LSTM进行时间序列预测
示例数据下载
点击此处
目标:预测国际航班未来 1 个月的乘客数
数据如图所示
import numpy
import matplotlib.pyplot as plt
from pandas import read_csv
import math
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import LSTM
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import mean_squared_error
导入数据:
# load the dataset
dataframe = read_csv('data/airline-passengers.csv', usecols=[1], engine='python', skipfooter=3)
dataset = dataframe.values
# 将整型变为float
dataset = dataset.astype('float32')
#print(dataframe)
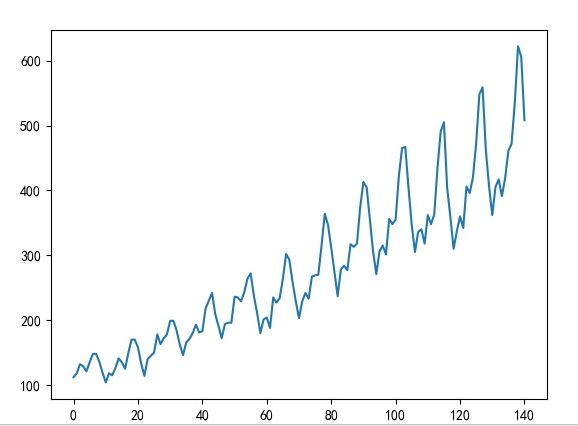
plt.plot(dataset)
#plt.show()
plt.savefig('image/img_show.jpg')
从这 12 年的数据可以看到上升的趋势,每一年内的 12 个月里又有周期性季节性的规律
LSTM进行预测需要的是时序数据 根据前timestep步预测后面的数据
假定给一个数据集
{
A,B,C->D
B,C,D->E
C,D,E->F
D,E,F->G
E,F,G->H
}
这时timestep为3,即根据前三个的数据预测后一个数据的值
所以我们需要对数据进行转化
举一个简单的情况 假设一个list为[1,2,3,4,5],timestep = 2
我们转化之后要达到的效果是

即依据前两个值预测下一个值
对数据进行归一化
LSTM可以不进行归一化的操作,但是这样会让训练模型的loss下降很慢。本教程如果不进行归一化,100次迭代后loss还是很高
#上面代码的片段讲解
scaler = MinMaxScaler(feature_range=(0, 1))
dataset = scaler.fit_transform(dataset)
对数据进行处理
归一化 在下一步会讲解
scaler = MinMaxScaler(feature_range=(0, 1))
dataset = scaler.fit_transform(dataset)
#print(dataset)
train_size = int(len(dataset) * 0.65)
trainlist = dataset[:train_size]
testlist = dataset[train_size:]
print(len(trainlist), len(testlist))
当激活函数为 sigmoid 或者 tanh 时,要把数据正则话,此时 LSTM 比较敏感
设定 67% 是训练数据,余下的是测试数据
# convert an array of values into a dataset matrix
def create_dataset(dataset, look_back=1):
data_X, data_Y = [], []
for i in range(len(dataset)-look_back-1):
a = dataset[i:(i+look_back), 0]
data_X.append(a) # [0.01544401]
b = dataset[i + look_back, 0]
data_Y.append(b) # 0.027027026
return numpy.array(data_X), numpy.array(data_Y)
# use this function to prepare the train and test datasets for modeling
look_back = 1
trainX, trainY = create_dataset(trainlist, look_back)
testX, testY = create_dataset(testlist, look_back)
X=t and Y=t+1 时的数据,并且此时的维度为 [samples, features]
look_back = 1
trainX, trainY = create_dataset(trainlist, look_back)
testX, testY = create_dataset(testlist, look_back)
投入到 LSTM 的 X 需要有这样的结构: [samples, time steps, features],所以做一下变换
# reshape input to be [samples, time steps, features]
trainX = numpy.reshape(trainX, (trainX.shape[0], 1, trainX.shape[1]))
testX = numpy.reshape(testX, (testX.shape[0], 1, testX.shape[1]))
[[[0.6891892 ]]
[[0.71042466]]
.....
