背景
良品数据分析系统是为了满足运营实时监控用户浏览行为、点击行为、以及观测良品铺子+日活的一套数据分析系统。这是他的前期的功能定位,后期会扩展他的监控范围,比如自营外卖的用户加购行为,用户的下单行为,用户的支付行为,以及整个外卖系统销售实时统计监控。随着系统的稳定后期可以承担商品精准推荐,精准营销,以及良品app的用户行为分析以及配套的各种营销手段,让良品的多套C端系统从此有了自己的对外了解用户,感知用户,发现用户,吸引用户的大脑和眼睛。
数据采集系统:是良品外卖团队经过2个月的技术沉淀,孵化出来的数据分析系统。从2018年12月底至2019年2月25日,外卖团队从对大数据一无所知,到后来初步实现,经历了学习,探索,研究,搭建几个重要的阶段,每一个阶段虽然走的很艰难,但总有阶段性的成果出现,从而不断激励我们一直向前。经过多套方案的预演最终确定了一套比较适合良品业务发展的数据分析系统。虽然良品内部已经有BI团队做大数据统计的部分,但是他们更多的是做离线非实时的销售报表的提供层面上,并不能提供实时的分析服务。而我们这套数据分析系统,与此最大的差别就是实时的计算结果展示,让运营能够根据监控到的结果及时做出反映,从而提升营运效率,及时抓住稍纵即逝的营销时机,让营销效果最大化。
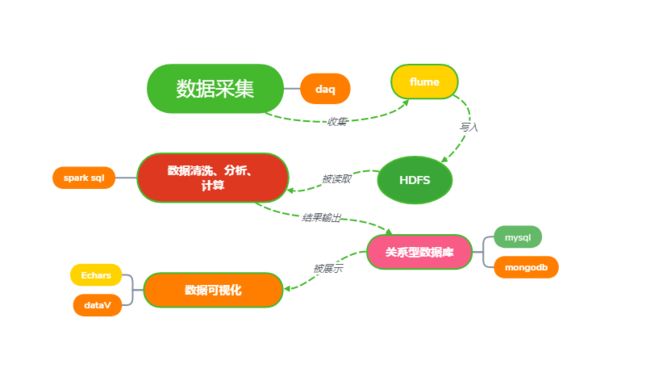
该系统分为多个模块组成,数据采集、数据存储、数据清洗、分析计算、结果数据存储、数据可视化。
接下来我们就一个一个模块来介绍:
一、架构
第一、数据采集、存储
数据采集我们用了take-out-daq服务来做用户浏览行为的日志记录,需要前端配合做用户浏览行为和点击行为的动作监控,并且把用户的每一个动作都以固定的接口字段,上送到daq这个服务中。daq的日志按照一定时间间隔来不断归档数据到一个被flume监控的文件夹里。我们把这个文件夹定义为/usr/logs/flume。该文件夹下如果有新文件产生,就会被flume监控到,并且会把该文件数据实时收集到按照一定的日期格式沉淀到hdfs中。
这一个过程中,我们牵涉到两块功能,第一是daq的日志归档功能,使用的logback.xml特性。另外一个就是flume,是apache开源的一套顶级项目,是专门做日志收集稳定的开源框架。
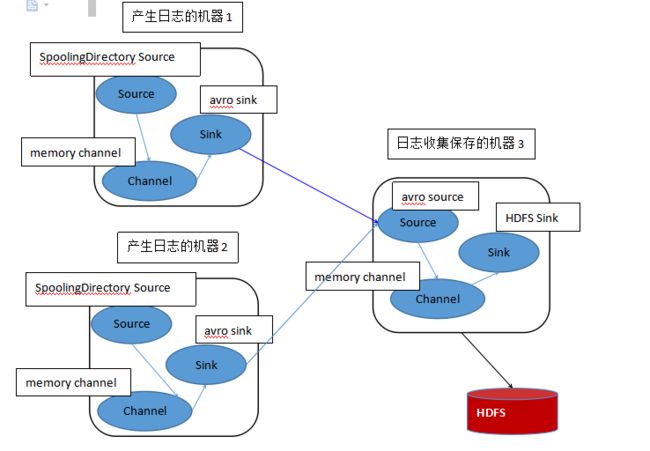
我们这里选择flume的日志收集策略是两个agent相互配合,第一个agent负责监控flume的日志归档目录/usr/logs/flume,并把数据包装成为一个远程的事件avrosink。第二个agent负责监控第一个远程的avrosink传递过来的事件,并且用avrosource来接受此事件,并且通过memroychannel来整合,最后通过hdfsSink下沉到hdfs中。(关于flume的知识可参看:flume.apache.org官网)
对应的flume部署框架图:
第二、数据清洗、计算分析
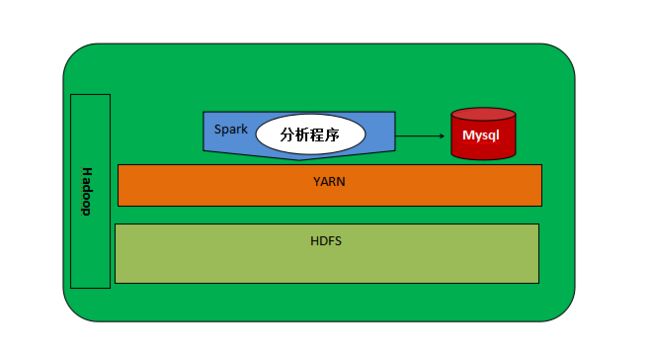
这里选择的是spark sql作为分布式计算框架,资源调度使用的yarn,这些服务都是跑在HDFS之上的。真正的计算逻辑是我们使用spark sql的语法来编写的一套计算组件,以jar包的形式spark-submit到运行在yarn之上的spark服务上的。运算时,会从hdfs中获取响应的数据,然后把计算结果沉淀到关系性数据库中。
第三步:数据可视化
数据可视化顾名思义就是把大数据计算完的结果,结合业务关注数据维度,以图表的形式直观地展示数据的一种方式,也是大数据分析的最后一个步骤。目前流行的可视化框架有很多,有阿里开源的dataV也有百度开源的Echarts,我们目前使用的Echarts。它的学习和开发成本很低,具体文档可以参看https://echarts.baidu.com/
数据可视化的功能放在了take-out-control中来实现,目前使用Echarts来做数据图表展示,使用heatmap来做页面点击热力图。
服务环境部署
服务器列表及部署目录
测试环境hdfs浏览目录:http://10.101.x.x:50070/
服务关系ip部署目录服务名所属业务影响环境对应配置文件及目录
test-flume-存储端10.101.x.x/usr/apache-flume-1.6.0-cdh5.7.0-bin
启动脚本:
nohup ./flume-ng agent --conf $FLUME_HOME/conf --conf-file $FLUME_HOME/conf/test-avro-memory-hdfs.conf --name test-avro-memory-hdfs -Dflume.root.logger=INFO,console &
flume日志接受并写向3的hdfs,开放端口是44444测试环境/usr/apache-flume-1.6.0-cdh5.7.0-bin/conf/test-avro-memory-hdfs.conf
10.101.x.x/usr/hadoop-2.6.0-cdh5.7.0hadoop、yarn数据存储测试环境/usr/hadoop-2.6.0-cdh5.7.0/etc/hadoop/spark-env.sh
10.101.x.x/usr/spark-2.1.1-bin-hadoop2.6spark数据计算测试环境/usr/spark-2.1.1-bin-hadoop2.6/conf/
test-flume-收集端10.101.x.x2/usr/local/apache-flume-1.6.0-cdh5.7.0-bin
启动脚本:
nohup ./flume-ng agent --conf $FLUME_HOME/conf --conf-file $FLUME_HOME/conf/spooldir-memory-avro.conf --name spooldir-memory-avro-Dflume.root.logger=INFO,console &
flume日志收集并写向129的flume,目标端口44444测试环境/usr/local/apache-flume-1.6.0-cdh5.7.0-bin/conf/spooldir-memory-avro.conf
prod-flume-收集端172.16.x.x/home/app/apache-flume-1.6.0-cdh5.7.0-bin
启动脚本:
nohup ./flume-ng agent --conf $FLUME_HOME/conf --conf-file $FLUME_HOME/conf/spooldir-memory-avro.conf --name spooldir-memory-avro-Dflume.root.logger=INFO,console &
环境变量:/home/app/base_profile (里面指定了jdk的安装目录和flume的安装目录)
注意:
该flume监控的目录是/usr/local/daq.lppz.com/logs/flumes/,这个目录是利用logback的归档功能,自动把日志归集到这个目录。一旦文件被归集进来,此时flume就会立刻监控到,并且立即传输文件里的数据到目标flume的55555端口,当flume监控的文件数据成功传输到55555端口并下沉到hdfs时,会自动清理掉/usr/local/daq.lppz.com/logs/flumes/目录下的.COMPLETED后缀的文件
flume日志收集并写向10.16.x.x的flume,目标端口55555生产环境/home/app/apache-flume-1.6.0-cdh5.7.0-bin/conf/spooldir-memory-avro.conf
prod-flume-存储端10.16.x.x(大数据部门hdfs集群主节点)/home/hadoop/apache-flume-1.6.0-cdh5.7.0-bin
启动脚本:
nohup ./flume-ng agent --conf $FLUME_HOME/conf --conf-file $FLUME_HOME/conf/prod-avro-memory-hdfs.conf --name prod-avro-memory-hdfs -Dflume.root.logger=INFO,console &
启动成功检查:
用ps -ef|grep flume,并且观察/usr/apache-flume-1.6.0-cdh5.7.0-bin/bin下的nohup.out的日志文件即可。
flume日志接受并写向(10.16.6.x至10.16.6.x7)的hdfs集群,开放端口是55555生产环境/home/hadoop/apache-flume-1.6.0-cdh5.7.0-bin/conf/prod-avro-memory-hdfs.conf
