java inline 直接打开_Java 并发-锁的种类
引言
本文介绍了 JDK 中常用的并发库(JUC)的使用方式, 并且自上而下地剖析了其实现原理,从直接下级框架 AbstractQueuedSynchronizer 也就是大家常说的 AQS,再到其中使用的 CAS, Wait,Park,最后到操作系统层面的 Mutex,Condition,希望通过这篇文章,大家能够对整个 Java 并发有一个清晰全面的认识,而且把这些内容串在一起你会发现它们本质上都是相通的。
锁的种类
在 JUC 中,大量使用到了锁,而 Java 中往往是按照是否含有某一特性来定义锁,我们通过特性将锁进行分组归类,再使用对比的方式进行介绍,帮助大家更快捷的理解相关知识。下面给出本文内容的总体分类目录:
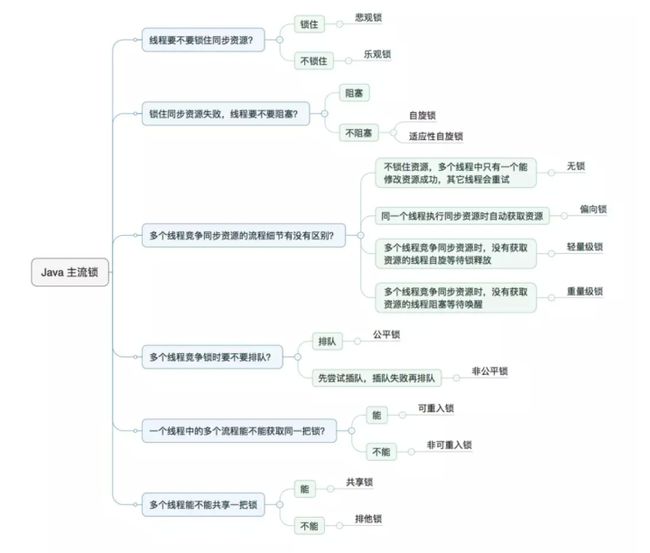
悲观锁与乐观锁
对于同一个数据的并发操作,悲观锁认为自己在使用数据的时候一定有别的线程来修改数据,因此在获取数据的时候会先加锁,确保数据不会被别的线程修改。Java中,synchronized关键字和大部分Lock的实现类都是悲观锁。
而乐观锁认为自己在使用数据时不会有别的线程修改数据,所以不会添加锁,只是在更新数据的时候去判断之前有没有别的线程更新了这个数据。如果这个数据没有被更新,当前线程将自己修改的数据成功写入。如果数据已经被其他线程更新,则根据不同的实现方式执行不同的操作(例如报错或者自动重试)。在 Java 中是通过使用无锁编程来实现,最常采用的是CAS 算法,Java原子类中的递增操作就通过CAS自旋实现的。
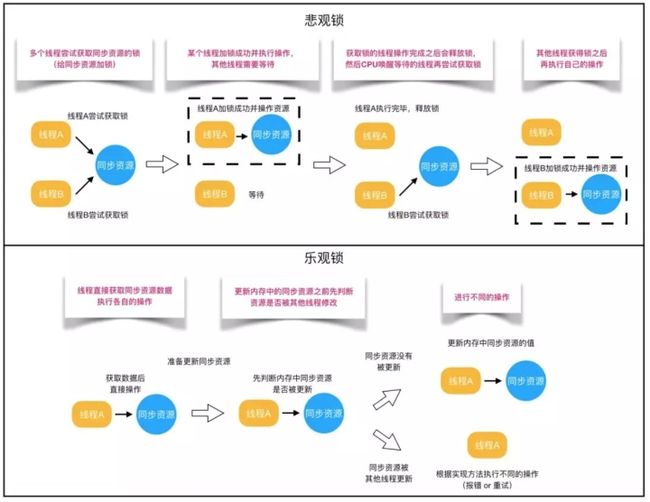
一般来说,当数据的写操作很少,读操作很多时,我们会使用到乐观锁,反之则使用悲观锁。下面是这两种锁使用的例子。
public class LockTest{
private int sum1;
private AtomicInteger sum2 = new AtomicInteger(0);
private int sum3;
private ReentrantLock lock;
/**
* 悲观锁,使用对象的 Monitor 锁
*/
public synchronized void increase1() {
sum1++;
}
/**
* 悲观锁,使用 ReentrantLock 提供的锁
*/
public void increase3() {
lock.lock();
sum3++;
lock.unlock();
}
/**
* 乐观锁,下层通过 CAS 实现
*/
public void increase2() {
sum2.incrementAndGet();
}
}乐观锁实现
这里我们简单地说一下乐观锁使用到的 CAS,关于悲观锁的内容我们后面再说,CAS全称 Compare And Swap(比较与交换),是一种无锁算法。在不使用锁(没有线程被阻塞)的情况下实现多线程之间的变量同步。java.util.concurrent包中的原子类就是通过CAS来实现了乐观锁。
CAS算法涉及到三个操作数:
- 需要读写的内存值 V。
- 进行比较的值 A。
- 要写入的新值 B。
当且仅当 V 的值等于 A 时,CAS通过原子方式用新值B来更新V的值(“比较+更新”整体是一个原子操作),否则不会执行任何操作。一般情况下,“更新”是一个不断重试的操作。
public class AtomicInteger extends Number implements java.io.Serializable {
private static final long serialVersionUID = 6214790243416807050L;
// setup to use Unsafe.compareAndSwapInt for updates
private static final Unsafe unsafe = Unsafe.getUnsafe();
private static final long valueOffset;
static {
try {
valueOffset = unsafe.objectFieldOffset
(AtomicInteger.class.getDeclaredField("value"));
} catch (Exception ex) {
throw new Error(ex); }
}
private volatile int value;
///...
public final int incrementAndGet() {
return unsafe.getAndAddInt(this, valueOffset, 1) + 1;
}
}上述就是 JUC 中原子类的实现,其中 unsafe 是 Java 提供的操作底层内存的接口,CAS 指令就在其中,而这个原子类的实际数据保存在 value 字段中,该属性需要借助volatile关键字保证其在线程间是可见的。 valueOffset 存储了value在AtomicInteger中的偏移量,我们在使用 unsafe 是需要用到它。
接下来,我们深入到 unsafe 中看看它是如何实现 getAndAddInt 的。
public final int getAndAddInt(Object o, long offset, int delta) {
int previousValue;
do {
previousValue = this.getIntVolatile(o, offset);
} while(!this.compareAndSwapInt(o, offset, previousValue, previousValue + delta));
return var5;
}从上述代码中我们可以看到, getAndAddInt 中循环地获取对象 o 中指定 offset 的内存值,并通过 compareAndSwapInt 进行原子化的比较和更新操作。如果更新失败,就重复上述过程。
而 compareAndSwapInt 已经是一个 native 函数了,它的实现如下:
// unsafe.cpp
UNSAFE_ENTRY(jboolean, Unsafe_CompareAndSwapInt(JNIEnv *env, jobject unsafe, jobject obj, jlong offset, jint e, jint x))
UnsafeWrapper("Unsafe_CompareAndSwapInt");
oop p = JNIHandles::resolve(obj);
jint* addr = (jint *) index_oop_from_field_offset_long(p, offset);
return (jint)(Atomic::cmpxchg(x, addr, e)) == e;
UNSAFE_END
代码中能看到 cmpxchg 有基于各个平台的实现,这里我选择Linux X86平台下的源码分析:
// atomic_linux_x86.inline.hpp
inline jint Atomic::cmpxchg (jint exchange_value, volatile jint* dest, jint compare_value) {
int mp = os::is_MP();
__asm__ volatile (LOCK_IF_MP(%4) "cmpxchgl %1,(%3)"
: "=a" (exchange_value)
: "r" (exchange_value), "a" (compare_value), "r" (dest), "r" (mp)
: "cc", "memory");
return exchange_value;
}
// Adding a lock prefix to an instruction on MP machine
#define LOCK_IF_MP(mp) "cmp $0, " #mp "; je 1f; lock; 1: "
这是一段小汇编,asm说明是ASM汇编,volatile禁止编译器优化。
os::is_MP判断当前系统是否为多核系统,如果是就给该数据加锁(总线锁或者缓存锁),所以同一芯片上的其他处理器就暂时不能访问内存,保证了该指令在多处理器环境下的原子性。
在正式解读这段汇编前,我们来了解下嵌入汇编的基本格式:
asm ( assembler template
: output operands /* optional */
: input operands /* optional */
: list of clobbered registers /* optional */
);
其中:
- template就是cmpxchgl %1, (%3)表示汇编模板
- output operands表示输出操作数, =a对应eax寄存器
- input operand 表示输入参数,%1 就是exchange_value, %3是dest, %4就是mp, r表示任意寄存器,a还是eax寄存器
- list of clobbered registers就是些额外参数,cc表示编译器cmpxchgl的执行将影响到标志寄存器, memory告诉编译器要重新从内存中读取变量的最新值
在 Linux X86平台下,最终JDK通过CPU的cmpxchgl指令的支持,实现AtomicInteger的CAS操作的原子性。虽然我们说 CAS 是无锁化的设计,但是在机器指令这一层面来看实际上也会使用到内存锁定,才能达到原子化的目标。
乐观锁的问题
乐观锁虽然很高效,但是它也存在三大问题,这里也简单说一下:
- ABA问题。CAS需要在操作值的时候检查内存值是否发生变化,没有发生变化才会更新内存值。但是如果内存值原来是A,后来变成了B,然后又变成了A,那么CAS进行检查时会发现值没有发生变化,但是实际上是有变化的。ABA问题的解决思路就是在变量前面添加版本号,每次变量更新的时候都把版本号加一,这样变化过程就从“A-B-A”变成了“1A-2B-3A”。
- JDK从1.5开始提供了
AtomicStampedReference类来解决ABA问题,具体操作封装在compareAndSet()中。compareAndSet()首先检查当前引用和当前标志与预期引用和预期标志是否相等,如果都相等,则以原子方式将引用值和标志的值设置为给定的更新值。
- 循环时间长开销大。CAS操作如果长时间不成功,会导致其一直自旋,给CPU带来非常大的开销。
- 只能保证一个共享变量的原子操作。对一个共享变量执行操作时,CAS能够保证原子操作,但是对多个共享变量操作时,CAS是无法保证操作的原子性的。
- Java从1.5开始JDK提供了
AtomicReference类来保证引用对象之间的原子性,可以把多个变量放在一个对象里来进行CAS操作。CAS 操作比较的是对象的地址。
// java.util.concurrent.atomic.AtomicStampedReference#compareAndSet
/**
* Atomically sets the value of both the reference and stamp
* to the given update values if the
* current reference is {@code ==} to the expected reference
* and the current stamp is equal to the expected stamp.
*
* @param expectedReference the expected value of the reference
* @param newReference the new value for the reference
* @param expectedStamp the expected value of the stamp
* @param newStamp the new value for the stamp
* @return {@code true} if successful
*/
public boolean compareAndSet(V expectedReference,
V newReference,
int expectedStamp,
int newStamp) {
Pair current = pair;
return
expectedReference == current.reference &&
expectedStamp == current.stamp &&
((newReference == current.reference &&
newStamp == current.stamp) ||
casPair(current, Pair.of(newReference, newStamp)));
}
private boolean casPair(Pair cmp, Pair val) {
return UNSAFE.compareAndSwapObject(this, pairOffset, cmp, val);
} 无论是上述的 AtomicStampedReference 还是 AtomicReference 最终都是通过 compareAndSwapObject 来实现的,而这个 CAS 操作比较的实际上就是对象的地址。
// Unsafe.h
virtual jboolean compareAndSwapObject(::java::lang::Object *, jlong, ::java::lang::Object *, ::java::lang::Object *);
// natUnsafe.cc
static inline bool
compareAndSwap (volatile jobject *addr, jobject old, jobject new_val)
{
jboolean result = false;
spinlock lock;
// 如果字段的地址与期望的地址相等则将字段的地址更新
if ((result = (*addr == old)))
*addr = new_val;
return result;
}
// natUnsafe.cc
jboolean
sun::misc::Unsafe::compareAndSwapObject (jobject obj, jlong offset,
jobject expect, jobject update)
{
// 获取字段地址并转换为字符串
jobject *addr = (jobject*)((char *) obj + offset);
// 调用 compareAndSwap 方法进行比较
return compareAndSwap (addr, expect, update);
}
阻塞锁与自旋锁
阻塞或唤醒一个Java线程需要操作系统切换CPU状态来完成,这种状态转换需要耗费处理器时间。如果同步代码块中的内容过于简单,状态转换消耗的时间有可能比用户代码执行的时间还要长。我们前面提到的 Monitor 锁 和 ReentrantLock 都是阻塞锁。
在许多场景中,同步资源的锁定时间很短,为了这一小段时间去切换线程,线程挂起和恢复现场的花费可能会让系统得不偿失。如果物理机器有多个处理器,能够让两个或以上的线程同时并行执行,我们就可以让后面那个请求锁的线程不放弃CPU的执行时间,看看持有锁的线程是否很快就会释放锁。
而为了让当前线程“稍等一下”,我们需让当前线程进行自旋,如果在自旋完成后前面锁定同步资源的线程已经释放了锁,那么当前线程就可以不必阻塞而是直接获取同步资源,从而避免切换线程的开销。这就是自旋锁。这很类似于前面 AtomicInteger 的实现方式, AtomicInteger CAS 的期待值是 previousValue,目标值可能是任意一个数,而一般在自旋锁中,用 0 表示未锁定状态,用 1 表示锁定状态,那么加锁过程CAS的期待值就是0,目标值就是 1。
public class SpinLock {
private AtomicBoolean locked = new AtomicBoolean(false);
public void lock() {
while (!locked.compareAndSet(false, true));
}
public void unlock() {
locked.set(false);
}
}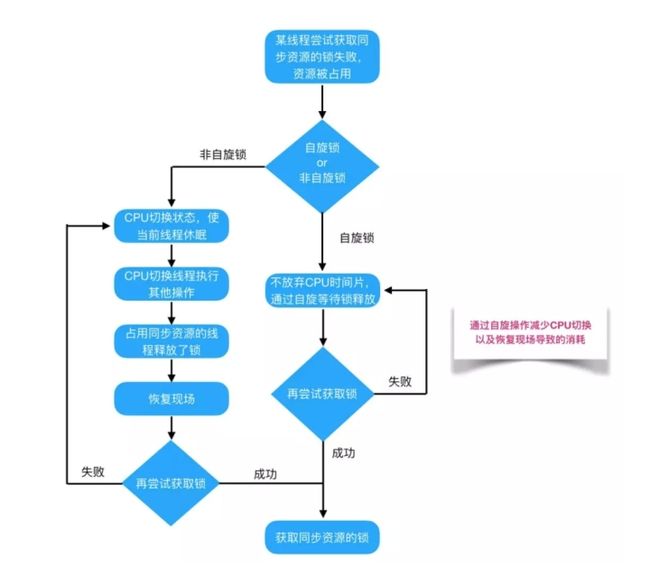
自旋锁本身是有缺点的,它不能代替阻塞。自旋等待虽然避免了线程切换的开销,但它要占用处理器时间。如果锁被占用的时间很短,自旋等待的效果就会非常好。反之,如果锁被占用的时间很长,那么自旋的线程只会白浪费处理器资源。所以,自旋等待的时间必须要有一定的限度,如果自旋超过了限定次数还没有成功获得锁,就应当挂起线程。
既然自旋锁的等待过程这么浪费 CPU,那么我们有没有什么办法能够改善它呢?JDK 6中引入了自适应的自旋锁(适应性自旋锁)。自适应意味着自旋的时间(次数)不再固定,而是由前一次在同一个锁上的自旋时间及锁的拥有者的状态来决定。如果在同一个锁对象上,自旋等待刚刚成功获得过锁,并且持有锁的线程正在运行中,那么虚拟机就会认为这次自旋也是很有可能再次成功,进而它将允许自旋等待持续相对更长的时间。如果对于某个锁,自旋很少成功获得过,那在以后尝试获取这个锁时将可能省略掉自旋过程,直接阻塞线程,避免浪费处理器资源。
Synchronized 锁
在 Java 中 synchronized 锁包括 synchronized 方法和 synchronized 代码块:
public class Test {
public void synchronizedBlock() {
synchronized (this) {
System.out.println("synchronizedMethod");
}
}
public synchronized void synchronizedMethod() {
System.out.println("synchronizedMethod");
}
}上述代码两个函数生成的字节码如下所示:
// synchronizedBlock
// access flags public
0 aload_0
1 dup
2 astore_1
3 monitorenter
4 getstatic #2
7 ldc #3
9 invokevirtual #4
12 aload_1
13 monitorexit
14 goto 22 (+8)
17 astore_2
18 aload_1
19 monitorexit
20 aload_2
21 athrow
22 return
// synchronizedMethod
// access flags public synchronized
0 getstatic #2
3 ldc #3
5 invokevirtual #4
8 return 从字节码中,我们会发现编译器会将同步代码块用 monitorenter 和 monitorexit 包裹,这里因为有隐式的 try-finally 所以有两个 monitorexit ,而同步方法,则是通过函数的的 access flags 进行标识,当执行有 synchronized 标识的函数时,最后也会调用 monitorenter 和 monitorexit 基本一样的逻辑。
在 JDK 1.6 之前, synchronized 只使用了系统层提供的锁机制,例如 Linux 平台上的 mutex,这会造成进程间切换的开销,所以性能并不理想。在 JDK 1.6 引入了两种新型锁机制:偏向锁和轻量级锁,它们的引入是为了解决在没有多线程竞争或基本没有竞争的场景下因使用传统锁机制带来的性能开销问题。JVM 会根据竞争的强度来选用不同的锁实现,来降低锁的使用开销。那么 JVM 是如何实现这么多种类型的锁的呢?在 JVM 的实现中,每个对象都有一个对象头,用于保存对象的系统信息。对象头中有一个成为 Mark Word 的部分,它是实现锁的关键。在 32 位系统中,它是一个 32 位的数据,在 64 位系统中,它占 64 位。它是一个多功能的数据区,可以存放对象的哈希值,对象年龄,所得指针等数据。一个对象使用了哪种锁实现,谁占用了锁,都记录在这个 Mark Word 中。下表展示了 32 位 HotSpot 虚拟机中 Mark Word 的存储情况。
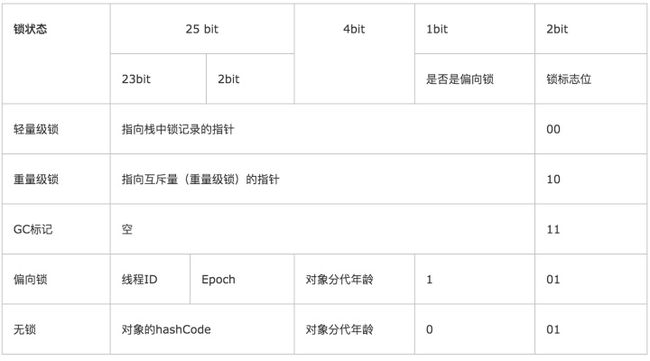
可以看到锁信息也是存在于对象的 mark word 中的。当对象状态为偏向锁(biasable)时,mark word 存储的是偏向的线程 ID;当状态为轻量级锁(lightweight locked)时,mark word 存储的是指向线程栈中 Lock Record 的指针;当状态为重量级锁(inflated)时,为指向堆中的 monitor 对象的指针。接下来,我们介绍一下这三种类型的锁都具有什么样的特点,以及它们的实现方式。
偏向锁
在 JDK1.6 中为了提高一个对象在一段很长的时间内都只被一个线程用做锁对象场景下的性能,引入了偏向锁,在第一次获得锁时,会有一个 CAS 操作,之后该线程再获取锁,只会执行几个简单的命令,而不是开销相对较大的 CAS 命令。
- 当 JVM 启动了偏向锁模式(1.6 以上默认开启)并且锁对象的 Class 没有关闭偏向锁模式时,该锁对象初始的
mark word将是可偏向状态,此时的thread id为 0,表示当前没有任何一个线程持有该锁。 - 获得锁的逻辑:
- 如果该对象是第一次被线程获得锁时,会先在当前线程栈中找到一个可用的 Lock Record 并将其 obj 指向锁对象,Displaced Mark Word 置为空,然后根据
mark word确认当前锁是否处于未偏向模式,如果处于未偏向模式则会通过 CAS 指令,将mark word中的thread id0 改为当前线程 id。如果成功,则说明获得了偏向锁,继而执行同步块中的代码,否则,说明当前存在多线程竞争,不适合使用偏向锁,开始执行锁的升级逻辑,锁的升级我们后面介绍。
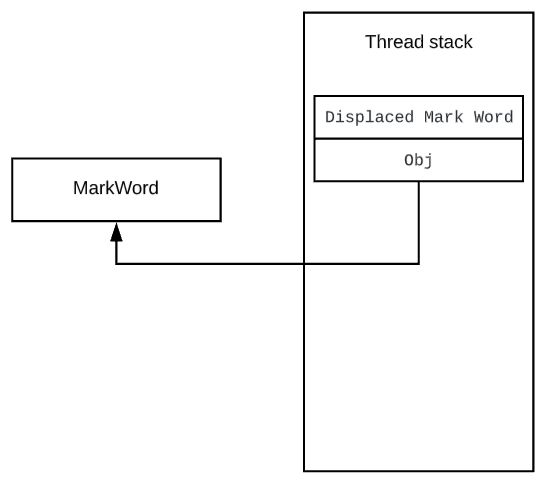
-
- 当被偏向的线程再次进入同步块时,发现锁对象偏向的就是当前线程(thread id),会再往当前线程的栈中添加一条 Displaced Mark Word 为空的 Lock Record(通过它来实现可重入锁),然后继续执行同步块的代码,因为操纵的是线程私有的栈,因此不需要用到 CAS 指令,因为如此偏向锁模式下,当被偏向的线程再次尝试获得锁时,仅仅进行几个简单的操作就可以了,在这种情况下,synchronized 关键字带来的性能开销基本可以忽略。
- 当其他线程进入同步块时,发现已经有偏向的线程了,则会进入到撤销偏向锁的逻辑
- 锁的升级逻辑:当发现多线程竞争时,偏向锁会升级为轻量级锁,一般来说,会在 safepoint(此时用户代码不会执行)中去查看偏向的线程是否还存活,如果存活且还在同步块中(根据栈帧中是否还有 obj 指向该锁对象的 Lock Record)则将锁升级为轻量级锁,原偏向的线程继续拥有锁,当前线程则走入到轻量级锁的加锁逻辑中;如果偏向的线程已经不存活或者不在同步块中,则将对象头的 mark word 改为无锁状态(unlocked),之后再升级为轻量级锁。
锁升级的过程是在 JVM 中专门的 VM Thread 中执行,该线程会源源不断的从 VMOperationQueue 中取出请求,比如 GC 请求和锁升级请求都会被推入该请求队列中。对于需要 safepoint 的操作,必须要等到所有的 Java 线程进入到 safepoint 才开始执行。 - 解锁逻辑:将栈中最近的的一个 lock record 的 obj 字段设置为 null(该 obj 字段原本指向锁对象)。需要注意的是,偏向锁的解锁步骤中并不会修改对象头中的 thread id。
- 批量重偏向:当只有一个线程反复进入同步块时,偏向锁带来的性能开销基本可以忽略,但是当有其他线程尝试获得锁时,就需要等到 safe point 时将偏向锁撤销并升级。而偏向锁的撤销是有一定成本的,如果说运行时的场景本身存在多线程竞争的,那偏向锁的存在不仅不能提高性能,而且会导致性能下降。因此,JVM 中增加了一种批量重偏向机制。它主要是为了解决如下问题:一个线程 A 创建了大量锁对象并执行了初始的同步操作,此时线程 A 是偏向锁的持有者,但是之后线程 A 不再使用该锁,而是另一个线程 B 期望持有这些锁对象并进行之后的所有操作。在这种情况下,按照正常的逻辑,所有的偏向锁都会被撤销并升级为轻量级锁,这样即便是之后总是线程 B 一个线程使用这些锁,也不能享受到偏向锁的性能优势了。怎么解决这个问题呢?JVM 会以 class 为单位,为每个 class 维护一个偏向锁撤销计数器,每当该 class 的任意实例对象发生偏向撤销操作时,该 class 的计数器 +1。当达到阈值(20)时,JVM 就会进行批量重偏向。当发生重偏向时,会更新 class 的 epoch 和 当前处于加锁状态的对象的 epoch,注意:对象在创建出来时,会复用其 class 当前的 epoch 值,而在发生批量重偏向时,只有真正处于锁定状态的对象 epoch 才会和 class 的 epoch 一起 +1,而不处于锁定状态的对象 epoch 不变(即线程栈中不存在对应 Lock Record 的锁对象)。这时候,如果线程 B 想要持有锁对象时,如果发现对象的 epoch 和其 class 的epoch 不等,可以不执行偏向锁撤销的逻辑,直接将 mark word 中的 thread id 通过 CAS 改为自己的 thread id。这样就避免偏向锁撤销的性能损耗,并且继续享受偏向锁带来的性能优势。
- 批量撤销:如果一些锁存在明显的多线程竞争,那么每个锁对象都要从偏向锁逐步升级到轻量级锁,显然会造成很大的性能损耗,所以,JVM 引入了一个直接跳过偏向锁的机制。就想批量重偏向时所说的,每个 class 都有一个计数器,该计数器在 class 对象发生偏向锁撤销时 +1,当该计数器达到更高阈值(40)时,JVM 会认定该 class 存在明显的竞争,不适合使用偏向锁,之后该 class 的所有对象都不再使用偏向锁,而是直接使用轻量级锁。
理解了偏向锁的各个处理过程之后,我们来看一下下面这张图,其中展示了偏向锁状态的切换流程:
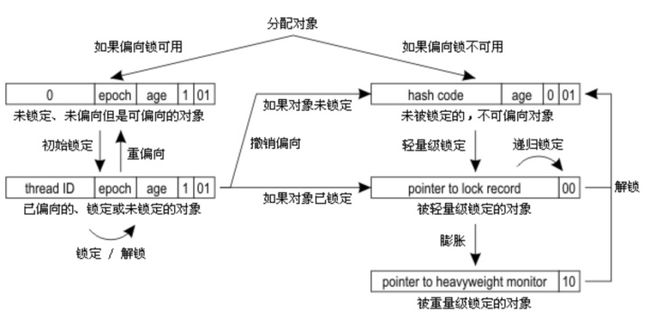
从图中最上面出发会分为偏向锁可用和不可用:
- 可用:默认模式
- 不可用:锁对象已经发生了撤销(多线程竞争),该 class 已经发生了批量撤销(该 class 的很多个实例都发生了多线程竞争),偏向锁在 JVM 层关闭
然后我们看一下偏向锁可用这一支:
- 初始锁定:更新 thread id,线程栈中添加指向锁对象的 Lock Record
- 再次锁定:mark word 不变,只在线程栈中添加指向锁对象的 Lock Record
- 解锁:mark word 不变,只在线程栈中删除一个指向锁对象的 Lock Record
- 重偏向:该 class 对象发生了很多次撤销,引发重偏向,class 的 epoch 和处于锁定状态(存在指向锁对象的 Lock Record)的对象(我们称这批锁对象为 Group A) epoch +1,其他空闲但是 thread id 不为 0 的锁对象(我们称这批锁对象为 Group B) epoch 不变,当另一个线程尝试获取获取 Group B 的锁时,虽然其 threadID 不为 0,但是因为其 epoch 和 class 的 epoch 不一致,所以可以把它当做 thread id = 0 来看待。
然后我们看一下从左支到右支的升级过程:
- 如果发现多线程竞争,并且当前锁持有线程没有在同步代码中(不存在指向锁对象的 Lock Record),那么先将该锁恢复到未锁定状态,并标记该锁不可使用偏向模式,然后开始轻量级锁的加锁逻辑,这部分我们后面介绍。
- 如果发现多线程竞争,并且当前锁持有线程在同步代码中(存在指向锁对象的 Lock Record),那么我们需要将该锁升级到轻量级模式,并让原来持有锁的线程继续持有该锁,然后当前线程按照轻量级锁的加锁流程开始竞争该锁。
至此,上图中关于偏向锁的部分就都介绍完了,接下来,我们介绍一下轻量级锁的实现和升级流程。
轻量级锁
JVM 的开发者发现在很多情况下,在 Java 程序运行时,同步块中的代码都是不存在竞争的,不同的线程交替的执行同步块中的代码。这种情况下,用重量级锁是没必要的。因此 JVM 引入了轻量级锁的概念。
线程在执行同步块之前,JVM 会先在当前的线程的栈帧中创建一个 Lock Record,其包括一个用于存储对象头中的 mark word(官方称之为 Displaced Mark Word)以及一个指向对象的指针。下图右边的部分就是一个 Lock Record。可以看到 Displaced Mark Word 中保存了 mark word 中原来的内容,然后 mark work 变为指向该 Lock Record 的指针。
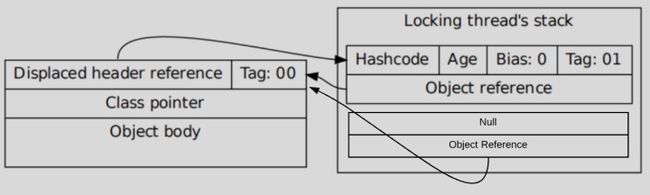
轻量级锁的 Lock Record 和偏向锁 Lock Record 的区别就在这个 Displaced Mark Word,在偏向锁的所有 Lock Record 的 Displaced Mark Word 都为 null,而在轻量级锁中,会存在一个 Displaced Mark Word 不为空的 Lock Record。然后 mark word 中会保存一个指向该 Lock Record 的指针。而如果一个线程重复获取该锁(重入锁),后续加锁过程只会添加 Displaced Mark Word 为 null 的 Lock Record,这部分就和偏向锁一样了。看到这,想必大家已经清楚从偏向锁到轻量级锁的直接升级过程了,就是将一个 Displaced Mark Word 本为 null 的 LockRecord 更新,复制 mark word 中的内容,然后通过 CAS 将 mark word 改为指向该 Lock Record 的指针。
总结一下轻量级锁的处理流程:
- 加锁逻辑:
- 在线程栈中创建一个 Lock Record(Displaced Mark Word 复制 mark word 中的现有内容),将其 obj(即上图的Object reference)字段指向锁对象。
- 直接通过 CAS 指令将 Lock Record 的地址存储在对象头的 mark word 中,如果对象处于无锁状态则修改成功,代表该线程获得了轻量级锁。如果失败,进入到步骤 3。
- 如果是当前线程已经持有该锁了,代表这是一次锁重入。设置 Lock Record 第一部分(Displaced Mark Word)为 null,起到了一个重入计数器的作用,然后结束。
- 走到这一步说明发生了竞争,可能需要膨胀为重量级锁,具体过程后面介绍。
- 解锁逻辑:
- 查找线程栈, 找到 obj 字段等于当前锁对象的 Lock Record。
- 如果 Lock Record 的 Displaced Mark Word 为 null,代表这是一次重入,将 obj 设置为 null 即可。
- 如果 Lock Record 的 Displaced Mark Word 不为 null,则利用 CAS 指令将对象头的 mark word 恢复成为 Displaced Mark Word 的内容。如果成功,则锁被释放,否则说明当前锁已经被膨胀为重量级锁,这时候需要执行重量级锁的释放逻辑。
- 锁的升级:
- 从偏向锁升级到轻量级锁: 将一个 Displaced Mark Word 本为 null 的 LockRecord 更新,复制 mark word 中的内容,然后通过 CAS 将 mark word 改为指向该 Lock Record 的指针。
- 轻量级锁升级到重量级锁: 若当前一个线程 A 持有锁,而且只有一个线程 B 想要获取该锁,则该线程 B 通过自旋进行等待。但是当自旋超过一定的次数,或者一个线程 A 在持有锁,一个线程 B 在自旋等待,又有第三个线程 C 来访时,轻量级锁升级为重量级锁。
重量级锁
重量级锁是我们常说的传统意义上的锁,其利用操作系统底层的同步机制去实现 Java 中的线程同步。重量级锁的状态下,对象的 mark word 为指向一个堆中 monitor 对象的指针。
一个 monitor 对象包括这么几个关键字段:ContentionList,EntryList ,WaitSet,owner。其中 cxq(ContentionList) ,EntryList ,WaitSet 都是由 ObjectWaiter 的链表结构,owner 指向持有锁的线程。
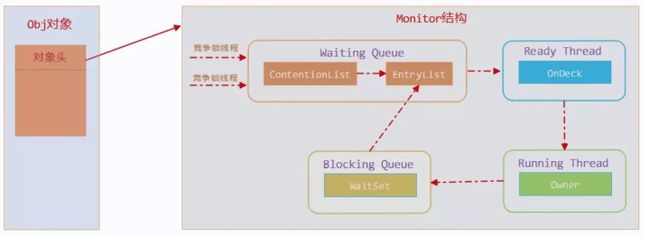
当一个线程尝试获得锁时,如果该锁已经被占用,则会将该线程封装成一个 ObjectWaiter 对象插入到 ContentionList 的队列,然后暂停当前线程, ContentionList 类似于一个 CopyOnWriteList 的角色,来减少 EntryList 的竞争。当持有锁的线程释放锁前,会将 ContentionList 中的所有元素移动到 EntryList 中去,并唤醒 EntryList 的队首线程。这个选中的线程叫做 Heir presumptive 即假定继承人,就是图中的 Ready Thread,假定继承人被唤醒后会尝试获得锁,但 synchronized 是非公平的,所以假定继承人不一定能获得锁,它其实会和当前正准备获得锁的线程进行争夺,这也就是为什么使用 synchronized 时,有可能最后申请锁的线程反而第一个拿到了锁。
如果一个线程在同步块中调用了 Object#wait 方法,会将该线程对应的 ObjectWaiter 从 EntryList 移除并加入到 WaitSet 中,然后释放锁。当 wait 的线程被 notify 之后,会将对应的 ObjectWaiter 从 WaitSet 移动到 EntryList 中。需要注意的是,当调用一个锁对象的 wait 或 notify 方法时,如当前锁的状态是偏向锁或轻量级锁则会先膨胀成重量级锁。因为偏向锁和轻量级锁是不具备进程切换能力的。
最后回到升级示意图中,我们可以介绍最右下角的部分了:
当轻量级锁状态发生严重的竞争时(或者调用了锁对象 wait 或 notify 方法),会创建一个 monitor 对象(需要根据当前锁的持有情况进行 monitor 的初始化),然后将 mark word 改为指向该 monitor 的指针。
公平锁和非公平锁
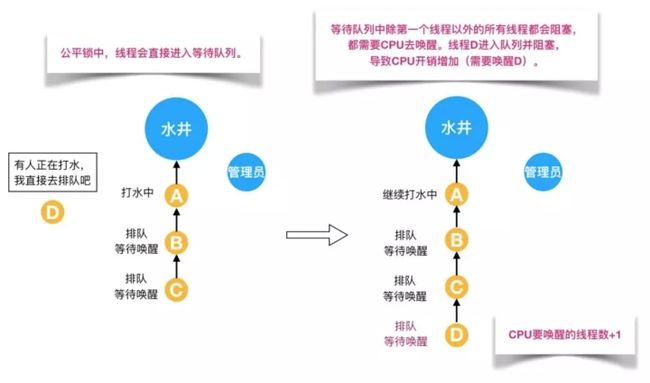
公平锁是指多个线程按照申请锁的顺序来获取锁,线程直接进入队列中排队,队列中的第一个线程才能获得锁。公平锁的优点是等待锁的线程不会饿死。缺点是整体吞吐效率相对非公平锁要低,等待队列中除第一个线程以外的所有线程都会阻塞,CPU唤醒阻塞线程的开销比非公平锁大。
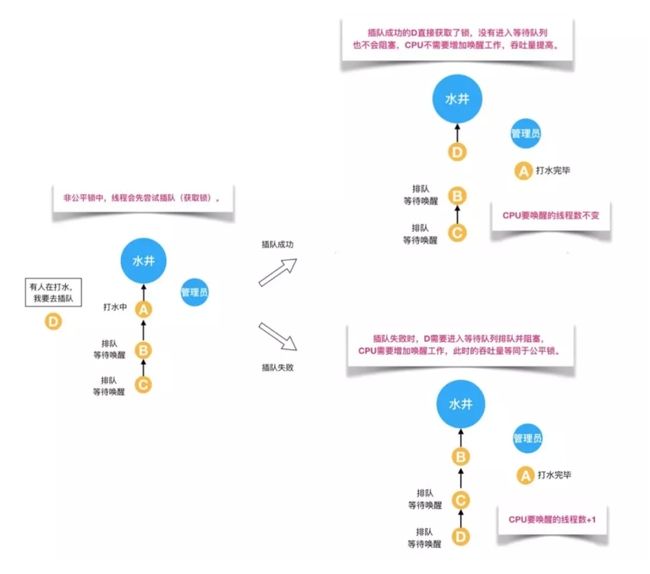
非公平锁是多个线程加锁时直接尝试获取锁,获取不到才会到等待队列的队尾等待。但如果此时锁刚好可用,那么这个线程可以无需阻塞直接获取到锁,所以非公平锁有可能出现后申请锁的线程先获取锁的场景。非公平锁的优点是可以减少唤起线程的开销,整体的吞吐效率高,因为线程有几率不阻塞直接获得锁,CPU不必唤醒所有线程。缺点是处于等待队列中的线程可能会饿死,或者等很久才会获得锁。
我们知道在 ReentrantLock 中,我们即可以使用公平锁,又可以使用非公平锁,不妨来看看它们分别是怎么实现的。在 ReentrantLock 中,锁的核心都是通过 Sync 对象实现,它继承自 AbstractQueuedSynchronizer(AQS) ,AQS 是一个集成了等待队列与锁与一身的基类,很多 JUC 中的库都是建立在其上开发的。我们之后会详细介绍到它,这里先来看一下公平锁和非公平锁的实现方式。
/**
* Fair version of tryAcquire. Don't grant access unless
* recursive call or no waiters or is first.
*/
protected final boolean tryAcquire(int acquires) {
final Thread current = Thread.currentThread();
int c = getState();
if (c == 0) {
if (!hasQueuedPredecessors() && // 先检查任务队列中是否有排在自己前面的线程等待
compareAndSetState(0, acquires)) {
// 没有的话,自己再试图获取锁
setExclusiveOwnerThread(current);
return true;
}
}
else if (current == getExclusiveOwnerThread()) {
// 如果已经是自己持有锁,则计数器加1
int nextc = c + acquires;
if (nextc < 0)
throw new Error("Maximum lock count exceeded");
setState(nextc);
return true;
}
return false;
}
/**
* Performs non-fair tryLock. tryAcquire is implemented in
* subclasses, but both need nonfair try for trylock method.
*/
final boolean nonfairTryAcquire(int acquires) {
final Thread current = Thread.currentThread();
int c = getState();
if (c == 0) {
if (compareAndSetState(0, acquires)) {
// 非公平锁直接试图加锁,不检查等待队列
setExclusiveOwnerThread(current);
return true;
}
}
else if (current == getExclusiveOwnerThread()) {
// 如果已经是自己持有锁,则计数器加1
int nextc = c + acquires;
if (nextc < 0) // overflow
throw new Error("Maximum lock count exceeded");
setState(nextc);
return true;
}
return false;
}从上面的代码中,我们不难发现,公平锁和非公平锁就差一行,即 !hasQueuedPredecessors() , 该方法主要做一件事情:主要是判断当前线程是否位于同步队列中的第一个。如果是则返回true,否则返回false。
/**
* Queries whether any threads have been waiting to acquire longer
* than the current thread.
*
* An invocation of this method is equivalent to (but may be
* more efficient than):
*
{@code
* getFirstQueuedThread() != Thread.currentThread() &&
* hasQueuedThreads()}
*
* Note that because cancellations due to interrupts and
* timeouts may occur at any time, a {@code true} return does not
* guarantee that some other thread will acquire before the current
* thread. Likewise, it is possible for another thread to win a
* race to enqueue after this method has returned {@code false},
* due to the queue being empty.
*
*
This method is designed to be used by a fair synchronizer to
* avoid barging.
* Such a synchronizer's {@link #tryAcquire} method should return
* {@code false}, and its {@link #tryAcquireShared} method should
* return a negative value, if this method returns {@code true}
* (unless this is a reentrant acquire). For example, the {@code
* tryAcquire} method for a fair, reentrant, exclusive mode
* synchronizer might look like this:
*
*
{@code
* protected boolean tryAcquire(int arg) {
* if (isHeldExclusively()) {
* // A reentrant acquire; increment hold count
* return true;
* } else if (hasQueuedPredecessors()) {
* return false;
* } else {
* // try to acquire normally
* }
* }}
*
* @return {@code true} if there is a queued thread preceding the
* current thread, and {@code false} if the current thread
* is at the head of the queue or the queue is empty
* @since 1.7
*/
public final boolean hasQueuedPredecessors() {
// The correctness of this depends on head being initialized
// before tail and on head.next being accurate if the current
// thread is first in queue.
Node t = tail; // Read fields in reverse initialization order
Node h = head;
Node s;
// 队列中第一个节点是一个虚节点,如果 tail == head 说明只存在该虚节点,不存在实际数据
// 当 tail != head 时判断 head.next 是不是等于 null,等于 null 也说明不存在实际数据,
// 最后如果 head.next.thread == Thread.currentThread() 的话说明持有锁的是当前线程
return h != t &&
((s = h.next) == null || s.thread != Thread.currentThread());
}综上,公平锁就是通过同步队列来实现多个线程按照申请锁的顺序来获取锁,从而实现公平的特性。非公平锁加锁时不考虑排队等待问题,直接尝试获取锁,所以存在后申请却先获得锁的情况。这里我们先介绍到这一层,关于 ReentrantLock 的更下层实现细节,我们后面再展开。
可重入和不可重入
可重入锁又名递归锁,是指在一个线程已经持有锁的前提下,可以再次获得该锁,不会因为之前已经获取过还没释放而阻塞。Java中 ReentrantLock 和 synchronized 都是可重入锁,可重入锁的一个优点是可一定程度避免死锁。
public class LockTest{
public synchronized void doSomeThing() {
doOtherThings();
}
public synchronized void doOtherThings() {
// doOtherThings
}
}如果是一个不可重入锁,那么当前线程在调用doOtherThings()之前需要将执行doSomeThing()时获取当前对象的锁释放掉,实际上该对象锁已被当前线程所持有,且synchronized锁无法显式释放,所以此时会出现死锁。
前面提到的 ReentrantLock 是一个可重入锁,从它的加锁代码中,我们不难发现加锁成功时,如果发现当前线程已经是持有锁的线程,则会通过一个 int 来保存重入次数。
/**
* Fair version of tryAcquire. Don't grant access unless
* recursive call or no waiters or is first.
*/
protected final boolean tryAcquire(int acquires) {
final Thread current = Thread.currentThread();
int c = getState();
if (c == 0) {
if (!hasQueuedPredecessors() &&
compareAndSetState(0, acquires)) {
setExclusiveOwnerThread(current);
return true;
}
}
else if (current == getExclusiveOwnerThread()) {
int nextc = c + acquires; // 通过一个 int 来保存重入次数
if (nextc < 0)
throw new Error("Maximum lock count exceeded");
setState(nextc);
return true;
}
return false;
}而在解锁时,则会将重入次数减1,直到该值为0时,才真正的释放锁。
protected final boolean tryRelease(int releases) {
int c = getState() - releases;
if (Thread.currentThread() != getExclusiveOwnerThread())
throw new IllegalMonitorStateException();
boolean free = false;
if (c == 0) {
// 直到该值为0时,才真正的释放锁
free = true;
setExclusiveOwnerThread(null);
}
setState(c);
return free;
}而当我们要实现一个不可重入锁时,我们可以简单地认为 0 就代表未锁定,1就代表锁定,没有其他状态。代码如下:
protected boolean tryAcquire(int acquires) {
if (compareAndSetState(0, 1)) {
owner = Thread.currentThread();
return true;
}
return false;
}
protected boolean tryRelease(int releases) {
if (Thread.currentThread() != owner) {
throw new IllegalMonitorStateException();
}
owner = null;
setState(0);
return true;
}独占锁和共享锁
独享锁也叫排他锁,是指该锁一次只能被一个线程所持有。如果线程T对数据A加上排它锁后,则其他线程不能再对A加任何类型的锁。获得排它锁的线程即能读数据又能修改数据。JDK中的synchronized和JUC中Lock的实现类就是互斥锁。
共享锁是指该锁可被多个线程所持有。如果线程T对数据A加上共享锁后,则其他线程只能对A再加共享锁,不能加排它锁。获得共享锁的线程只能读数据,不能修改数据。
独享锁与共享锁也是通过AQS来实现的,通过实现不同的方法,来实现独享或者共享。
在 ReentrantReadWriteLock 中,有两把锁,一个读锁,一个写锁,它们两个是对外暴露的接口。外层使用者需要使用不同的锁来达到不同的线程控制效果。
public class ReentrantReadWriteLock
implements ReadWriteLock, java.io.Serializable {
/** Inner class providing readlock */
private final ReentrantReadWriteLock.ReadLock readerLock;
/** Inner class providing writelock */
private final ReentrantReadWriteLock.WriteLock writerLock;
/** Performs all synchronization mechanics */
final Sync sync;
}
public interface ReadWriteLock {
/**
* Returns the lock used for reading.
*
* @return the lock used for reading
*/
Lock readLock();
/**
* Returns the lock used for writing.
*
* @return the lock used for writing
*/
Lock writeLock();
}而无论是读锁,还是写锁,它们都是通过同一个 Sync 对象来进行控制的, 也就是 ReentrantReadWriteLock 对象中的 sync。
public static class ReadLock implements Lock, java.io.Serializable {
private static final long serialVersionUID = -5992448646407690164L;
private final Sync sync;
protected ReadLock(ReentrantReadWriteLock lock) {
sync = lock.sync;
}
}
public static class WriteLock implements Lock, java.io.Serializable {
private static final long serialVersionUID = -4992448646407690164L;
private final Sync sync;
protected WriteLock(ReentrantReadWriteLock lock) {
sync = lock.sync;
}
}既然在ReentrantReadWriteLock里面,读锁和写锁的锁主体都是Sync,但读锁和写锁的加锁方式不一样。读锁是共享锁,写锁是独享锁。读锁的共享锁可保证并发读非常高效,而读写、写读、写写的过程互斥,因为读锁和写锁是分离的。那读锁和写锁的具体加锁方式有什么区别呢?
这里我们先会回顾一下之前的互斥锁,当时我们使用到了 state字段(int类型,32位),该字段用来描述有多少线程获持有锁。在独享锁中这个值通常是0或者1(如果是重入锁的话state值就是重入的次数),在共享锁中state就是持有锁的数量。
但是在ReentrantReadWriteLock中有读、写两把锁,所以需要在一个整型变量state上分别描述读锁和写锁的数量(或者也可以叫状态)。于是将state变量“按位切割”切分成了两个部分,高16位表示读锁状态(读锁个数),低16位表示写锁状态(写锁个数)。如下图所示:

我们先来一下写锁的实现逻辑:
- 首先获取当前的状态 state 值
- 取状态值的后16位作为 writeState 值
- 如果当前状态值 state 不为 0,则说明要么写锁被占用要么读锁被占用
- 如果 writeState 为 0,说明有读锁占用,获取锁失败,也就是说如果一个线程先获取读锁,再获取写锁的话,会发生死锁
- 如果 writeState 不为0,需要看一下当前线程和持有锁的线程是否是同一个线程,是的话就加锁成功(重入锁),否则加锁失败
- 走到第四步说明 state 为空,这时候,检查 writerShouldBlock 它实际上是为了实现公平锁而出现的,
- 如果是公平锁 writerShouldBlock 的内容就是确认队列中有没有前驱节点
- 非公平锁则直接是 false
- 如果第四步返回了false,就尝试进行 CAS 加锁,如果 CAS 失败,则加锁失败,否则加锁成功,将当前持有锁的线程置为当前线程。
protected final boolean tryAcquire(int acquires) {
/*
* Walkthrough:
* 1. If read count nonzero or write count nonzero
* and owner is a different thread, fail.
* 2. If count would saturate, fail. (This can only
* happen if count is already nonzero.)
* 3. Otherwise, this thread is eligible for lock if
* it is either a reentrant acquire or
* queue policy allows it. If so, update state
* and set owner.
*/
Thread current = Thread.currentThread();
int c = getState();
int w = exclusiveCount(c);
if (c != 0) {
// (Note: if c != 0 and w == 0 then shared count != 0)
// w == 0 说明有线程持有读锁,w != 0 需要检查当前持有排它锁的线程是不是当前线程,不是的话就加锁失败
if (w == 0 || current != getExclusiveOwnerThread())
return false;
// 当前线程重入,计数器增加
if (w + exclusiveCount(acquires) > MAX_COUNT)
throw new Error("Maximum lock count exceeded");
// Reentrant acquire
setState(c + acquires);
return true;
}
if (writerShouldBlock() ||
!compareAndSetState(c, c + acquires))
return false;
setExclusiveOwnerThread(current);
return true;
}
static int exclusiveCount(int c) {
return c & EXCLUSIVE_MASK; }
static final int EXCLUSIVE_MASK = (1 << SHARED_SHIFT) - 1;
static final int SHARED_SHIFT = 16;
static final class NonfairSync extends Sync {
final boolean writerShouldBlock() {
return false; // writers can always barge
}
}
static final class FairSync extends Sync {
final boolean writerShouldBlock() {
return hasQueuedPredecessors();
}
}ReentrantReadWriteLock 的tryAcquire()相较于 ReentrantLock 来说,除了重入条件(当前线程为获取了写锁的线程)之外,增加了一个读锁是否存在的判断。如果存在读锁,则写锁不能被获取,原因在于:必须确保写锁的操作对读锁可见,如果允许读锁在已被获取的情况下对写锁的获取,那么正在运行的其他读线程就无法感知到当前写线程的操作。
因此,只有等待其他读线程都释放了读锁,写锁才能被当前线程获取,而写锁一旦被获取,则其他读写线程的后续访问均被阻塞。写锁的释放与ReentrantLock的释放过程基本类似,每次释放均减少写状态,当写状态为0时表示写锁已被释放,然后等待的读写线程才能够继续访问读写锁,同时前次写线程的修改对后续的读写线程可见。
接下来,我们看一下读锁的实现:
- 如果 writeState 不为0,并且持有该写锁的线程不是当前线程,则直接返回失败,否则尝试获得锁
- 如果先获得了写锁,再尝试获取读锁则不会发生死锁,这和前面的先获得读锁,再获得写锁不同,之所以这么设计可以参考文档: Additionally, a writer can acquire the read lock, but not vice-versa. Among other applications, reentrancy can be useful when write locks are held during calls or callbacks to methods that perform reads under read locks. If a reader tries to acquire the write lock it will never succeed.
- 接下来判断当前线程是否需要阻塞:
- 对于公平锁来说,只要队列中有前序节点则阻塞,因为只有读锁时,是不需要入队的,队列不为空,说明队列中存在或者存在过一个排它锁,这里直接入队等待
- 对于非公平锁来说,只要当前等待队列的第一个Waiter是排他锁,就阻塞,也就是下面的 apparentlyFirstQueuedIsExclusive 函数
- 如果不需要阻塞,则判断重入次数是否溢出,没溢出的话就通过 CAS 修改 state 的共享锁部分,即前16位,每次增加 1<<16
- 如果上述过程成功获得了锁,这里还有一道工序,就是保存当前线程的读锁持有数,本质上说通过一个 ThreadLocal 来保存这个读锁持有数即可,但是出于性能的考虑(ThreadLocal 性能不够好),这里另外增加了 firstReader 和 firstReaderHoldCount 来保存第一个获得读锁的线程重入数,此外还使用 cachedHoldCounter 来保存上一次调用时的线程的重入数,来达到加速的目的
- 当上述过程仍然没有获得锁时,进入 fullTryAcquireShared 逻辑
protected final int tryAcquireShared(int unused) {
/*
* Walkthrough:
* 1. If write lock held by another thread, fail.
* 2. Otherwise, this thread is eligible for
* lock wrt state, so ask if it should block
* because of queue policy. If not, try
* to grant by CASing state and updating count.
* Note that step does not check for reentrant
* acquires, which is postponed to full version
* to avoid having to check hold count in
* the more typical non-reentrant case.
* 3. If step 2 fails either because thread
* apparently not eligible or CAS fails or count
* saturated, chain to version with full retry loop.
*/
Thread current = Thread.currentThread();
int c = getState();
// 如果排它锁不为0,并且持有排它锁的线程不是当前线程,就返回
if (exclusiveCount(c) != 0 &&
getExclusiveOwnerThread() != current)
return -1;
int r = sharedCount(c);
// 根据是不是公平锁,做出阻塞决定,读锁数是否溢出,检查通过的话通过 cas 加锁
if (!readerShouldBlock() &&
r < MAX_COUNT &&
compareAndSetState(c, c + SHARED_UNIT)) {
if (r == 0) {
firstReader = current;
firstReaderHoldCount = 1;
} else if (firstReader == current) {
firstReaderHoldCount++;
} else {
HoldCounter rh = cachedHoldCounter;
if (rh == null || rh.tid != getThreadId(current))
cachedHoldCounter = rh = readHolds.get();
else if (rh.count == 0)
readHolds.set(rh);
rh.count++;
}
return 1;
}
return fullTryAcquireShared(current);
}
/**
* Returns {@code true} if the apparent first queued thread, if one
* exists, is waiting in exclusive mode. If this method returns
* {@code true}, and the current thread is attempting to acquire in
* shared mode (that is, this method is invoked from {@link
* #tryAcquireShared}) then it is guaranteed that the current thread
* is not the first queued thread. Used only as a heuristic in
* ReentrantReadWriteLock.
*/
final boolean apparentlyFirstQueuedIsExclusive() {
Node h, s;
return (h = head) != null &&
(s = h.next) != null &&
!s.isShared() &&
s.thread != null;
}
static final int SHARED_SHIFT = 16;
static final int SHARED_UNIT = (1 << SHARED_SHIFT);
static final class NonfairSync extends Sync {
final boolean readerShouldBlock() {
/* As a heuristic to avoid indefinite writer starvation,
* block if the thread that momentarily appears to be head
* of queue, if one exists, is a waiting writer. This is
* only a probabilistic effect since a new reader will not
* block if there is a waiting writer behind other enabled
* readers that have not yet drained from the queue.
*/
return apparentlyFirstQueuedIsExclusive();
}
}
/**
* Fair version of Sync
*/
static final class FairSync extends Sync {
final boolean readerShouldBlock() {
return hasQueuedPredecessors();
}
}fullTryAcquireShared 主要用来处理 tryAcquireShared 中需要阻塞等待,或者 CAS 失败或者重入次数溢出的问题:
- 整个 fullTryAcquireShared 就是一个循环 CAS 的过程
- 如果发现写锁被占用,并且持有写锁的的进程不是当前线程,则获取锁失败
- 然后检查是否需要阻塞(这里有一个额外的判断:如果当前线程是读锁重入,也不会进行阻塞):
- 对于公平锁来说,只要队列中有前序节点则阻塞(说明之前有人成功获取过写锁,获取正在获取写锁,才会出现队列)
- 对于非公平锁来说,只要当前等待队列的第一个Waiter是排他锁,就阻塞,也就是上述的 apparentlyFirstQueuedIsExclusive 函数,这里大家可能会有一个疑问:为什么只判断队列头不是写锁即可,如果等待队列是 Read->Read->Write 不就有问题了吗(读锁插队写锁), 确实会存在这个问题,apparentlyFirstQueuedIsExclusive 只能在一定程度上缓解读锁插队写锁的情况,因为并不是公平锁,所以没有必要完全保证读锁不能插队写锁
- 处理外阻塞逻辑后,判断重入数是否溢出,溢出则抛出异常
- 最后通过 CAS,进行 state 读锁段 + 1,修改成功的话,就维护当前线程的读锁持有数
/**
* Full version of acquire for reads, that handles CAS misses
* and reentrant reads not dealt with in tryAcquireShared.
*/
final int fullTryAcquireShared(Thread current) {
/*
* This code is in part redundant with that in
* tryAcquireShared but is simpler overall by not
* complicating tryAcquireShared with interactions between
* retries and lazily reading hold counts.
*/
HoldCounter rh = null;
for (;;) {
int c = getState();
// 如果排它锁不为0,并且持有排它锁的线程不是当前线程,就返回
if (exclusiveCount(c) != 0) {
if (getExclusiveOwnerThread() != current)
return -1;
// else we hold the exclusive lock; blocking here
// would cause deadlock.
} else if (readerShouldBlock()) {
// 如果当前线程获取过读锁,现在这次是读锁重入的话,就不进行阻塞,否则才会阻塞
// Make sure we're not acquiring read lock reentrantly
if (firstReader == current) {
// assert firstReaderHoldCount > 0;
} else {
if (rh == null) {
rh = cachedHoldCounter;
if (rh == null || rh.tid != getThreadId(current)) {
rh = readHolds.get();
if (rh.count == 0)
readHolds.remove();
}
}
if (rh.count == 0)
return -1;
}
}
// 读锁数是否溢出
if (sharedCount(c) == MAX_COUNT)
throw new Error("Maximum lock count exceeded");
if (compareAndSetState(c, c + SHARED_UNIT)) {
// 通过 cas 加锁, 然后维护读锁持有数
if (sharedCount(c) == 0) {
firstReader = current;
firstReaderHoldCount = 1;
} else if (firstReader == current) {
firstReaderHoldCount++;
} else {
if (rh == null)
rh = cachedHoldCounter;
if (rh == null || rh.tid != getThreadId(current))
rh = readHolds.get();
else if (rh.count == 0)
readHolds.set(rh);
rh.count++;
cachedHoldCounter = rh; // cache for release
}
return 1;
}
}
}看到这,大家一定有疑问,就是 Sync 的基类 AQS 到底是怎么实现的,我们在 AQS 之上基本上只是实现了 tryAcquire 接口,而且基本上都是通过 CAS 修改 state 来获取锁的,如果成功则返回true,如果失败则返回 false,那返回之后 AQS 根据返回值都会做出什么样的抉择呢?
参考内容
[1] linux 2.6 互斥锁的实现-源码分析
[2] 深入解析条件变量(condition variables)
[3] Linux下Condition Vairable和Mutext合用的小细节
[4] 从ReentrantLock的实现看AQS的原理及应用
[5] 不可不说的Java“锁”事
[6] 从源码层面解析yield、sleep、wait、park
[7] LockSupport中的park与unpark原理
[8] Thread.sleep、Object.wait、LockSupport.park 区别
[9] 从AQS到futex-二-JVM的Thread和Parker
[10] Java的LockSupport.park()实现分析
[11] JVM源码分析之Object.wait/notify实现
[12] Java线程源码解析之interrupt
[13] Thread.interrupt()相关源码分析
[14] Java CAS 原理剖析
[15] 源码解析 Java 的 compareAndSwapObject 到底比较的是什么
[16] 《Java并发编程的艺术》
[17] 《实战 Java 高并发程序设计》
[18] volatile关键字深入学习
[19] 为什么Netty的FastThreadLocal速度快
[20] 线程池ThreadPoolExecutor实现原理
[21] 深入理解Java线程池:ThreadPoolExecutor
[22] ConcurrentHashMap 详解一
[23] ConcurrentHashMap 详解二
[24] JUC中Atomic class之lazySet的一点疑惑
[25] The JSR-133 Cookbook for Compiler Writers
[26] 就是要你懂Java中volatile关键字实现原理
- 本文作者: 贝克街的流浪猫
- 本文链接:https://www.beikejiedeliulangmao.top/Java-%E5%B9%B6%E5%8F%91/
- 版权声明: 本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
- 创作声明: 本文基于上述所有参考内容进行创作,其中可能涉及复制、修改或者转换,图片均来自网络,如有侵权请联系我,我会第一时间进行删除。