[[0.8320464 ]]
[[1. ]]]
建立 LSTM 模型:
输入层有 1 个input,隐藏层有 4 个神经元,输出层就是预测一个值,激活函数用 sigmoid,迭代 100 次,batch size 为 1
# create and fit the LSTM network
model = Sequential()
model.add(LSTM(4, input_shape=(1, look_back)))
model.add(Dense(1))
model.compile(loss='mean_squared_error', optimizer='adam')
model.fit(trainX, trainY, epochs=100, batch_size=1, verbose=2)
model.save(os.path.join("data","Test" + ".h5"))
Epoch 100/100
- 0s - loss: 0.0018
进行预测
model = load_model(os.path.join("data","Test" + ".h5"))
trainPredict = model.predict(trainX)
testPredict = model.predict(testX)
计算误差之前要先把预测数据转换成同一单位
反归一化
trainPredict = scaler.inverse_transform(trainPredict)
trainY = scaler.inverse_transform([trainY])
testPredict = scaler.inverse_transform(testPredict)
testY = scaler.inverse_transform([testY])
计算 mean squared error
trainScore = math.sqrt(mean_squared_error(trainY[0], trainPredict[:,0]))
print('Train Score: %.2f RMSE' % (trainScore))
testScore = math.sqrt(mean_squared_error(testY[0], testPredict[:,0]))
print('Test Score: %.2f RMSE' % (testScore))
Train Score: 21.75 RMSE
Test Score: 46.30 RMSE
画出结果:蓝色为原数据,绿色为训练集的预测值,红色为测试集的预测值
# shift train predictions for plotting
trainPredictPlot = numpy.empty_like(dataset)
trainPredictPlot[:, :] = numpy.nan
trainPredictPlot[look_back:len(trainPredict)+look_back, :] = trainPredict
# shift test predictions for plotting
testPredictPlot = numpy.empty_like(dataset)
testPredictPlot[:, :] = numpy.nan
testPredictPlot[len(trainPredict)+(look_back*2)+1:len(dataset)-1, :] = testPredict
# plot baseline and predictions
plt.plot(scaler.inverse_transform(dataset))
plt.plot(trainPredictPlot)
plt.plot(testPredictPlot)
plt.show()
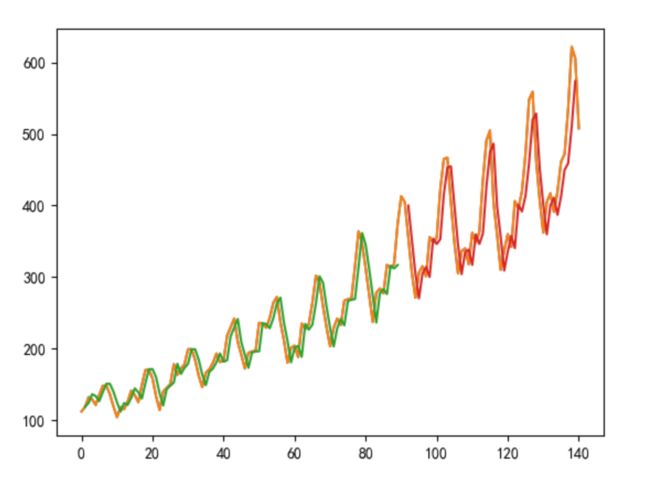
上面的结果并不是最佳的,只是举一个例子来看 LSTM 是如何做时间序列的预测的
可以改进的地方,最直接的 隐藏层的神经元个数是不是变为 128 更好呢,隐藏层数是不是可以变成 2 或者更多呢,time steps 如果变成 3 会不会好一点
参考文献:
简单粗暴LSTM:LSTM进行时间序列预测
用 LSTM 做时间序列预测的一个小例子
用 LSTM 做时间序列预测的一个小例子