一直没有开Python相关的文章。本文从零开始,整理一下Python的基础语法。其余相关内容慢慢增加。内容主要参考新加坡Jamie Chan编写王磊译的《爱上Python》和 俄罗斯Dmitry Zinoviev编写熊子源译的《Python数据科学入门》,以及廖雪峰网站上Python的教学内容。之后会根据《python cookbook》在另一篇博客里记录一些实际用例。
环境配置
macOS上的Python环境
macOS上自带的Python版本是2.7.10,调用的话默认在文件头部加#! /usr/bin(在2018年发布的mbp上似乎自带的就是Python3了)
然后brew install python3之后自己装的Python3命令默认地址是#! /usr/local/bin
更加通用的标准注释方式是
#!/usr/bin/env python3
#coding = utf-8
然后简单的交互调用的话,直接在终端输入python是调用默认的2.7.10。输入python3是调用的Python3。
如果希望输入python也能进入python3。可以自己vim ~/.zshrc(shell是zsh的话),加入一行alias python="python3"。之后source ~/.zshrc更新配置文件使修改生效。
包管理器pip
还有就是Python自带的包管理器pip。利用pip下载可以说很方便了,值得注意的是Python2并没有自带,Python3自带了pip,调用下载的jupyter note的话pip3 install jupyter。
列出可升级的包:
pip list --outdate
升级一个包:
pip install --upgrade 包名
pip的用法
conda环境
安装anaconda环境也有它的好处,多个可以创建不同版本的python环境,每个python环境里的包各自独立。不过anaconda里面预先装了很多包,精简一点可以下载miniconda。
常见指令:
- 创建指定python版本的环境:
conda create -n env_name python=3.6-n代表name。 - 进入与退出某个python环境:
conda activate env_nameconda deactivate - 列出所有的虚拟环境:
conda env list - 删除某个python环境:
conda remove -n env_name --all - 列举当前活跃环境下的所有包:
conda list - 为指定环境安装某个包:
conda install -n env_name package_name
cuda安装
首先需要安装NVIDIA的显卡驱动,针对对应的驱动版本安装不同版本的cuda-toolkit,同时需要下载对应的cuDNN。
cuda-toolkit-release-notes
https://docs.nvidia.com/cuda/cuda-toolkit-release-notes/index.html
非root用户安装
https://blog.csdn.net/txy12029047/article/details/90733643
https://blog.csdn.net/sinat_20280061/article/details/80421532
Jupyter notebook
顺带提一下这里的Jupyter notebook,十分好用的工具,不仅是编写支持多种语言(Python,Scala,Ruby,R,Haskell,Bash)的轻便编辑器,还支持Markdown和Latex语法,支持导出Markdown,HTML,PDF,LaTeX多种格式。最关键的是Jupyter Notebook 的本质是一个 Web 应用程序,十分轻量化,你可以通过终端里调用打开也可以直接浏览器输入localhost:8888访问,便于共享程序文档。
不过个人习惯是使用终端运行Python,然后编辑代码使用vscode编辑器。
Jupyter notebook相关
基础语法
基础语法里只挑选比较重要和有趣的一笔带过
操作符
x=5,y=2
整除:
指数:
类型转换
三个内建的类型转化函数int();float();str();
输入输出
input()和print()
message=input("Please enter the text")
显示提示信息并把用户输入信息存入message。在python3,input()默认读入的元素是string类型,需要自己转换成需要的数据类型。
或者使用sys.stdin.readline()或者sys.stdin.readlines()
import sys
if __name__ == '__main__':
try:
line = sys.stdin.readline()
n = int(line)
nums = [int(t) for t in sys.stdin.readline().split()]
except:
pass
字符串
1.Python和swift一样都支持用+来连接字符串:
"James"+"Lee"="JamesLee"
2.对于字符大小写:
upper()把字符串小写转大写,如 'Peter'.upper()得到'PETER'。 相对应的还有lower()。
capitalize()把第一个字符转大写,其余字符换小写。
3.isalnum()
如果字符串中的所有字符都是字母和数字,并至少存在一个字符,返回True,否则False。
空格不包含于数字和字母中
'a b'.isalum() => False
类似的还有isupper()、islower()、isalpha()、isspace()、isdigit()、istitle()
4.count(sub,start,end)计算子字符串sub在字符串中出现的次数,后面两个是可选参数。(count函数对于大小写是敏感的,Python的内建字符串函数基本都是大小写敏感的,后面默认)
'This is a test'.count('s')会返回数字3
'This is a test'.count('s',4)计算从第四位到尾的出现次数,会返回数字2
5.endswith(suffix,start,end)如果字符串以指定的后缀suffix结尾,返回True,否则False。suffix也可以是要寻找的多个后缀的元组。相反的还有startswith()re
'Prettygirl'.endswith('girl') =>true
'Prettygirl'.endswith('rl') =>true
'Prettygirl'.endswith('r') =>false
'Prettygirl'.endswith(('r','rl')) =>true
6.find/index(sub,start,end)
返回字符串中子字符串sub首次出现的位置。
find()如果没有在这个字符串中找到子串,返回-1。如果是index()返回ValueError
7.decode()和encode()
decode()二进制转字符。encode()字符转二进制。
8.split()和join()
字符串的分割和合并
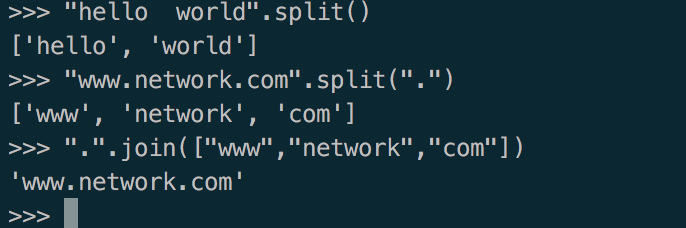
9.replace(old,new,count)把字符串中所有的old字符串替换为new字符串。count是可选参数。

10.splitlines([keepends])返回字符串所有行的列表。

11.strip([chars])复制一个字符串,返回该字符串首尾位置移除字符串char的结果。
如果没有指定,默认首尾的空格会被移除。
12.format()格式化字符串
指定格式有点像c语言里面的形式,{0:s}前面代表位置,后面代表数据类型。当然简化写法也可以不指定位置或者不标明数据类型。

也可以用这一种方式:
>>> 'Hello, %s' % 'world'
'Hello, world'
>>> 'Hi, %s, you have $%d.' % ('Michael', 1000000)
'Hi, Michael, you have $1000000.'
内联if
num = 12 if myInt==10 else 13当myInt等于10时候,num被赋值为13.
for以及while循环
简单举个例子演示下:
numbers = [12, 37, 5, 42, 8, 3]
even = []
odd = []
while len(numbers) > 0 :
number = numbers.pop()
if(number % 2 == 0):
even.append(number)
else:
odd.append(number)
for item in numbers:
print(item)
然后Python里跳出循环的方式和C++一样,都是看需要用break或者continue。
自定义的模块的导入
在同一个文件夹下,例如这个文件名是prime.py只需要import prime
如果不在一个文件夹下sys.path.append(绝对路径)即可
命令行参数
import sys 之后再 sys.argv获得参数列表,list形式存储
文件的读取
主要函数有
- f.read()以字符串或者二进制方式读取所有数据
- f.read(n)读入前n字节的数据
- f.readline()以字符串方式读取下一行
- f.readlines()以字符串方式读取所有行
对应的 - f.write(line)
- f.writelines(lines)
f = open('myfile.txt','r')
firstline = f.readline()
print(firstline)
f.close()
还有
f = open('myfile.txt','r')
for line in f:
print (line,end='')//end=''使得读取出的文件末尾不含\n换行
f.close()
read()可以规定每次读取的缓存大小
input = open ('myfile.txt','r')
output = open ('myoutfile.txt','w')
msg=input.read(10)
while len(msg):
output.write(msg)
msg = input.read(10)
input.close()
output.close()
文件开启模式参数:
r: 只读
w:只写
a:用于添加,文件不存在会创建
r+:用于读写
rb:二进制读
wb:二进制写
三个主要数据容器
列表(list)--使用方括号[]
test=[12,13,14,15]
基本和STL库里的list没有太多区别。值得在意的是索引可以取负值test[-1]=15同时和STL里面一样test2=test[1:3]输出test2会得到结果[13,14]也是[...)包括开始元素不包括结尾元素。
还有就是list的一些基础操作,append()、del 、extend() 、in 、not in、insert()、len()、remove()等。

