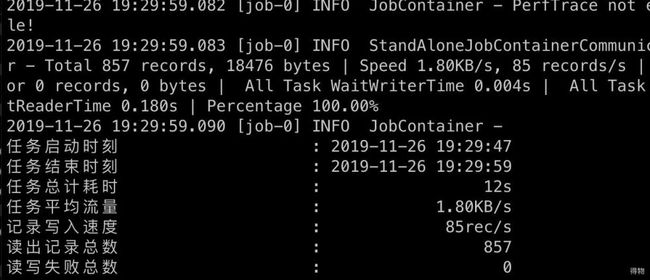
配置较简单,通过这种方式,可以将离线数据从mysql全量同步到es中。
Canal增量同步
Canal server
安装
直接下载对应的压缩包,deployer和adapter,然后解压即可。案例中使用的是V1.1.4,可以点击查看Canal各个版本。
https://github.com/alibaba/canal/releasesgithub.com

提示:
V1.1.2版本官方才支持的ES 适配器
目前官方只支持ES6和ES7的同步,如果需要支持ES5,需要修改源码自己打包。
配置
备注 {canal_deployer_home}指的是canal delpoyer安装目录。
修改配置文件:
vi {canal_deployer_home}/conf/example/instance.properties
主要修改下列参数,配置mysql的连接信息。
# position info
canal.instance.master.address=localhost:3306
canal.instance.dbUsername=xxx
canal.instance.dbPassword=xxx
canal.instance.connectionCharset = UTF-8
启动
打开canal 安装目录。
cd {canal_deployer_home}/bin
sh startup.sh
查看日志
tail -f {canal_deployer_home}/logs/canal/canal.log

tail -f {canal_deployer_home}/logs/example/example.log
通过日志可以看到,Canal服务端启动成功,而且要保持启动状态,不然后续的adaper启动会报错。
CanalAdapter配置
适配器配置分两部分,一部分是总的基础配置,另一部分是同步ES的配置。
备注:{canal_adapter_home} adapter安装目录
Adapter基础配置
打开配置文件目录,编辑配置文件。
cd {canal_adapter_home}/conf/

主要配置源数据库和适配器实例信息,具体如案例所示:
server:
port: 8081
spring:
jackson:
date-format: yyyy-MM-dd HH:mm:ss
time-zone: GMT+8
default-property-inclusion: non_null
canal.conf:
canalServerHost: 127.0.0.1:11111 # 对应单机模式下的canal server的ip:port
batchSize: 500 # 每次获取数据的批大小, 单位为K
syncBatchSize: 1000 # 每次同步的批数量
retries: 0
timeout:
mode: tcp # kafka rocketMQ # canal client的模式: tcp kafka rocketMQ
srcDataSources: # 源数据库
defaultDS: # 自定义名称
url: jdbc:mysql://localhost:3306/test?useUnicode=true # jdbc url
username: xxx
password: xxx
canalAdapters:
- instance: example
groups:
- groupId: g1
outerAdapters:
-
key: exampleKey # canal 实例名或者 MQ topic 名
name: es # or es7
hosts: es-cn-v.elasticsearch.aliyuncs.com:9200 # es 集群地址, 逗号分隔
properties:
mode: rest # or rest # 可指定transport模式或者rest模式
security.auth: xxx:aaaaaa # only used for rest mode
cluster.name: elasticsearch # es cluster name
说明:
目前client adapter数据订阅的方式支持两种,直连canal server或者订阅kafka/RocketMQ的消息。案例中是直连canal server。
ES同步sql配置
适配器将会自动加载conf/es下的所有.yml结尾的配置文件,在目录下创建mytest_user.yml文件。
cd {canal_adapter_home}/conf/es/

编辑mytest_user.yml文件。
dataSourceKey: defaultDS # 源数据源的key, 对应上面配置的srcDataSources中的值
outerAdapterKey: exampleKey # 对应application.yml中es配置的key
destination: example # cannal的instance或者MQ的topic
groupId: # 对应MQ模式下的groupId, 只会同步对应groupId的数据
esMapping:
_index: xx_user # es 的索引名称
_type: user_role # es 的type名称, es7下无需配置此项
_id: _id
upsert: true # es 的_id, 如果不配置该项必须配置下面的pk项_id则会由es自动分配
# pk: _id # 如果不需要_id, 则需要指定一个属性为主键属性
# sql映射
sql: "select u.user_id as _id,ur.role_id as role_id,r.id as r_id,u.username as username,u.real_name as real_name,r.name as role_name from sys_user u left join sys_user_role ur on u.user_id = ur.user_id left join sys_role r on ur.role_id = r.id"
# objFields:
# _labels: array:; # 数组或者对象属性, array:; 代表以;字段里面是以;分隔的
# _obj: object # json对象
# etlCondition: "where a.c_time>='{0}'" # etl 的条件参数
commitBatch: 3000
sql映射说明
sql支持多表关联自由组合, 但是有一定的限制:
主表不能为子查询语句。
只能使用left outer join即最左表一定要是主表。
关联从表如果是子查询不能有多张表。
主sql中不能有where查询条件(从表子查询中可以有where条件但是不推荐, 可能会造成数据同步的不一致, 比如修改了where条件中的字段内容)。
关联条件只允许主外键的'='操作不能出现其他常量判断比如: on a.role_id=b.id and b.statues=1。
关联条件必须要有一个字段出现在主查询语句中比如: on a.role_id=b.id其中的a.role_id 或者b.id必须出现在主select语句中。
Elastic Search的mapping 属性与sql的查询值要一一对应(不支持 select *), 比如: select a.id as _id, a.name, a.email as _email from user, 其中name将映射到es mapping的name field, _email将 映射到mapping的_email field, 这里以别名(如果有别名)作为最终的映射字段. 这里的_id可以填写到配置文件的 _id: _id映射。
常见问题
在实际测试阶段,还是遇到了一些问题,如果要应用到生产上,需要对源码做一定优化。
1. 多表关联部分情况不同步
举例:
用户表
用户角色表
角色表
三表关联查询同步到ES
修改用户表,关联数据修改(用户表)
修改角色表,关联数据会修改(角色表)。
修改用户角色表,关联的数据信息不会更新。
2. 多表关联同步性能问题
看源码,直接将多表关联的sql拆分,将条件前的部分直接包裹,进行全表扫描:

3. DataX全量
date类型,mysql中的字段值为null,同步到es,会赋值为当前时间。
其他类型字段为null时,同步到es会不存在这个字段。
4. Canal Deployer数据源配置
很多文章中的anal.instance.master.address数据库配置都是这种格式:jdbc:mysql://127.0.0.1:3306/mytest?useUnicode=true,这样配置启动会报错。
通过查看源码,可以发现具体原因,代码中针对连接配置是根据“:”分割,获取的地址和端口。
package com.alibaba.otter.canal.instance.spring.support;
import java.beans.PropertyEditorSupport;
import java.net.InetSocketAddress;
import org.apache.commons.lang.StringUtils;
import org.springframework.beans.PropertyEditorRegistrar;
import org.springframework.beans.PropertyEditorRegistry;
public class SocketAddressEditor extends PropertyEditorSupport implements PropertyEditorRegistrar {
public void registerCustomEditors(PropertyEditorRegistry registry) {
registry.registerCustomEditor(InetSocketAddress.class, this);
}
public void setAsText(String text) throws IllegalArgumentException {
String[] addresses = StringUtils.split(text, ":");
if (addresses.length > 0) {
if (addresses.length != 2) {
throw new RuntimeException("address[" + text + "] is illegal, eg.127.0.0.1:3306");
} else {
setValue(new InetSocketAddress(addresses[0], Integer.valueOf(addresses[1])));
}
} else {
setValue(null);
}
}
}
附Canal的全量同步功能ETL
查看源码中发现,Canal实际也是支持ES 的全量同步,进行测试了下,性能要比Datax差一些。
如果有兴趣使用,还是需要注意一些问题。
adapter服务器请求该地址,参数多个,用";"隔开。
curl http://127.0.0.1:8081/etl/es/exampleKey/ticket.yml\?params\="2019-06-01;2019-07-15" -X POST
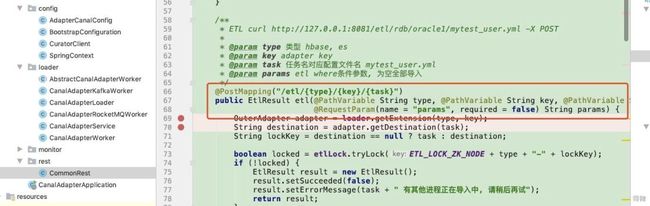
- 注意请求地址中,参数key的赋值。
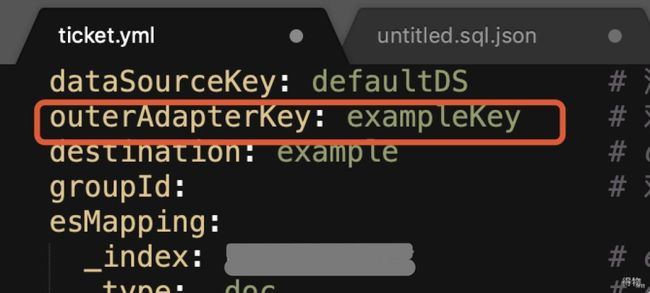
查询条件
如果按时间段分批同步,时间格式需配置这种格式{},也可以通过 where b.created_at BETWEEN {} AND {}。
github中案例描述有瑕疵:

具体原因见源码部分,对条件的解析是替换{},然后顺序赋值。
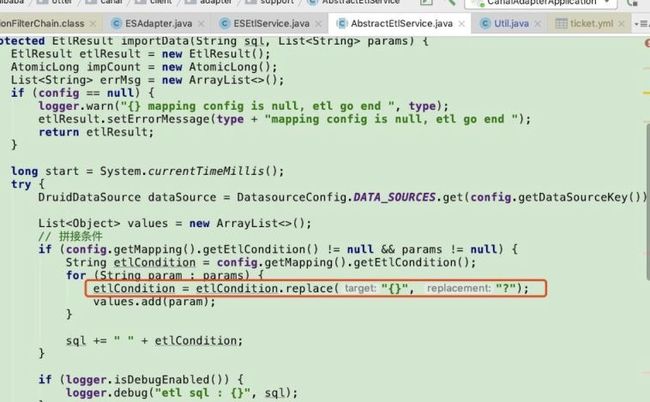
如果按照官网描述传值,会提示异常:
{"succeeded":false,"errorMessage":"ES 数据导入异常 =>java.sql.SQLException: Parameter index out of range (1 > number of parameters, which is 0)."}
相关开源产品
Canal:
https://github.com/alibaba/canalgithub.com
CanalAdapter:
alibaba/canalgithub.com

Sync-ES:
https://github.com/alibaba/canal/wiki/Sync-ESgithub.com
DataX文档:
https://github.com/alibaba/DataX/blob/master/introduction.mdgithub.com