前言
前面我们介绍了ArrayBlockingQueue,LinkedBlockingQueue,LinkedBlockingDeque三种阻塞队列,今天继续介绍PriorityBlockingQueue和DelayQueue两个阻塞队列,在介绍这两个阻塞队列之前,需要先了解一种数据结构:二叉堆。因为PriorityBlockingQueue内部使用了最小二叉堆算法来保证每次弹出的元素是最小元素,而DelayQueue又依赖于PriorityBlockingQueue。
二叉堆
堆的数据结构是一颗完全二叉树,完全二叉树指的是除了最后一层,其余层均有左右子节点。二叉堆又可以分为最大二叉堆和最小二叉堆。
最大二叉堆的某个结点的值最多与其父结点一样大,最小堆则是某个结点的值最多与其父结点一样小。所以最大堆中最大的结点永远是根结点,最小堆中最小的结点永远是根节点。
用数组(下标从1开始算)来存储二叉堆的话有以下几个特性:
- 第n个位置的子节点分别在index[2n]和index[2n+1]。如index[1]位置的子节点在index[2]和index[3],而index[2]位置的子节点为index[4]和[5],以此类推。
- 叶子节点的下标为index[n/2+1]到index[n]。如一个长度为9的数组中,index[5]到index[9]位置的元素均属于叶子节点。
- 第n个位置(非根节点)的父节点为:n/2
如下图就是一个二叉堆(圆圈内的数字表示数组下标,并不表示真实元素的值):

比如说4这个位置,他的左右子节点就是24和24+1,即8和9
n/2+1=5,说明从5到n即9都是叶子节点。
堆有三种基本操作:初始化,上沉,下浮(下面以最小二叉堆为例来说明):
- 初始化:将一个无序的数组初始化成堆。从最后一个非叶子结点开始,将父节点和子节点进行比较,如果父节点大于子节点,则将父节点和子节点替换,确保父节点<=子节点
- 上沉:用于插入元素。在数组的末尾插入新的元素,然后和父节点比较,如果比父节点大,则插入完成,如果比父节点小,则交换位置,并以此类推。
- 下浮:用于移除元素。移除头节点元素,此时会将数组末尾的数据拿过来先放到头节点,然后和子节点进行比较,如果比子节点大,则交换位置,以此类推。
注意:二叉堆和二叉树不一样,二叉堆并不保证左右节点的大小
PriorityBlockingQueue
PriorityBlockingQueue是一个支持优先级的无界阻塞队列(大小受限于内存)。和前面介绍的三种有界队列相比,无界队列的最大区别是即使初始化的时候指定了长度,那么当队列元素达到上限后队列也会自动进行扩容,所以PriorityBlockingQueue在添加元素的时候不会发生阻塞,而如果扩容后的大小超过了内存限制,会抛出OutOfMemoryError错误。
默认情况下PriorityBlockingQueue队列元素采取自然顺序升序排列。也可以自定义类实现compareTo()方法来指定元素排序规则,或者在初始化时,可以指定构造参数Comparator来对元素进行排序。
注意:PriorityBlockingQueue不能保证相同优先级元素的顺序(即两个值排序一样时,不保证顺序)。
下面还是先来看看PriorityBlockingQueue类图:

可以看到提供了4个 构造器:
- PriorityBlockingQueue():
初始化一个默认大小(11)长度的队列,并使用默认自然排序。 - PriorityBlockingQueue(int):
初始化一个指定大小的长度的队列,并使用默认自然排序。 - PriorityBlockingQueue(int,Comparator):
初始化一个指定大小的队列,并按照指定比较器进行排序。 - PriorityBlockingQueue(Collection):
根据传入的集合进行初始化并堆化,如果当前集合是SortedSet或者PriorityBlockingQueue类型,则保持原有顺序,否则使用自然排序进行堆化。
初始化
前面两个构造器最后都会调用第三个构造器去初始化一个队列:
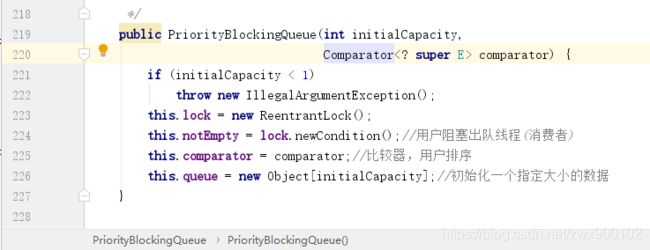
我们看到只有一个Condition队列,这个是用来阻塞出队线程的,入队线程不会被阻塞。
接下来我们主要看看第4个构造器,是如何初始化一个队列的:
public PriorityBlockingQueue(Collection c) {
this.lock = new ReentrantLock();
this.notEmpty = lock.newCondition();
boolean heapify = true; //true表示需要堆化即需要重排序
boolean screen = true; //true表示需要筛选空值
if (c instanceof SortedSet) {
SortedSet ss = (SortedSet) c;
this.comparator = (Comparator) ss.comparator();
heapify = false;//如果比较器是SortedSet类型则不需要堆化
}
else if (c instanceof PriorityBlockingQueue) {
PriorityBlockingQueue pq =
(PriorityBlockingQueue) c;
this.comparator = (Comparator) pq.comparator();
screen = false;//如果比较器是PriorityBlockingQueue类型则不需要筛选空值
if (pq.getClass() == PriorityBlockingQueue.class) // exact match
heapify = false;//如果pq就是一个PriorityBlockingQueue则不需要堆化
}
Object[] a = c.toArray();
int n = a.length;
// If c.toArray incorrectly doesn't return Object[], copy it.
if (a.getClass() != Object[].class)
a = Arrays.copyOf(a, n, Object[].class);//如果c.torray()失败,重新复制一个数组
if (screen && (n == 1 || this.comparator != null)) {//??
for (int i = 0; i < n; ++i)
if (a[i] == null)
throw new NullPointerException();
}
this.queue = a;
this.size = n;
if (heapify)
heapify();//堆化(排序)
}
上面标注了?的if判断,没想到什么场景会发生,如果有知道的,恳请留言告知,非常感谢!
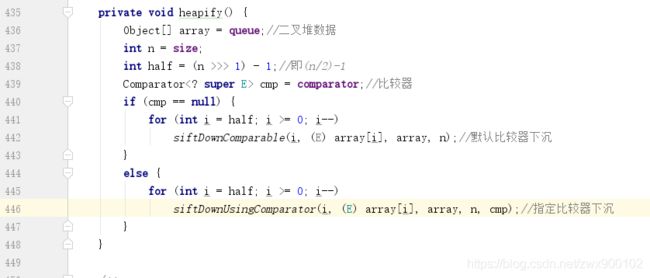
这一段代码看起来很长,实际上就是将指定的集合赋值给队列,并确认排序规则,如果需要排序,则调用heapify()方法,这个初始化排序才是关键:
下图就是一个数组[8,5,2,7,6,4,1,9,3]的二叉堆表现形式:
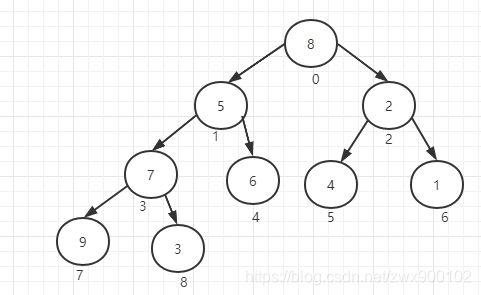
首先看到代码437行,从二叉堆的特性知道,二叉堆的初始化会从最后一个非叶子节点开始,也就是n/2开始,但是因为这种算法是基于元素从1开始算的,而数组是从0开始,所以这里需要减1,也就是从下图中的位置3(元素7)开始往前面循环。
后面就是两个排序规则判断,代码逻辑是一样的,我们进入siftDownComparable方法,这个方法主要就是完成元素的下沉操作
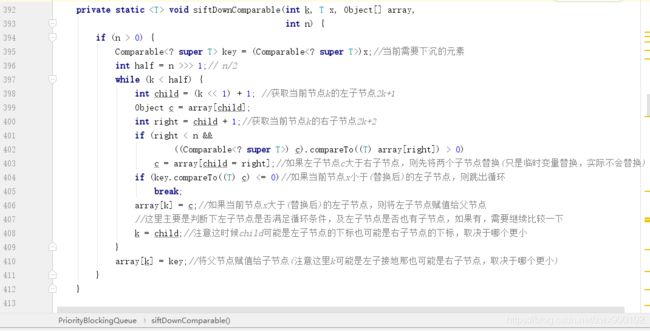
主要逻辑为:
- 将当前循环节点的左右子节点比较,确保拿到最小子节点的下标child
- 再将child对应的元素和父节点比较,确保父节点<最小子节点
- 最后会再次确认当前元素与最小子节点(可能是左也可能是右)的子节点(如果有的话)进行大小比较,依此类推,完成元素下沉。
注意:除了阻塞队列,我还分享了最新Java架构项目实战教程+大厂面试题库,有兴趣的点击此处免费获取,没基础勿进!
第一次下沉
从元素7开始循环,首先将元素9和元素3比较,发现9>3,临时变量替换一下,
然后将元素7和元素3比较,发现7>3,所以直接将父节点和右子节点替换,完成了第一次循环(因为子节点已经是叶子节点了,所以不满足二次循环条件)。
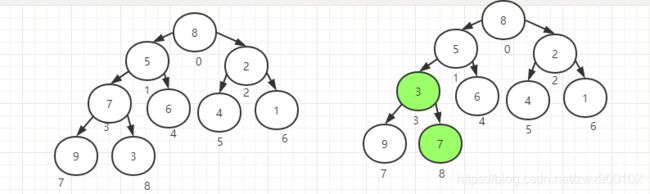
第二次下沉
第二次循环就到了下标2的位置,也就是元素2,和第一次循环类似,因为子节点是叶子节点,所以也是一次循环就结束,直接完成了父节点和最小子节点的替换,升级过程如下:

第三次下沉
第三次循环就到了下标1的位置,也就是元素5,这时候因为左子节点本来就小于右子节点,所以不需要临时替换,直接比较左子节点和父子节点,注意这里图2是一个临时过程,因为是首先将左子节点赋值给父节点,然后发现左子节点下面还有子节点会再进行一次循环,直到通过break跳出循环之后才会将5赋值给左子节点,完成替换:
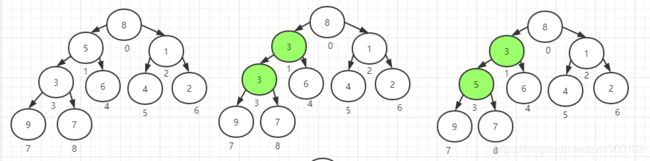
第四次下沉
第四次循环就到了下标0的位置,也就是元素8,首先完成1和3的替换,然后完成3和8的替换:
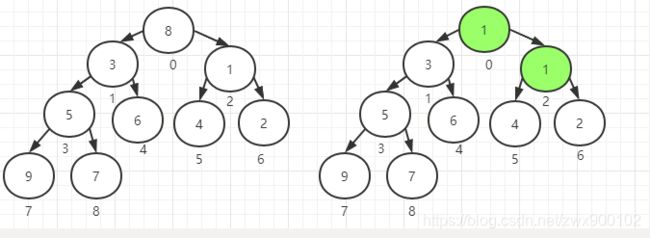
这时候因为最小子节点的下标是2,2 上图中两个流程可以看到,元素8会一路下沉到最后。 到这里完成了初始化排序,最终数组由:[8,5,2,7,6,4,1,9,3]变为[1,3,2,5,6,4,8,9,7]。 put(E)方法会调用offer(E)方法,上一篇阻塞队列的文章中,我们知道,offer(E)方法是不阻塞的,而这里是无界数组也不会阻塞,所以直接调用offer(E)方法就可以了: 这里逻辑比较简单,首先看有没有越界,越界了就先进行扩容,扩容放在后面讲。 还是用上面排序后的二叉堆,假如我们现在添加一个元素4,会得到下面这样一个二叉堆: 这时候为了确保新添加的元素按照排序规则不会比根节点小,需要将新添加的元素进行上浮操作。 发现4<6,所以将6放到队尾,注意这时候4并不会赋值到队列中,因为4还需要继续上浮确认放在哪个位置 第二次上浮会发现4<3,不满足所以会跳出循环,确认将4放在了下标4的位置,完成插入元素操作 调用take()方法获取元素 主要看dequeue()方法: 这个方法的主要逻辑为: 最后我们来分析下扩容tryGrow方法 DelayQueue是一个支持延时获取元素的无界阻塞队列。队列中使用PriorityQueue来实现。队列中的元素必须实现Delayed接口: 接口里定义了一个getDelay方法来获取当前剩余的过期时间,另外因实现了Comparable接口,所以还会有一个compareTo方法。 1、新建一个对象,实现Delayed ,并重写getDelay和compareTo 接下来看看类图 只有两个构造器,第一个是空的构造器,第二个是默认初始化一个集合。 通过循环调用add(e)方法进行添加,然后add方法又去调用了offer(e)方法: DelayQueue队列的元素是存在其内部维护的PriorityQueue上,所以上面调用了q.offer(e)方法。 q.offer(e)方法的处理方式基本和上面讲的PriorityBlockingQueue中逻辑一致 take方法会依次获取元素,如果第一个元素没到期,则会一直阻塞: 在Leader-follower线程模型中每个线程有三种模式: DelayQueue队列中有一个leader属性:private Thread leader = null;用到的就是Leader-Follower线程模型。
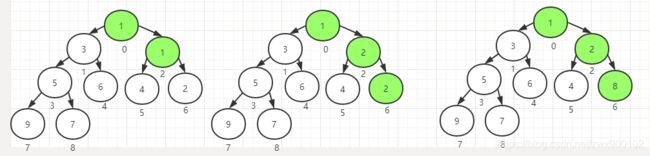
添加元素(生产者)
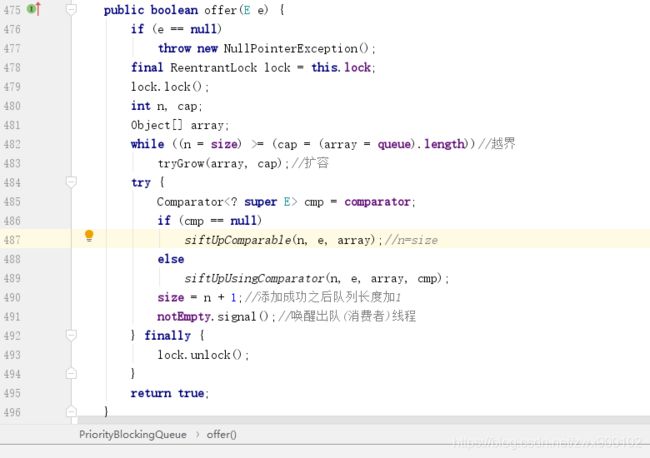
然后添加元素主要就是进行上浮过程,进入默认的排序规则上浮方法siftUpComparable:
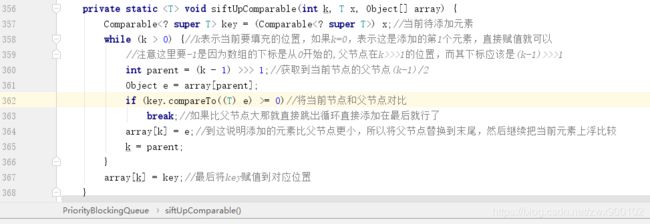
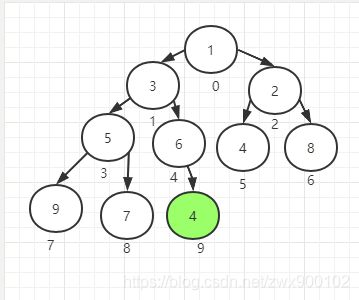
第一次上浮
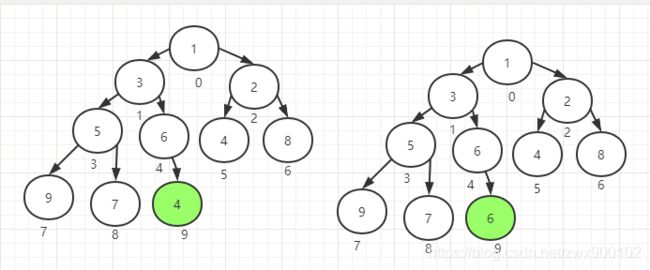
第二次上浮
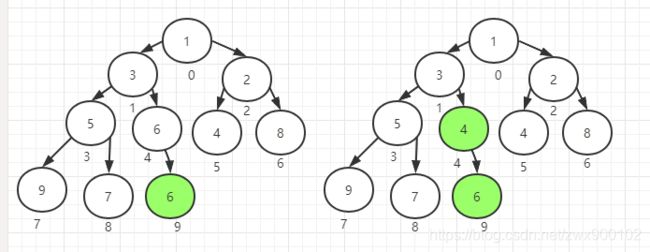
获取元素(消费者)
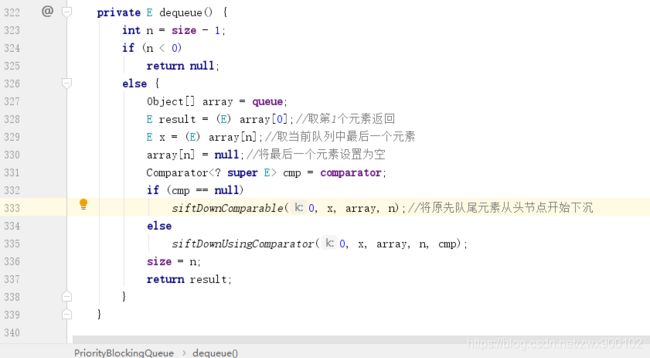
1、先拿到第一个元素(需要返回)和最后一个元素
2、然后将最后一个元素置为空
3、用存好的最后一个元素的值从头开始下沉
最后一步下沉操作和初始化的最后一步下沉操作是一样的处理方式,直到完成下沉就会诞生一个最小的元素重新放到头节点扩容
private void tryGrow(Object[] array, int oldCap) {
lock.unlock(); //扩容前先释放锁(扩容可能会费时,先让出锁,让出队线程可以正常操作)
Object[] newArray = null;
if (allocationSpinLock == 0 &&
UNSAFE.compareAndSwapInt(this, allocationSpinLockOffset,
0, 1)) {//通过CAS操作确保只有一个线程可以扩容
try {
int newCap = oldCap + ((oldCap < 64) ?
(oldCap + 2) : // grow faster if small
(oldCap >> 1));
if (newCap - MAX_ARRAY_SIZE > 0) {//大于当前最大容量则可能溢出
int minCap = oldCap + 1;
if (minCap < 0 || minCap > MAX_ARRAY_SIZE)//扩大一个元素也溢出或者超过最大容量则抛出异常
throw new OutOfMemoryError();
newCap = MAX_ARRAY_SIZE;//扩容后如果超过最大容量,则只扩大到最大容量
}
if (newCap > oldCap && queue == array)
newArray = new Object[newCap];//根据最新容量初始化一个新数组
} finally {
allocationSpinLock = 0;
}
}
if (newArray == null) //如果是空,说明前面CAS失败,有线程在扩容,让出CPU
Thread.yield();
lock.lock();//这里重新加锁是确保数组复制操作只有一个线程能进行
if (newArray != null && queue == array) {
queue = newArray;
System.arraycopy(array, 0, newArray, 0, oldCap);//将旧的元素复制到新数组
}
}
DelayQueue

DelayQueue使用示例
package com.zwx.concurrent.queue.block.model;
import java.sql.Time;
import java.util.concurrent.Delayed;
import java.util.concurrent.TimeUnit;
public class MyElement implements Delayed {
private long expireTime;//过期时间(毫秒)
private int id;
public long getExpireTime() {
return expireTime;
}
public void setExpireTime(long expireTime) {
this.expireTime = expireTime;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public MyElement(int id, long expireTime) {
this.id = id;
this.expireTime = System.currentTimeMillis() + expireTime;
}
@Override
public long getDelay(TimeUnit unit) {
//类里面接收的是毫秒,但是getDelay方法在DelayQeue里面传的是纳秒,所以这里需要进行一次单位转换
return unit.convert(expireTime - System.currentTimeMillis(),TimeUnit.MILLISECONDS);
}
@Override
public int compareTo(Delayed o) {
//注意,这里的排序要确定最先到期的放在第一位,否则会阻塞住后面未到期的
return Long.valueOf(expireTime).compareTo(((MyElement) o).expireTime);
}
}
package com.zwx.concurrent.queue.block;
import com.zwx.concurrent.queue.block.model.MyElement;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.DelayQueue;
public class DelayQueueDemo {
public static void main(String[] args) {
ListDelayQueue类图
初始化
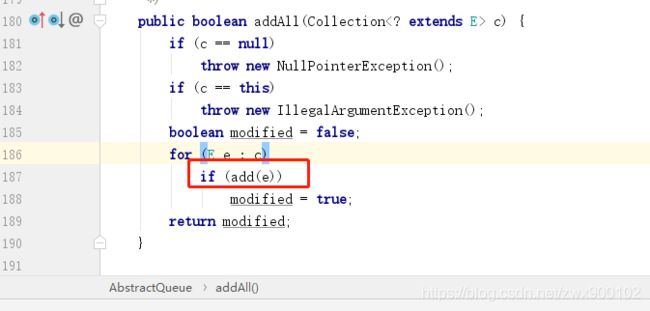
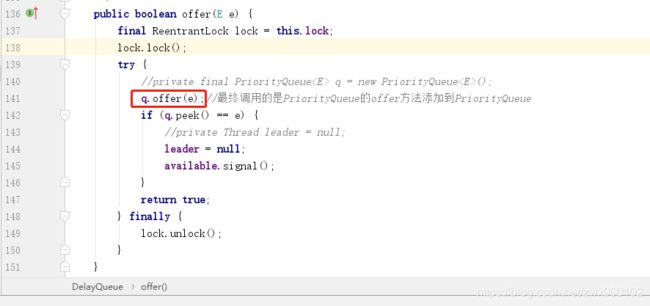
添加元素(消费者)
leader表示获取到锁的线程。q.peek()==e表示当前第一个元素就是刚刚添加进去的元素,所以需要将leader设置为空,唤醒出队(消费者)线程重新争抢锁。

获取元素(消费者)
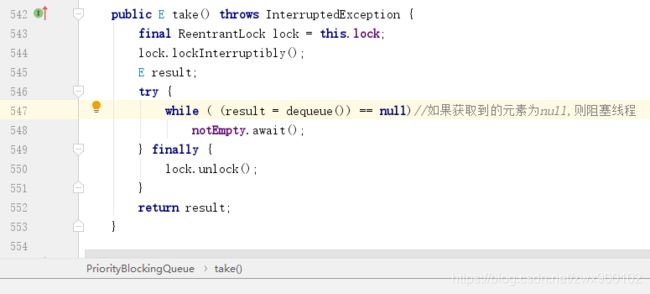
public E take() throws InterruptedException {
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
for (;;) {
E first = q.peek();
if (first == null)
available.await();//队列为空,则阻塞
else {
long delay = first.getDelay(NANOSECONDS);
if (delay <= 0)
return q.poll();//如果到期了,则调用poll方法取元素并直接返回
first = null; // don't retain ref while waiting
if (leader != null)
available.await();//头节点不为空,说明有线程持有锁并正在等待到期时间,所以直接阻塞
else {//leader==null
Thread thisThread = Thread.currentThread();
leader = thisThread;//设置头节点为当前线程,表名有线程在等待头节点元素过期
try {
available.awaitNanos(delay);//阻塞指定时间
} finally {
if (leader == thisThread)
leader = null;
}
}
}
}
} finally {
if (leader == null && q.peek() != null)
available.signal();
lock.unlock();
}
}
Leader-Follower线程模型
当有一个线程持有锁,设置了leader属性,正在等待元素到期时,则成为了leader,其他线程就直接阻塞。