论文原文:

论文题目:《Deep Neural Networks for YouTube Recommendations》
地址:https://www.researchgate.net/publication/307573656_Deep_Neural_Networks_for_YouTube_Recommendations
一 、背景
作为深度学习推荐系统中大名鼎鼎的经典的Youtube的深度学习推荐系统论文,本论文给很多视频网站的推荐系统的构建带来了很大的帮助,本论文详细介绍了Youtube的召回和排序两个阶段的模型,在世界上最大的视频内容平台构建了一个稳定可靠的推荐系统。
Youbube是世界上最大的视频网站,在如此体量的平台中,推荐系统是至关重要的。Youtube的视频推荐面临三方面的挑战:
(1)Scale(体量):视频和用户数量巨大,很多现有的推荐算法能够在小的数据集上表现得很好,但是在这里效果不佳。需要构建高度专业化的分布式学习算法和高效的服务系统来处理youtube庞大的用户和视频数量。
(2)Freshness(更新):这体现在两方面,一方面视频更新速度较快,另一方面用户行为更新频繁。
(3)Noise(噪声):相较于庞大的视频库,用户的行为是十分稀疏的,同时,我们基本上能获得的都是用户的隐式反馈信号。构造一个稳定可靠的系统是十分具有挑战的。
二 、Youtube推荐系统总览
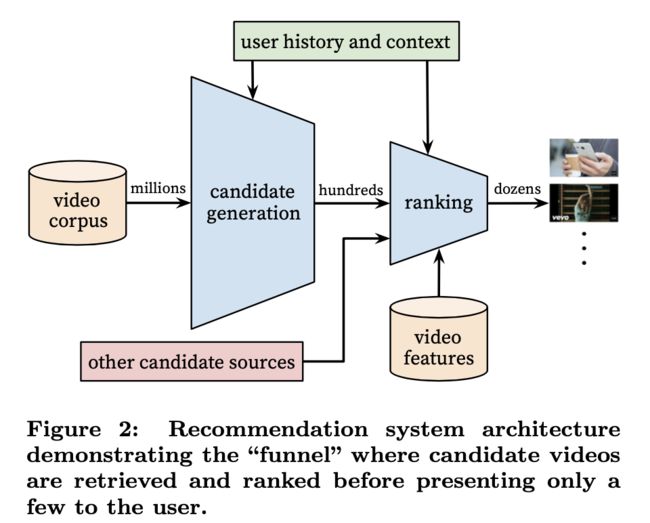
Youtube的推荐系统的总体结构如上图所示,分为两个阶段,候选集生成和排序两个阶段。其中,候选集生成可以当成召回阶段,从庞大的百万级视屏库中选取百数量级的候选物品作为排序模型的输入,排序模型进一步将数量级降低到十这个数量级别,然后提供给用户。
下面两张分别介绍一下怎么构建召回和排序模型。
三 、Candidate Generation
候选生成网络从用户的YouTube活动历史记录中浏览记录作为输入,并从大型视频库中检索一小部分(数百个)视频。这些候选者旨在高精确地与用户相关。候选生成网络仅通过协同过滤提供广泛粗糙的个性化。用户之间的相似性是根据诸如视频观看的ID,搜索查询的词汇和受众特征之类的粗略特征来表达的。
模型结构:
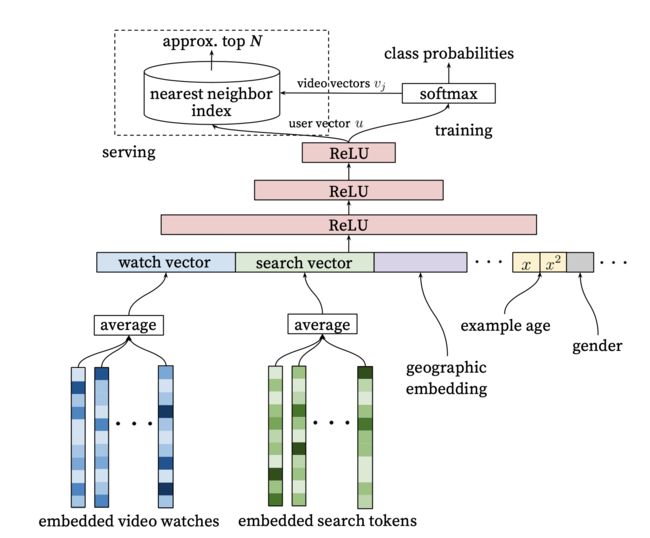
3.1 模型的输入
输入特征包括几个方面:
(1):用户观看的历史记录,即history list,一个video_id list
(2) :用户的搜索历史记录
(3):位置信息
(4): example age特征
(5):用户性别等特征
我们来逐个详细介绍下这些特征
浏览历史记录:
就是把用户的浏览历史的video经过embedding层后取平均作为输入向量
搜索历史记录:
跟浏览的历史记录一样,所有的搜索历史经过embedding后取平均
位置信息:
这个没什么好说的,特征作embedding就是
Example Age:
这是个很重要的特征,这个不是用户的年纪特征,而是视频从被上传到现在到时间。在Youtube上,每秒都有大量的新视频被上传,每个视频都要花几个小时的时间进行上传。给用户推荐新鲜的视频是至关重要的,根据网站的分析结论,用户往往会喜欢看那些即使相关度不高但是是最新的视频,因此example age特征就显得格外关键。
文章还对这个特征专门做了分析:
机器学习系统经常表现出对过去的隐性偏见,因为它们经过训练可以根据历史行为预测未来的行为。视频受欢迎程度的分布非常不稳定,但是用户在视频库上的多项分布会反映出几周训练窗口中的平均观看可能性。
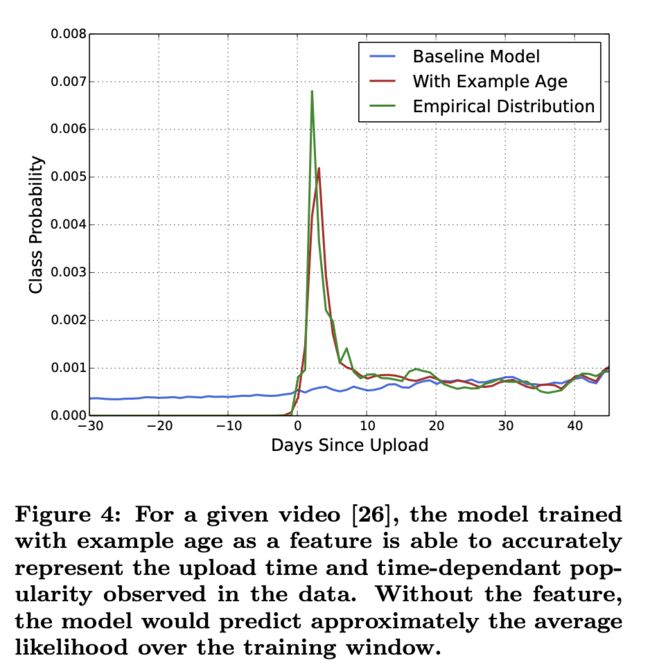
下面那段英文的意思大概是,有了这个特征后,模型能将准确表示数据中观察到的上传时间和时效性,从而能更好地将新鲜的视频推荐给用户。在线上服务阶段,该特征被赋予0值甚至是一个比较小的负数。这样的做法类似于在广告排序中消除position bias。
其他特征:
用户的性别等特征
3.2 样本和上下文选择
在这个推荐系统中,正样本是用户所有完整观看过的视频,其余可以视作负样本。
训练样本是从Youtube所有的用户观看记录里产生的,并不能只通过推荐系统产生的,否则将很难给用户推荐新视频,不利于exploitation,也即会陷入给用户一直推荐那些推荐系统中一直给他推荐的视频。同时,针对每一个用户的观看记录,都生成了固定数量的训练样本,这样,每个用户在损失函数中的地位都是相等的,防止一小部分超级活跃用户主导损失函数。
跟直觉上的感觉不一样,Youtube抛弃了用时序特征来建模的考虑,这是基于以下几个观点。举一个例子,如果用户在Youtube上搜索周杰伦,那么如果考虑时序因素的话,就把用户主页的推荐结果大部分变成周杰伦有关的视频,这其实是非常差的体验。毫不奇怪,将用户的最后搜索页面重现为首页推荐的效果非常差。通过丢弃序列信息并用无序的记录表示搜索查询,分类器将不再直接知道标签的来源。为了综合考虑之前多次搜索和观看的信息,YouTube丢掉了时序信息,讲用户近期的历史纪录等同看待。这个感觉就跟DIN中对用户对点击历史记录的处理方式是一样的,直接进行sum pooling操作。
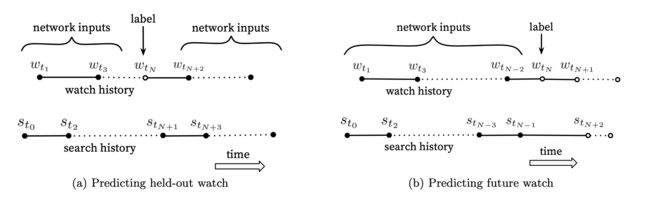
在测试集的构建上,YouTube没有采用经典的随机留一法(random holdout),而是把用户最近的一次观看行为作为测试集,如下图。这这么做主要是避免引入特征穿越。这么构建测试集合其实挺合理的,随机留一法不知道为什么可以用在构建测试集中,这种方法其实很容易出现特征穿越的,即模型看见了未来的东西。
3.3 模型训练
将视频库中的每一个视频当作一个类别,那么在时刻t,对于用户U和上下文C,用户会观看视频i的概率为:
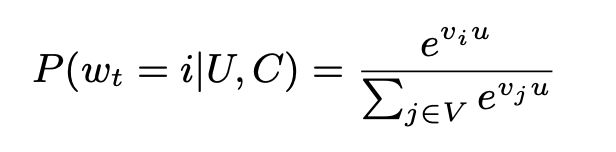
就是一个softmax函数,其中u是用户u的embedding向量,这个embedding,是网络最后一个Relu激活函数的输出,可以理解为:根据用户的观看历史,搜索历史,用户本身的特征来构建这个用户的embedding。vi是视频i的embedding。我们知道,在构建watch list的embedding的时候,每个视频都有对应的embedding,那么在上面这个计算观看概率的时候这个视频vi的embedding是不是这个embedding呢?个人认为不是,应该是还有另一个embedding矩阵单独作为计算这个概率的embedding,这么做虽然增加了模型的复杂度,但是在一定程度上是合理的,因为用户u的embedding向量经过了好几层relu,向量空间已经变化了,所以不能直接跟前面的embedding进行运算,要在同一个空间运算合理一点。
这个公式是不是很熟悉?word2vec里面预测词向量概率的时候也是用softmax进行计算的,我们知道如果视频库中的视频数量太大的话会造成softmax计算量十分庞大,所以w2v中采取了两种方式,负采样方法和hierarchical softmax方法,后者在实验中并没有取得很好的效果,所以Youtube也是采取负采样的方式进行训练。不同的地方有,在w2v中,负采样后是使用sigmoid进行激活并进行二分类,而在Youtube推荐系统中仍然是多分类问题。
3.4 实验参数以及结果

用MAP作为评价指标:
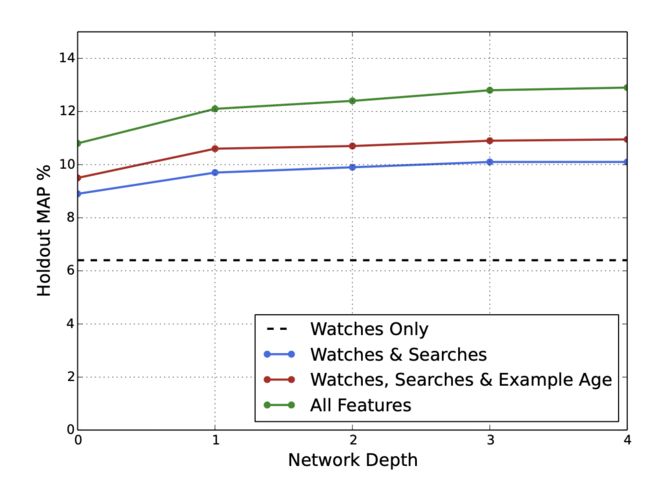
模型对比了网络的深度和输入的特征对模型结果的影响。
3.5 Online Serving
在以前我们也说过,召回任务就是要做到快又好,一个支持几亿用户的召回服务当然是不能让延迟成为阻碍了,通常要在毫秒级别就要返回召回结果了。因此,youtube没有重新跑一遍模型,而是通过保存用户的embedding和视频的embedding,通过最近邻搜索的方法得到top N的结果。
从模型结构图里面我们可以看到,Youtube不是通过向量的内积来计算相似度的,如果才用这种方法,那么意味着要计算所有视频跟用户u的相似度然后进行排序,这么做的话时间复杂度是很大的,排序的时间复杂度取决于视频的数量级。从图中可以看到,最终的结果是approx topN的结果,可以采用局部敏感哈希(Locality-Sensitive Hashing, LSH)等近似最近邻快速查找技术,时间复杂度是可以大大降低的。
四 、Ranking
如果说Youtube的召回服务没有给你眼前一亮的感觉,那么它将在后面的排序模型模型中给你展示他的强大之处。
先来看一下模型的结构:
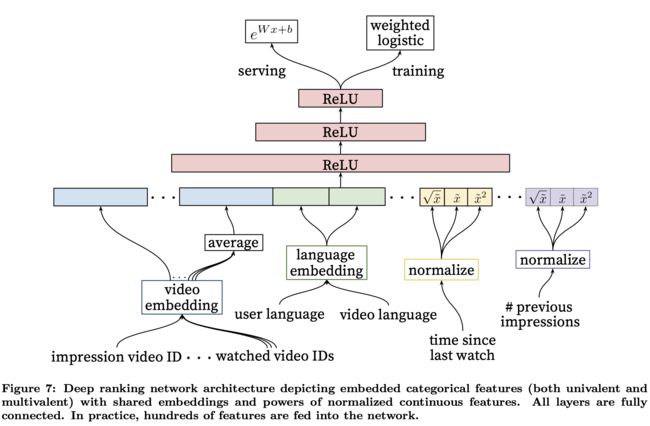
可以看到在排序模型中,我们使用了更多的特征,这也是为什么排序模型能更精确地给用户进行推荐的原因。
4.1 输入特征
impression video ID embedding: 当前要计算的video的embedding
watched video IDs average embedding: 用户观看过的最后N个视频embedding的average pooling
language embedding: 用户语言的embedding和当前视频语言的embedding
time since last watch: 用户上次观看同频道时间距现在的时间间隔
previous impressions: 该视频已经被曝光给该用户的次数
最后一个特征避免重复给用户推荐相同的视频,避免同一个视频持续对同一用户进行无效曝光,尽可能地增加用户没看过的新视频的曝光可能性。而第四个特征则让模型更好地捕获用户近期的兴趣。
4.2 特征工程
特征处理主要包含对于离散变量的处理和连续变量的处理。
对于离散变量,这里主要是视频ID,Youtube这里的做法是有两点:
1、只保留用户最常点击的N个视频的embedding,剩余的长尾视频的embedding被赋予全0值。主要原因有两点,一是出现次数较少的视频的embedding没法被充分训练。二是可以节省线上服务宝贵的内存资源。
2、对于相同域的特征可以共享embedding,比如用户点击过的视频ID,用户观看过的视频ID,用户收藏过的视频ID等等,这些公用一套embedding可以使其更充分的学习,同时减少模型的大小,加速模型的训练。
对于连续特征,主要进行归一化处理,神经网络对于输入的分布及特征的尺度是十分敏感。因此作者设计了一种积分函数将连续特征映射为一个服从[0,1]分布的变量。该积分函数为:
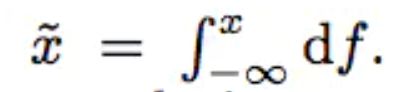
其实就是将概率密度分布转换成了累计密度分布。为了引入特征的非线性,除了加入归一化后的特征外,还加入了该特征的平方和开方值,这个在模型结构也能看到。这要是模型对特征处理的一个创新了,一般都是进行分桶进行离散化处理。
4.3 预测观看时长
本章节是这篇论文的精华之处,完美的运用了数学原理将回归预测转换为分类预测,可谓是神来之笔。至于为什么不用回归呢?下面给出一个较合理的解答:
回归有一个问题在于值域是负无穷到正无穷,在视频推荐这样一个大量观看时间为0的数据场景,为了优化MSE,很可能会把观看时间预测为负值,而在其他数据场景下又可能预测为超大正值。逻辑回归在这方面的优势在于值域在0到1,对于数据兼容性比较好,尤其对于推荐这种rare event的场景,相比回归会更加适合。
我们知道,不管是长视频还是短视频推荐任务中,预测用户的观测时长是一个很重要的指标,因为视频有着自己的特点,不想广告那样,靠点击预测就可以了,用户观看一个视频的时间越长,那么用户就越喜欢这个视频,这个其实相当于显示反馈了。
先复习一下逻辑回归中对数几率的含义,log p/1-p ,指的是正例发生的概率与负例发生概率的比值。在原始的lr中,P( y = 1 | x) = sigmoid(wx),通过简单的推导可以知道这个对数几率就等于wx,也就是输出y的对数几率是关于x的线性函数,或者说输出y = 1的对数几率是由输入x的线性函数表示的模型。
在本论文中,将原始lr的几率改写为:
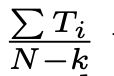
首先,原论文给正负样本赋予了不同的权重,对于正样本,权重是观看时间,而对于负样本,权重是单位权重(可以认为是1),上式中,Ti指样本中第i条正样本的观看时长,N是所有的训练样本,k是正样本的个数。所以,学习到的几率就近似于E(T)(1+p),其中P是点击的概率,E(T)是视频的期望观看时长,因为P非常小,那么乘积近似于E[T]。
回顾我们在原始lr中的推导,我们有对数几率 = wx,那么几率就 = exp(wx),因为几率可以近似于期望观看时长E[T],那么我们在测试阶段,就可以直接输出exp(wx),作为期望观看时长。
很多人看到上面第一个公式可能不知道为什么可以这么做,这里给出一个链接,王喆老师对这篇文章的解读,相信你看了之后就能知道为什么可以这样来预估观看时长了,
https://zhuanlan.zhihu.com/p/61827629

训练Weighted LR一般来说有两种办法:
1. 将正样本按照weight做重复sampling,然后输入模型进行训练;
2. 在训练的梯度下降过程中,通过改变梯度的weight来得到Weighted LR。
还是不理解的话,可以这么想,就是会让正样本发生的几率变成原来的w倍,这也就是上面说的训练weighted lr两种方式的由来,第一种是增加正样本数,第二种则是直接在损失上进行加权。
4.4 实验结果

五 、总结
Youtube这篇论文不仅在文采上还是在技术上都可以算是一顶一的绝好论文,不仅跟很多公司通过了一套召回+排序的推荐方案,还给众多视频推荐网站的排序模型引入的全新的概念,尤其是排序模型中对数学公式推导的运用,可谓是到达了perfect的效果,真的是经典好文。