初始化部分:
1.初始化递增的list:
list1 = range(10)
print list1
[0,1,2,...,9]
2.初始化每项为0的一维数组:
list2 = [0] * 5
print list2
[0,0,0,0,0]
3.初始化固定值的一维数组:
initVal = 1
listLen = 5
list3 = [ initVal for i in range(5)]
print list3
[1,1,1,1,1]
list4 = [initVal] * listLen
print list4
[1,1,1,1,1]
4.初始化一个5x6每项为0(固定值)的数组(推荐使用):
multilist = [[0 for col in range(5)] for row in range(6)]
其他函数包括
pop(count)得到列表中倒数第count个元素的值,默认是取出list末尾的元素,并把它从列表中删除。
reverse()逆转列表里的元素
统计一个数值在列表里的出现次数
a_list.count('a')
查看指定数值在列表里出现的位置
a_list.index('a')
sort()和sorted()两者的区别在于sorted()会返回一个新的排序后的列表,不对原始的list进行排序。
例子:字符串List按照元素长度排序
myList = ['青海省','内蒙古自治区','西藏自治区','新疆维吾尔自治区','广西壮族自治区']
myList.sort(key = lambda i:len(i),reverse=True)
+和*
+号就是连接符号,*号代表复制

元组(tuple)--使用圆括号()
元组的定义和访问和list基本一致。tuple_test = (1,2,3,4)创建之后tuple_test[1]就会返回数值2.
访问元组里定下初始值之后里面的值无法修改。如果出现元组里包含list元素的情况,这个list内部的值是可以修改的。

其他的tuple用法如del、in、len、+、*都和list提到的用法一致。
字典(dictionary)--使用花括号{}
基本和STL里的map很像。存储映射并且关键字唯一。和上面tuple可以放入可变对象list一样,dict里面你也可以放入list或者tuple。
相关函数包括clear(),get(),items(),keys(),values(),update()等。和list与tuple一样也可以直接索引访问,如下面的dic.get(1)也可以直接用dic[1]替换。
get() 函数返回指定键的值,如果值不在字典中返回默认值。dict.get(key,default=None)
当然可以自定义dic.get(key, 0) 找不到对应的键就会返回0。也可以返回字符串,如下图示例里面的的“not found”。

和tuple不一样的是,dic和list一样可以改变字典里的映射关系,如dic[1] = 20。并且添加新的字典映射时候直接对新项赋值即可。
确定字典里是否含有某个值,可以用in确定。如果希望删除某个映射,直接pop。

除了这三种容器之外其实还有个set,跟dict很像,不过只是一组key的集合,不存储value。创建,添加和删除的过程如下。值得在意的是创建时候如果含有重复的键值会自动把重复的过滤。set可以看成数学意义上的无序和无重复元素的集合,因此,两个set一般用来做数学意义上的交集、并集等操作。

Python函数
调用函数
简单的调用函数如abs(-20),在Python中函数名其实就是指向一个函数对象的引用,完全可以把函数名赋给一个变量,a=abs。使用时候a(-20)也是和上面的abs(-20)一样的作用。
定义函数
举个例子就行,Python的函数返回多个返回值也比较容易。设定参数默认值的时候在该参数后面加 = 就行,如下面的angle=0。
import math
def move(x, y, step, angle=0):
nx = x + step * math.cos(angle)
ny = y - step * math.sin(angle)
return nx, ny
使用时候用多个变量接收多个返回值即可,如x, y = move(100, 100, 60, math.pi / 6)
特别的,定义一个空函数,暂时没想好怎么写,但希望顺利运行。
def null_func():
pass
Python的一些特性
切片
对于list或者tuple以及字符串都能使用切片的方法快速提取其中的部分内容。

更普遍的,能够指定切片的step和方向:
object[start_index:end_index:step]
step:正负数均可,其绝对值大小决定了切取数据时的‘‘步长”,而正负号决定了“切取方向”,正表示“从左往右”取值,负表示“从右往左”取值。当step省略时,默认为1,即从左往右以步长1取值。
例如从右到左切片:a[::-1] 取偶数位置的切片 b = a[::2]
[:]和.copy()都属于“浅拷贝”,只拷贝最外层元素,内层嵌套元素则通过引用方式共享,而非独立分配内存。
>>>a = [1,2,['A','B']]
>>>print('a={}'.format(a))
a=[1, 2, ['A', 'B']] #原始a
>>>b = a[:]
>>>b[0] = 9 #修改b的最外层元素,将1变成9
>>>b[2][0] = 'D' #修改b的内嵌层元素
>>>print('a={}'.format(a))
a=[1, 2, ['D', 'B']] #b修改内部元素A为D后,a中的A也变成了D,说明共享内部嵌套元素,但外部元素1没变。
>>>print('b={}'.format(b))
b=[9, 2, ['D', 'B']] #修改后的b
>>>print('id(a)={}'.format(id(a)))
>>>print('id(b)={}'.format(id(b)))
id(a)=38669128
id(b)=38669192
更多用法
迭代
对于list和tuple我们可以通过下标访问和for循环来遍历,问题是很多其他数据类型是没有下标的。但是,只要是可迭代对象,无论有无下标,都可以迭代,比如dict就可以迭代:

列表生成式
用来创建list的生成式。形式多样,甚至支持条件判断和两重循环。


可迭代对象中分解元素
这里有个*号的运用,和正则表达中的*号含义类似。例如在期末成绩中去掉第一个和最后一个。
def drop_first_last(grades):
first, *middle, last = grades
return avg(middle)
生成器
通过列表生成式,我们可以直接创建一个列表。但是,受到内存限制,列表容量肯定是有限的。而且,开辟过多的list很浪费空间。
所以,如果列表元素可以按照某种算法推算出来,那我们是否可以在循环的过程中不断推算出后续的元素呢?这样就不必创建完整的list,从而节省大量的空间。在Python中,这种一边循环一边计算的机制,称为生成器:generator。要创建一个generator,有很多种方法。第一种方法很简单,只要把一个列表生成式的[]改成(),就创建了一个generator。可以通过next()函数获得generator的下一个返回值,或者用上面提到的迭代特性。

把一个函数变成生成器,以斐波那契数列为例:
def fib(max):
n, a, b = 0, 0, 1
while n < max:
print(b)
a, b = b, a + b
n = n + 1
return 'done'
print(fib(4))
输出:
1
1
2
3
done
变成一个generator,需要把print(b)变成yield b, 然后修改一下调用方式
def fib(max):
n, a, b = 0, 0, 1
while n < max:
yield b
a, b = b, a + b
n = n + 1
for n in fib(4):
print(n)
之前的函数是顺序执行,遇到return语句或者最后一行函数语句就返回。而变成generator的函数,在每次调用next()或者send()的时候执行,遇到yield语句返回,再次执行时从上次返回的yield语句处继续执行。使用for n in fib(4)进行迭代调用,本质上相当于不断调用next()。下面再看一个例子:
def foo():
print("starting...")
while True:
res = yield 4
print("res:",res)
g = foo()
print(next(g))
print(next(g))
输出结果:
starting...
4
res: None
4
如果使用send(),send是发送一个参数给res的。
def foo():
print("starting...")
while True:
res = yield 4
print("res:",res)
g = foo()
print(next(g))
print(g.send(7))
输出结果
starting...
4
res: 7
4
yield相关参考
Python中的一些高阶函数
sorted
Python的内置函数sorted可以接受一个key来指定排序的方法。
>>> sorted([36, 5, -12, 9, -21], key=abs)
[5, 9, -12, -21, 36]
默认从小到大排序,如果想从大到小,加入额外参数reverse。
sorted([36, 5, -12, 9, -21], key=abs , reverse=True)
key的运作方式是将key指定的函数将作用于list的每一个元素上,并根据key函数返回的结果进行排序。
例如对部分学生的按名字和按成绩分别进行排序:
L = [('Bob', 75), ('Adam', 92), ('Bart', 66), ('Lisa', 88)]
def by_name(t):
return t[0]
def by_score(t):
return t[1]
l2 = sorted(L, key = by_name)
l3 = sorted(L, key = by_score)
map/reduce
关于map和reduce的概念,在MapReduce: Simplified Data Processing on Large Clusters这篇论文具体提及。其实在并行计算上map和reduce也是基础的概念,在并行计算上map负责把大规模的数据量和运算量任务分给多个核心。reduce负责把多个运算结果总和成一个。

map()传入的第一个参数是f,即函数对象本身。由于结果r是一个Iterator,Iterator是惰性序列,因此通过list()函数让它把整个序列都计算出来并返回一个list。

reduce在使用前需要from functools import reduce,然后reduce后面跟的函数需要是一个含两个参数的。
filter
Python内建的filter()函数用于过滤序列。filter()把传入的函数依次作用于每个元素,然后根据返回值是True还是False决定保留还是丢弃该元素。和map()一样filter()函数返回的是一个Iterator,也就是一个惰性序列,所以需要用list()函数获得所有结果并返回list。
把一个序列中的空字符串删掉,可以这么写:
def not_empty(s):
return s and s.strip()
list(filter(not_empty, ['A', '', 'B', None, 'C', ' ']))
# 结果: ['A', 'B', 'C']
用filter求素数的方法
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
def main():
for n in primes():
if n < 1000:
print(n)
else:
break
def _odd_iter():
n = 1
while True:
n = n + 2
yield n
def _not_divisible(n):
return lambda x: x % n > 0
def primes():
yield 2
it = _odd_iter()
while True:
n = next(it)
yield n
it = filter(_not_divisible(n), it)
if __name__ == '__main__':
main()
这个方法是埃氏筛法,具体思路是,2是唯一的偶数素数优先输出,然后接下来就从奇数序列里找素数,_odd_iter构建了一个生成奇数的generator。然后从3,5,7不断增加这个generator的长度,之后到9的时候用filter看看9会不会被目前it这个生成器里已经有的元素整除,发现3能,所以会被_not_divisible筛除掉。这样不断往后推进,就可以得到1000以内的所有素数。
这个代码里值得注意的地方:
对于if __name__ == '__main__'的理解
首先函数对象有一个__name__属性,其次简单来讲if __name__ == '__main__'的意思是:当.py文件被直接运行时,if __name__ == '__main__'之下的代码块将被运行;当.py文件以模块形式被导入时,if __name__ == '__main__'之下的代码块不被运行。参考
lambda的理解
lambda其实是创建了一个匿名函数。当你需要用到的函数不是很复杂,你又懒得单独另起名字和另写一个def的时候,就可以用。这块在下面的匿名函数里会提及。
匿名函数、装饰器与偏函数
匿名函数
接着上面的filter求素数的程序来看:关键字lambda表示匿名函数,冒号前面的x表示函数参数。
举个例子理解下上面的_not_divisible的运行方式:
def get_y(a,b):
return lambda x:ax+b //x作为传入的参数
y1 = get_y(1,1)
y1(1) # 结果为2
当然,也可以用常规函数实现,如下:
def get_y(a,b):
def func(x):
return ax+b
return func
y1 = get_y(1,1)
y1(1) # 结果为2
那么如果匿名函数不用传入参数呢,纯粹就是变成求a+b的和可以写为
def get_y(a,b):
return lambda:a+b
匿名函数有个限制,就是只能有一个表达式,不用写return,返回值就是该表达式的结果。
用匿名函数有个好处,因为函数没有名字,不必担心函数名冲突。此外,匿名函数也是一个函数对象,也可以把匿名函数赋值给一个变量,再利用变量来调用该函数。
对于这一点,有个例子:
def count():
def f(j):
return lambda:j*j
fs = []
for i in range(1, 4):
fs.append(f(i))
return fs
f1, f2, f3 = count()
print(count())
print(f1())
print(f2())
print(f3())
在这个测试里面运行完count之后fs这个list里存的其实是三个函数,只有在用f1()调用这个函数的时候才会输出值。

装饰器
装饰器的详细讲解
装饰器本质上是一个 Python 函数或类,它可以让其他函数或类在不需要做任何代码修改的前提下增加额外功能,装饰器的返回值也是一个函数/类对象。它经常用于有切面需求的场景,比如:插入日志、性能测试、事务处理、缓存、权限校验等场景,装饰器是解决这类问题的绝佳设计。有了装饰器,我们就可以抽离出大量与函数功能本身无关的雷同代码到装饰器中并继续重用。对于装饰器用廖雪峰网站的一个例子:
我们先定义一个很简单的函数。
def now():
print('2019-1-1')
如果我们在之后想要增强now()函数的功能,又不希望改变now()函数的定义,这时候就需要用到装饰器的概念。
本质上,decorator就是一个返回函数的高阶函数。譬如我们写一个打印函数调用日志的函数。
import functools
def log(func):
@functools.wraps(func)
def wrapper(*args, **kw):
print('call %s():' % func.__name__)
return func(*args, **kw)
return wrapper
之后我们在原来的now()函数的def前加上@log,也就是
@log
def now():
print('2019-1-1')
这一步相当于执行now = log(now)。所以,调用now()函数时候需要先进入log函数,然后先print('call %s():' % func.__name__)之后return return func(*args, **kw)回到初始的now()函数,输出'2019-1-1'。
所以调用now()的输出为:
>>> now()
call now():
2019-1-1
wrapper()函数的参数定义是(*args, **kw),因此,wrapper()函数可以接受任意参数的调用。在wrapper()函数内,首先打印日志,再紧接着调用原始函数。
@wraps(view_func)的作用: 不改变使用装饰器原有函数的结构(如__name__, __doc__)。如果不带这个的话,加了修饰器之后now.__name__会变成wrapper,但是我们其实不希望改动原函数的这些熟悉。所以需要加@wraps。
对于带参数的decorator,举一个完整的输入日志的例子。其实就是你可以在所有你需要记录调用记录的函数上加上这个修饰器,然后每次调用都会输出相关信息到日志文件。
from functools import wraps
def logit(logfile='out.log'):
def logging_decorator(func):
@wraps(func)
def wrapped_function(*args, **kwargs):
log_string = func.__name__ + " was called"
print(log_string)
# 打开logfile,并写入内容
with open(logfile, 'a') as opened_file:
# 现在将日志打到指定的logfile
opened_file.write(log_string + '\n')
return func(*args, **kwargs)
return wrapped_function
return logging_decorator
@logit()
def myfunc1():
pass
myfunc1()
# Output: myfunc1 was called
# 现在一个叫做 out.log 的文件出现了,里面的内容就是上面的字符串
@logit(logfile='func2.log')
def myfunc2():
pass
myfunc2()
# Output: myfunc2 was called
# 现在一个叫做 func2.log 的文件出现了,里面的内容就是上面的字符串
偏函数
int函数还提供额外的base参数,默认值为10,也就是十进制。传入8也就是八进制。
如int('12345', base=8)
>>> import functools
>>> int2 = functools.partial(int, base=2)
>>> int2('1000000')
64
>>> int2('1010101')
85
理解运行过程可以举个例子,如max2 = functools.partial(max, 10)相当于会把附带的参数自动放到最左边。
max2(2,5,6)相当于
args = (10,5,6,7)
max(*args)
所以运行结果为10。