数据清洗服务10.16.x.x2(使用jdk1.8环境)计算服务的实现程序,这是jar包是我们开发人员编写,编译、打包上传到上面去的
/home/hadoop/waimai/selfjars/execData-1.1-SNAPSHOT.jar
spark on yarn(集群模式)从(10.16.x.x至10.16.x.x7)对应的hdfs数据仓库中获取埋点数据,并作计算,然后将计算结果插入到外卖生产库的结果展示表里生产环境1、/home/hadoop/waimai/selfshells/sparkDataAutoOption.sh计算服务启动脚本,无参则计算当前小时的数据。
2、/home/hadoop/waimai/selfshells/sparkDataAutoOption.sh 19-03-20 ,如果传递参数为19-03-20,那么他就会计算19年3月20日全天的数据
二、服务
2.1 服务器:
10.101.3.x
生产HDFS集群:
10.16.x.x Bingo-0x-01 hamaster (yarn master)
10.16.x.x1 Bingo-0x-02 hanode1 (ha2ndnamenode )
10.16.x.x2 Bingo-0x-03 hanode2
10.16.x.x3 Bingo-0x-04 hanode3
10.16.x.x4 Bingo-0x-05 hanode4
10.16.x.x5 Bingo-0x-06 hanode5
10.16.x.x6 Bingo-0x-07 hanode6
10.16.x.x7 Bingo-0x-08 hanode7
10.16.x.x8 Bingo-0x-09 hanode8
2.2 执行数据清洗方法
1.按时刻进行执行:在dev环境任意目录执行命令 sparkDataAutoOption.sh 清洗当前时刻的数据
2.自定义日期进行清洗,在dev任意目录执行命令 sparkDataAutoOption.sh 19-03-07 (日期格式:XX(年)-XX(月)-XX(日)) 定点清洗
2.4 脚本环境:
测试环境/开发环境:脚本目录:/usr/local/shell/bin/sparkDataAutoOption_test.sh :测试执行脚本
测试环境/开发环境:项目路径:/usr/bigdata/spark/test/execData-1.1-SNAPSHOT.jar
三、注意
3.1 生产环境
生产环境hdfs集群:hdfs://hamaster:9000该地址仅供程序之间数据传输使用,不能直接访问
hdfs数据查看地址:http://bingo-0x-x:50070该地址是供开发者,便捷的查看目前hdfs中的数据存储情况和数据存储效果,以及下载数据使用。效果见下图
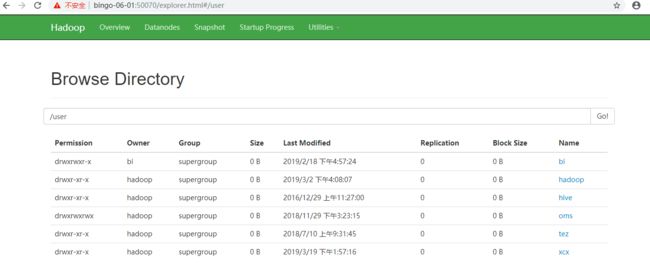
3.2自动化
管理地址:http://bizs.lp.com
使用阿里开源的dataX来管理我们数据清洗脚本的任务调度,决定开启或关闭,以及开启的频率,以及与其他清洗任务的关联关系。
我们清洗pv数据的任务目前每小时执行一次。
这里注意用spark_submit任务时需要制定num和queue
#####begin#####
DAY=$1
echo "=======执行spark -submit 清洗${DAY}的用户点击热门商品指标数据======="
spark-submit --class com.lppz.HotClickProdAnalysis --master yarn --driver-memory 2g --executor-memory 2g --executor-cores 1 --queue flinkqueue /home/hadoop/waimai/selfjars/execData-1.1-SNAPSHOT.jar ${DAY}
echo "=======执行用户点击热门商品数据清洗完成========"
#####end######
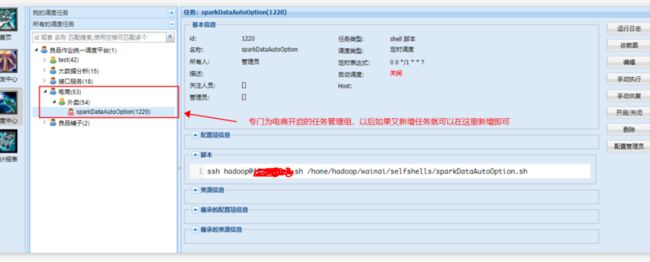
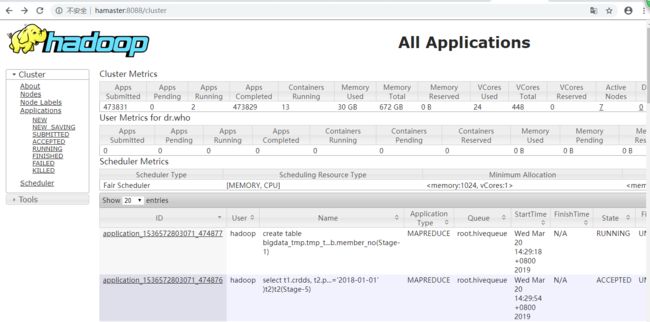
如果想查看任务执行的过程日志,有两种方式:第一、可以点击"运行日志"按钮即可查看。第二、可以在yarn集群上查看任务执行的情况,地址:http://hamaster:8088/cluster
如图: