3. HTTP应用
文章目录
- 简介
- 配置指令
-
- listen
- 接收请求
- 模块处理阶段
-
- 正则表达式
- server_name
- 11个阶段
- POST_READ
- REWRITE
-
- return
- error_page
- rewrite
- if
- FIND_CONFIG
-
- location
- PREACCESS
-
- zone
- ACCESS
-
- allow&deny
- auth_basic
- satisfy
- PRECONTENT
-
- try_files
- mirror
- CONTENT
-
- root&alias
- 三变量
- type
- index
- autoindex
- concat
- LOG
-
- log_format
- access_log
- 过滤模块
-
- sub_filter
- add_before_body
- 变量
-
- map
- AB测试
- geo
- geoip
- 防盗链
-
- referer
- secure_link
- keepalive
- 小结
简介
- 这里主要介绍nginx核心模块下的HTTP应用,也是我们配置最常用到的模块和指令
- 这里从建立请求链接开始,按处理顺序介绍,并非一会儿指令一会儿模块的
- 指令均属于模块,变量归属框架和模块两类
配置指令
- 第一篇中回顾了HTTP应用(模块)下nginx的基本使用,配置nginx.conf时的
http/server/location/upstream块,以及常用到的一些指令,需要注意的是- 其中所使用的指令要遵循上下文规范:

- 当一个指令重复出现时可以合并,合并规则:(动作类指令较少)

- 最常见的场景如下:

- 合并配置的实现流程:

- 可以通过看源代码的方式,判断合并是否可行及其方式(比较重要)
- 首先明确,是针对一条指令
- 这个指令定义在哪个模块?搞清楚
- 一般在源码的
ngx_command_t定义了所有该模块的指令,同时指明了允许出现在哪些块、参数等 - 如果要合并,需使用在
ngx_http_module_t下面的回调方法,在此方法中即可看到规则
- 我们以上的配置都是在HTTP应用中,注意这些说法,结合第二篇的一些概念,应用——子模块——指令、四块(配置格式),是有层级关系的;这里的HTTP可以理解成只是一个概念,也不是什么http网络协议
- 接下来对重点指令和nginx模块的执行阶段详细介绍
- 介绍的顺序符合请求处理的一般流程,如果你觉得混乱,可以从浏览器请求开始理一下思路
- 其中所使用的指令要遵循上下文规范:
listen
- 请求过来需要先与端口建立TCP连接,监听端口的指令就是listen
- 官网给出的配置规则:

- 看例子吧,上面一堆搞的头疼
listen unix:/var/run/nginx.sock; listen 127.0.0.1:8888; listen 127.0.0.1; # 默认80端口 listen [::]:8000 ipv6noly=on; - 注意,只能在server块下使用,还有一些参数后面介绍
接收请求
- 一个网络请求过来后,需要建立链接,获取请求头header,我们需要从中获取数据并解析处理
- 接收请求——事件分发:(左边这两块)

- 第二篇说了nginx的事件分发和epoll进程管理,图中是操作系统内核分发负载,具体怎么建立连接的,用了哪的参数?这个还会说明
- epoll拿到fd先建立链接(ctl添加监听socket)并设置定时器
- 拿到DATA(header)后,唤醒进程处理,buffer一般为1K;如果头部很大超过1K呢?
- 当然,这都是HTTP应用模块的活了,看下面
- 接收请求——HTTP应用模块处理:

- 注:上一步是浏览器和服务器建立链接(socket),这里开始解析处理URI和请求头
- URL是URI(统一资源标志符)的子集(除了IP和端口的部分)
- 标识URI即使用C语言的指针,这也是nginx性能强大的关键
- 以上都是由nginx框架完成的(状态机和epoll),接下来是nginx模块的具体处理阶段
模块处理阶段
- 从这里开始,将详细介绍接收请求头之后,模块的处理解析工作
正则表达式
- 在
location块中我们会对过来的URL进行正则匹配,这是产生响应的第一步,这里介绍最常用的正则规则:- 元字符:简而言之,有特殊意义的字符,代表一类字符

- 匹配语法:这里是重复匹配

- 如果想匹配有些元字符,需要加
\转义,例如\^,其他的匹配啥就写啥
- 元字符:简而言之,有特殊意义的字符,代表一类字符
- 测试方法:在Linux上可以用源码安装一下
pcretest,运行> pcretest,输入re>和data>- 注意,re表达式需要用
/ /包起来
- 注意,re表达式需要用
server_name
- 又是一个常用的指令,用来匹配域名,用法主要有三点
- 跟多个域名,第一个是主域名,打开
server可以在重定向时使用主域名(可以直接跟IP) - 泛域名,在最前或最后使用
* - 正则匹配域名:加
~前缀开始匹配,例如server_name ~^www\.roykun(\d+)\.vip$;
- 跟多个域名,第一个是主域名,打开
- 详细说一下正则用法
- 用小括号包住,可以用序号取出对应部分
- 但这不适合太长的匹配规则,可以定义变量,如图使用
?<>

- 其他
.roykun.vip可以匹配roykun.vip和*.roykun.vip_匹配所有""匹配没有传递Host头部(域名)
- 匹配顺序
- 精准匹配
-
*在前的泛域名 -
*在后的泛域名 - 按定义的顺序正则匹配
- default server:第一个Server或者listen后跟
default的Server
11个阶段
- 小结:建立链接——接收header——匹配域名,然后开始具体处理这个请求
- 每个请求都严格按照这11个阶段使用对应的模块执行:

- 某个模块不把请求向下传递,后面的模块不能执行
- 每个阶段可能有多个模块,顺序如何呢?

- 上图中,前面的模块可以直接将请求交付给下一阶段,从而后面的模块得不到执行
- 接下来每个模块都会介绍其处于哪个阶段,如何生效的!
POST_READ
- postread阶段,重点是获取用户真实IP ,用于做流控等
- 请求到达期间可能做了反向代理或者CDN(内容分发网络),但我们的处理针对115.204.33.1

X-Forwarded-For和X-Real-IP用于传递IP
- 拿到真实IP后,必须基于**变量**使用
- realip模块默认不编译进nginx,所以需要使用源码安装 :

- 有三条主要指令:
- from指令:指定可以从哪里获取IP赋值给变量
real_remote_port和real_remote_addr,可以直接指定IP

- from指令:指定可以从哪里获取IP赋值给变量
- 示例:返回$remote_addr
- 使用
curl -H 'X-Forwarded-For:1.1.1.1, 116.62.160.193' realip.taohui.tech访问(添加请求头) - 当关闭回环地址
recursive时,返回的是116.62.160.193,打开时返回1.1.1.1 - 结论:打开回环地址可以返回主域名

- 使用
REWRITE
- 这个阶段主要是rewrite中的
rewrite指令,重写URL请求 - 但在此之前,我们需要先掌握请求重定向,常用到两个指令:
return和error_page
return
- 返回状态码和处理方式,常见的形式有三种
- return code [text]; # 返回message
- return code URL; # 返回重定向地址
- return URL;
- 常见的状态码:

error_page
- 为了更好的用户体验,不直接返回原始的404错误页面, 而是使用此指令返回我们的自定义页面
- 常见的配置方法:

- return指令可以放在server和location块,这就要考虑合并了,return先于error_page
- 观察下面三段代码的执行结果:
root html/; error_page 404 /403.html; # return 405; location / { # return 404 "not found!\n"; }- 此时返回我们自定义的403页面
root html/; error_page 404 /403.html; # return 405; location / { return 404 "not found!\n"; }- 直接返回not found!
root html/; error_page 404 /403.html; return 405; location / { return 404 "not found!\n"; }- 此时直接返回405,从前面的阶段表可以看出,上面的return在SERVER_REWRITE阶段,location中的在REWRITE阶段
rewrite
- 指令格式:

- 指令含义:

- 看个例子吧:
root html/; # 根目录 location /first { rewrite /first(.*) /second$1 last; return 200 "first"; } location /second { rewrite /second(.*) /third$1; # break return 200 "second!"; } location /third { return 200 "third!"; }- 我们访问
/first/1.txt,重定向到/second ,返回“second!”,因为我们没有加last,并不会用新的规则匹配 - 加上break,返回“third!”,因为此时跳过所有当前location中的语句,直接匹配
/third/1.txt
- 我们访问
- 再看个例子,看看
redirect和permanent以及replacement中的特殊情况:

- 结果如下:
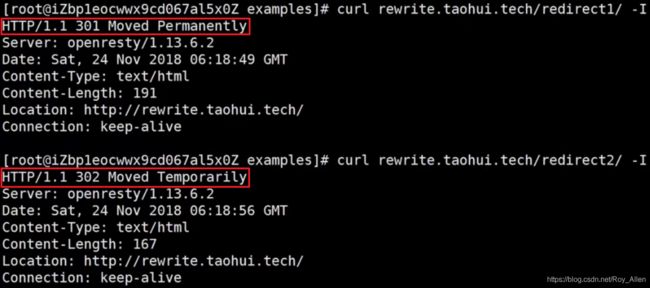

- 注:重写URL都会在error.log中记录!
if
- 根据条件,执行后续指令

- 常用的条件:

- 来个例子:

FIND_CONFIG
- 在匹配并重写了URL域名之后(进入server块),需要匹配对应的
location进行进一步请求处理了,就在find_config阶段
location
- 指令介绍:

- 匹配规则:

- 常规匹配即
/xxx,写啥匹配啥;主要的就三种:常规、精准、正则 - 如果多个location匹配上呢?按如下流程处理:精准禁则先,正则最长后!

- 常规匹配即
- 看个例子:

- 效果如下:(文件中有精准匹配,没截上)

PREACCESS
- 接下来的模块,其指令基本都可以出现在location块中
- 这个阶段主要有两个模块
limit_conn_module和limit_req_module - limit_conn模块,常用在限制同一用户的并发连接数,所以基于共享内存

- limit_req模块,限制同一用户请求速率(即规定时间内请求数量),模块定义:

- leaky bucket算法:

zone
- limit_conn需要使用共享内存,就必须使用
zone指令,使用方法:

key一般定义为用户IP,即$binary_remote_addr,这是关键,全局识别同一用户

- 还可以做如下两点限制:


- 看个例子吧:
limit_conn_zone $binary_remote_addr zone=addr:10m; # 共享空间命名为addr server { server_name www.roykun.vip; root html/; error_log logs/error.log info; location / { limit_conn_status 500; limit_conn_log_level warn; limit_rate 50; # 每秒只返回50字节 limit_conn addr 1; # 并发连接数 1 } }- 当同一用户访问www.roykun.vip时,第二次访问会返回500的警告,可以在日志查看
- 上面的例子为了方便演示,实际使用时,可以将同一用户的并发连接数限制在合适范围,可以有效降低负载
- limit_req同样需要用到共享内存,使用方法:


- 类似的,可以设置日志级别,返回状态码

- 结合上面的例子:
limit_conn_zone $binary_remote_addr zone=addr:10m; # 共享空间命名为addr limit_req_zone $binary_remote_reqs zone=10m rate=2r/m; # 每分钟两条请求(为了演示) server { server_name www.roykun.vip; root html/; error_log logs/error.log info; location / { limit_conn_status 500; limit_conn_log_level warn; # limit_rate 50; # 每秒只返回50字节 # limit_conn addr 1; # 并发连接数 1 # limit_req zone=reqs; # 连续请求第二次就报503 limit_req zone=reqs burst=3 nodelay; # 连续请求,第四次503 } } # curl www.roykun.vip/test.txt - 当我们同时打开限制连接和限制请求速率时,连续两次访问,报的是503,这说明了limit_req先于limit_conn执行
ACCESS
- 限制哪些IP可以/不可访问URL,可以回头去看看阶段流程图
access_module模块定义:

allow&deny
- 允许/拒绝某IP访问地址,使用方法:

- 看个例子:
location / { deny 192.168.154.66; allow 192.168.154.66/24; # 顺序执行,当满足一条后,不再往下执行 deny all; }
auth_basic
- 此模块校验用户名密码是否匹配,从上个模块开始,我们会发现模块和其主要指令名称相同(所以这里的标题以此命名)
- 默认编译进nginx,可以使用
--without禁用 - 命令使用方法:(指令格式、默认值、使用位置)

- file即保存用户名密码的文件,怎么生成这个文件呢?
- 安装依赖包:
sudo yum install httpd-tools,使用命令:htpasswd -c file -b user pass - 生成文件的格式形如:
name1:password1 name2:password2:comment # 注释
- 看个例子吧:


- 当我们想对一些简单的页面(例如之前提到的GoAccess)做安全保护,这个就可以,而不用后端服务器操心了
- 当然,这只适用于简单情况,还可以使用
auth_request模块借助上游服务器验证- 原理:收到请求后,生成子请求,通过反向代理技术,把请求传给后端服务器
- 如果返回的状态码是2xx,则继续执行
- 使用方法:

- 使用指令auth_request生成子请求
- 看例子吧,这里使用另一台nginx作为后端,配置如下:

- 边缘nginx配置如下:

- 此时可以成功到达test页面,禁用缓存,修改上游返回403,会出现Forbidden
satisfy
-
到这里,access阶段有三个模块可以截断用户的请求,这几个模块必须按顺序执行吗?如果截断,用户的请求就不能被执行?
- 先说说他们的顺序:

- 先说说他们的顺序:
-
satisfy指令可以控制所有access阶段模块的指令 -
指令定义:

- 相当于开关,拒绝+all=全部拒绝,放行+any=全部放行
- 其他都是执行下一个access阶段
-
指令的判断逻辑如图:

- 看个例子,试着回答下面两个问题:

- 答案:(1)可以访问到,虽然deny all,但是通过satisfy开关让我们可以执行下一模块auth_basic;(2)没机会输入密码,satisfy直接跳过access阶段了都!(阶段内模块顺序,和定义顺序无关)
- 看个例子,试着回答下面两个问题:
PRECONTENT
- 这个阶段在正式访问content之前,也是准备工作的最后阶段(可以把前面的阶段都理解成正式处理请求之前的预热)
- 为请求设置返回的default值和发起子请求(拷贝流量)
try_files
- 一样的,模块也是指令,使用方法:

- files 意思是可以跟多个 路径/文件名
- 功能:

- 看个例子吧:

- 提一下,这部分的测试配置可以放在vhost,里面写个server,然后include进来就行
- 还有这个
@lasturl;的用法 - try呗,找不到就用uri找呗!没啥说的了,就是给正式请求准备个备胎
mirror
- 见名知义:镜像,处理请求时,生成子请求访问其他服务,指令的使用方法:

- 看个例子:mirror.conf

- 对于需要在多个环境中处理用户的当前请求非常有帮助
CONTENT
- 终于开始正式处理请求了,也到了我们使用最频繁的指令
root&alias
- 都在
static模块 - 这令个指令的区别在哪呢?
- root更常用,会将完整url映射进文件路径中,用人话说就是会从这里规定的路径开始寻找文件
- 两个指令都以nginx安装目录为路径起点,例如
alias html;即找安装目录下的html文件夹,默认访问index文件 - 一般是将nginx当做静态资源服务器时,我们使用这两个指令
三变量
- static模块还提供三个变量,保存相关路径:


- 我们将realpath软链接到first,按上面的配置访问,结果如下:(软链接可以理解为快捷方式)

type
- 静态文件返回时的content-type:

- 未找到文件时的错误日志:

- static模块实现了root/alias功能时,发现访问目标是目录,但末尾又没有加
/,此时会返回301重定向,具体怎么重定向呢?- 看看这几个指令:

- 看个例子吧:
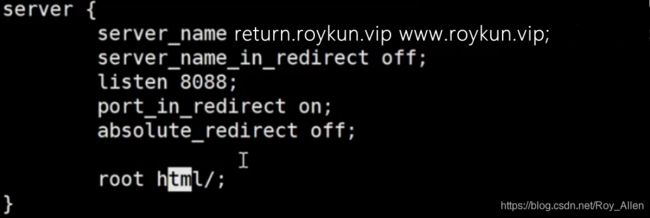
- 我们先关闭
absolute_redirect,默认是打开的,使用curl localhost:8888/first -I命令访问,注意别加反斜线,返回结果如图:没有返回具体路径

- 如果打开配置:

- 如果打开
server_name_in_redirect,返回的是主域名 - 同理,如果关闭
port_in_redirect,则返回时不会带上端口,默认打开
- 看看这几个指令:
index
- 访问
/时返回名叫index的文件

autoindex
- 返回root/alias指定的目录结构
- 此模块提供了四个指令:

exact_size关闭时表示以字节方式显示文件大小
concat
- 一次请求返回多个文件的内容(拼接嘛),适用于请求多个小文件的场景
- 阿里云提供,直接在URI上整
- 使用方法:

- 看个例子吧:

- 通过
:::分割取到的文件内容 - 可以有效提升性能哦!
- 通过
- 以上便是请求处理阶段的主要内容,主要是作为静态服务器时的使用方法,如果要接我们的后端服务器,往往只需要反向代理一下
LOG
log_module,日志模块,无法禁用
log_format
指令log_format,设置日志格式,使用方法:


access_log
access_log指令配置日志文件路径:


过滤模块
- 在content阶段之后,log阶段之前,需要对header和body的响应内容进行过滤

- 注意顺序,例如请求到图片后要做缩略图,不能先压缩
- 在HTTP应用的过滤模块中:
- 从C语言引用的顺序看,从上到下依次执行

copy_filter模块,会复制包体内容,例如gzip要对内存中的东西压缩,但是有的模块会不经过nginx直接将内容返回给客户端,此时就需要拷贝一份到内存;所以这也是需要最先考虑的过滤模块- 这个直接返回意思是经历了相应阶段,后端服务器的响应,直接用sendfile在内核态交给socket返回给客户端,没有经过用户态处理
- 后端如果使用nginx代理,响应必须经过nginx返回给客户端
postpone_filter用于处理子请求header_filter构造响应头部write_filter发送响应,即最终的响应是由过滤器发的
- 从C语言引用的顺序看,从上到下依次执行
- 过滤模块是可以改变请求内容的,所以使用的非常广泛
sub_filter
- 替换响应中的字符串

- 看个例子:

last_modified没打开,即内容变了,但头部不会改变,即不显示已经修改
add_before_body
- addition模块在响应的前后添加内容,其做法是发起子请求,将子响应添加
- 使用格式:

- 看个例子:

- 当我们请求根目录时便会返回添加内容的响应
变量
- 变量的使用可以解耦模块,也为处理请求带来很大方便,提升效率
- 模块变量的提供和使用

- 不同模块关注的内容不一样,通过变量实现了只专注于自己的事情,这种架构非常好
- 变量特性
- 惰性求值:开始读取时求值
- 部分变量值时刻变化,其值为使用的那一刻时的值
- 为了提升性能,NGINX涉及了hash表专门存储变量,下面是定义此表容量:

- 除了大量的模块变量,nginx的框架也提供了丰富的变量
- 这里从HTTP框架(应用)提供的请求相关的变量说起
- 看个例子吧:

- 注意看这些变量,很常用
- 例如:
$host是请求域名,不带端口;server_name是主域名

- 变量取值方式:

- URI是统一资源标识符(IP+Port+URL),URL是资源定位符(剩余部分),header是请求头(或响应头)包含了很多信息,可以用Chrome检查

- request变量很常用

- 容易混淆的host

- 对于
http_头部变量名的变量,部分会特殊处理一下,其他都是从头部找到对应头部名,以下是特殊变量:

- 看个例子吧:
- 除了与用户请求相关的,HTTP还有几类变量:

map
- map模块可以映射生成新变量:

- 类似于使用变量进行if条件判断,赋值新变量:

- 使用规则:

- 看个例子:

- 首先,使用已有变量
$http_host值进行匹配,匹配的优先级规则和location是一致的 - 当匹配成功某一规则时,自定义$name的值就会变为对应的0/1/2/3/4
- 如果都没有匹配上,就设为default对应的值
- 首先,使用已有变量
AB测试
- split_clients模块实现:
- 原理:对已有变量的值进行MH算法得到hash数,与最大值相除得到百分比
- 根据此百分比所在的范围决定自定义变量的值
- 指令格式:和map类似

- 都是基于已有变量,map是匹配这里是计算
- 举个例子:
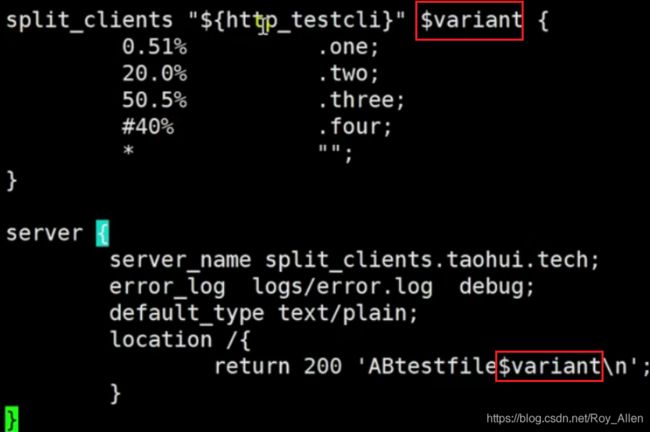
- 根据用户头部传递的名为
testcli的值进行计算

geo
- 根据IP地址创建新变量
geo指令:

- 规则:

- 常用的特性是最长匹配优先和
proxy - 这里所说的IP和子网掩码的范围就是子网匹配即可,此子网下的主机都可以
- 常用的特性是最长匹配优先和
- 看个例子:

- 结果如下:

geoip
- 根据IP地址计算出地理位置
- 和geo同样的,默认不在nginx,重新编译热部署
--with-http_geoip_module - 使用规则:

- 下载geoip的C开发库,官网地址,选择C语言版,安装:
- 解压直接进去,执行
./configure make && make install,数据库文件默认在/uar/local/share/GeoIP下(这不是nginx里面的,单独安装的!)
- 指令:指定存储国家代码和名称的文件

geoip_proxy是添加可信IP地址
- 变量:国家代码和名称

geoip_city指令使用更广泛:

- 提供了以下丰富的变量:

- 看个例子:指定我们编译生成的数据库文件
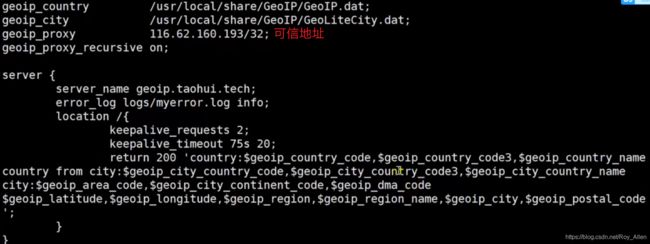
- 这里可信地址是本机IP,同理,此时使用XFIP中的最后一个地址
- 在全网代理IP选取几个IP测试:

- 小结:
- 我们按模块——指令——变量的顺序学习
- 从map到geoip,都是基于变量/IP进行的
防盗链
- nginx中主要的防盗链模块有referer和secure_link,即会通过客户端携带的信息或者让客户端使用安全链接保证安全性
referer
- 此模块形成简单有效的防盗链手段
- 原理:http请求中会带上referer,将访问你这个页面之前的那个页面的url带上,告诉服务器本次请求是这个页面发起的
- 用
invalid_referer变量判断是否合法,允许访问时值为空,不允许是为1 - 相关指令:

- 详细解释下第一个指令:

none和blocked表示没有或者referer为空
- 详细解释下第一个指令:
- 看个例子:
server_name referer.roykun.vip; location / { valid_referers none blocked server_names # 换行 *.roykun.vip www.roykun.org ~\.google\.; if($invaild_referer) { return 403; } return 200 "vaild"; }- 我们访问
curl -H 'referer: http://www.roykun.org/666' referer.roykun.vip返回403,因为包含了URL:/666,字符匹配后也没有*,不能匹配字符串(相当于要精准匹配) - URL可以理解为除了域名和端口的URI部分
- 我们访问
secure_link
- 同理,介绍其变量和功能:

- 变量secure_link值为0表示URL过期,值为1验证通过,值为空表示不通过
- 关键在于生成安全链接
- 注意区分变量和指令
- 指令:

- 说的简单点:配置文件中保存密钥字符串,客户端访问使用这个密钥得到的URL,然后nginx会校验
- 逐个说起,
secure_link:不用管谁生成安全连接(一般是非对称后端服务器)

- 注意看前两行,用了前两个指令:这里用的密钥是“secret”

- 访问的时候带上加密字符串和时间戳,让nginx检验:

- 对URI简单的哈希:不用时间戳,使用第三条指令


- 按照上面生成md5方式得到加密字符串并输出,访问时携带,这里使用密钥mysecret2
- 配置测试文件:

- 小结:两种安全链的使用方法一致;nginx配置密钥,访问时携带通过此密钥加密的字符串,验证后会修改变量的值,通过变量值判断验证是否通过;
keepalive
- 客户端的keepalive行为是HTTP协议定义的,不是nginx,这里的指令可以对其进行控制
- keepalive:顾明思义,“别关”;Connection头部取值为close表示立即关闭,取值为此就复用
- 还有Keep-Alive头部,取值为timeout=n,即连接至少保持多少秒
- 多个客户端通过复用TCP连接提升效率
- 减少握手次数
- 减少并发次数
- 降低TCP拥塞控制的影响
- 指令:

- 上面的指令对应客户端header的设置,不赘述!
小结
- 至此,我们从请求处理的流程出发,一步步详解HTTP应用的各个过程、模块以及主要指令,串点成线
- 理解任何模块都可以先确定其对应的阶段,然后确定在此阶段的执行顺序,大部分模块的顺序是固定的,但有的指令可以更改
- 变量是模块之间解耦的有效手段,这里主要介绍了HTTP应用框架提供的请求的相关变量,还有通过map等自定义变量
- 内容较多,理解不到位之处可以讨论