8. 不一定非得每秒处理一次
由于Spark Streaming的原理是micro batch, 因此当batch积累到一定数量时再发放到集群中计算, 这样的数据吞吐量会更大些. 这需要在StreamingContext中设置Duration参数. 我们试着把Duration调成两秒, 这样Spark就会在接收Kafka的模块中积累了2秒的数据后, 在调度作业到集群中计算.
结合上述做过的优化, 跑了一下, 结果如下:
从统计看到, 在Kafka每2秒发送90000条记录与HDFS上的700万条进行处理并inner join的计算耗时一般能平稳在2秒, 偶尔会有3秒, 那其实是发生了跨节点跨机房的数据传输所造成的.
9. 使用RangePartition或RangeOnHDFSSizePartitioner
但在跑上一轮压力测试时, 发现了如下现象:
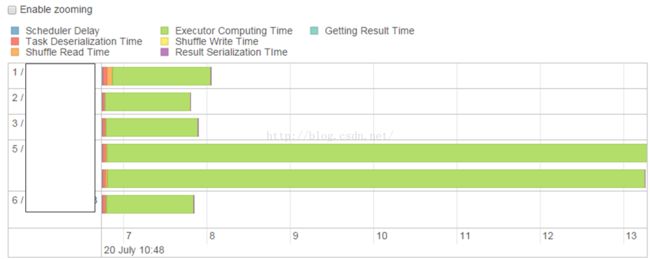
一些节点(executor)上的task set的处理时间明显比其它节点的处理时间要长, 导致其它节点的executor在空等, 也就是所并没有完全利用所有资源, 没有发挥集群所应有的性能.
造成这种情况的原因一般是数据倾斜, 大量的包含了常用key的数据分布在了少数节点上.
这是一个优化点, 而优化目标就是尽量让每个task的处理时间差不多, 把task减小, 让task能均匀分布在各个executor, 并且让task们充满整个executor的生命周期.
一般会用RangePartition或新引入的RangeOnHDFSSizePartitioner来根据数据的key出现的密度对数据进行重新分布. 前者只是普通的按key密度划分, 但可以输入分区数目作为参数; 后者可以根据文件的大小以及key的密度进行划分, 并接收一个分区因子作为参数, “实际分区数 = 根据文件大小计算出来的分区数 * 分区因子 ”. 我这里用的是RangePartition.
在谈一下分区数, 一般来说分区数越多, task会越小, 就越能填满整个executor生命周期, 但task太小太多也会在调度和序列化上耗费大量时间, 输入RangePartition的分区数要适当, 不能太小也不能太大. 这里取的是99.
优化后task的耗时图如下:
可看到各个task是相对均匀地塞满了executor的生命周期.
该优化后, 我们在Kafka每2秒发送90000条记录的基础上增大从HDFS加载的记录数, 增加到2300万条, 以进行处理并inner join, 此时, 也就是90000 * 2300万条数据, 计算耗时依然能平稳在2-3秒.
10. Spark内存分配的优化
在压力测试的过程中, 我们是把加载的HDFS数据缓存到了内存中, 以加快处理速度的, 虽然数据已经解决3G, 但我们看了一下RDD缓存区的内存使用量, 其实还有大量区域没被使用.
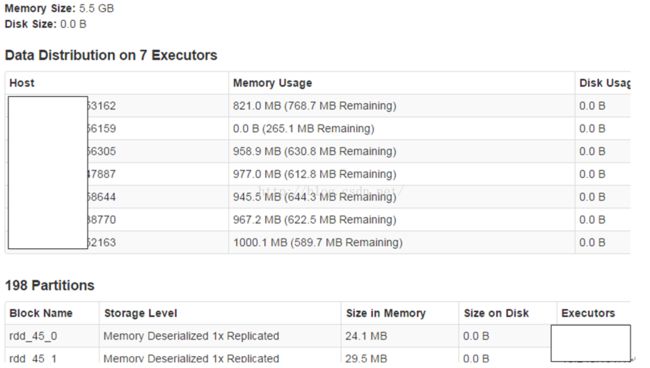
因此我们可以对Spark内部的内存分配进行一下调整, 调高用于shuffle的内存, 调低用于缓存RDD的内存.
大家知道, Spark应用在container上的内存是这样分布的:
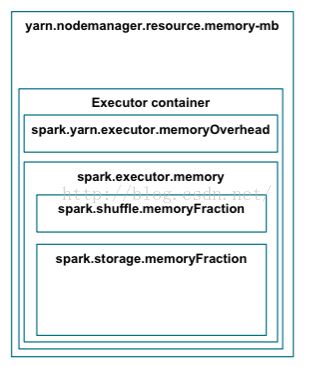
我们可以减少配置项” spark.storage.memoryFraction”的比例数,增大配置项” spark.shuffle.memoryFraction”的比例数, 从RDD缓存区中拿一部分内存出来用于shuffle的计算.
本例中的配置是” spark.storage.memoryFraction=0.45”以及” spark.shuffle.memoryFraction=0.4”. 但调整后GC明显增加, 一些executor甚至出现了使用内存过多而被YARN的NodeManager给kill掉的情况, 在一再确保” spark.storage.memoryFraction=0.45”是足够给RDD缓存使用并还可以保留0.5以上的空余的情况下, 看来下一步就不得不调优Spark应用的GC了.
作者写的一系列stream优化很精彩
转自:https://blog.csdn.net/leone911/article/details/78685123