Spark框架深度理解三:运行架构、核心数据集RDD
前言
由于Spark框架大多都搭建在Hadoop系统之上,要明白Spark核心运行原理还是得对Hadoop体系有个熟悉的认知。从Hadoop1.0到Hadoop2.0架构的优化和发展探索详解这篇博客大家可以先去温习一下Hadoop整个体系,然后再来了解Spark框架会更有效率。
本来想直接写一篇缘由优缺点以及生态圈和运行架构与原理的,发现篇幅实在是太长了,索性分两篇:
上篇:Spark框架深度理解一:开发缘由及优缺点
中篇:Spark框架深度理解二:生态圈
一、Spark集群架构
Spark的架构图:
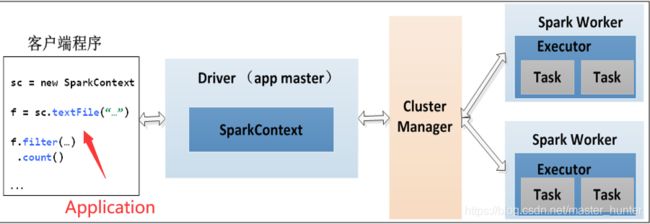
- Application:用户编写的Spark应用程序,包含一个Driver功能的代码和分布在集群中多个节点上的Executor代码。
- 客户端程序:用户提交作业的客户端
- Driver:运行Application的main函数并创建SparkContext。
- SparkContext:应用上下文,控制整个生命周期。负责与ClusterManager通信,进行资源申请、任务的分配和监控等,当Executor部分运行完毕后,Driver同时负责将SparkContext关闭。
- Cluter Manager:指的是在集群上获取资源的外部服务。目前有三种类型
1) Standalon : spark原生的资源管理,由Master负责资源的分配。也可以理解为使用Standalone是Spark原生的资源管理器。
2) Apache Mesos:与hadoop MR兼容性良好的一种资源调度框架
3) Hadoop Yarn: 主要是指Yarn中的ResourceManager
- Spark Worker:集群中任何可以运行Application的节点,运行一个或多个Executor进程
- Executor:是运行在工作节点(Spark Worker)的一个进程,负责运行Task。Executor启动线程池运行Task,兵器负责将数据存在内存或磁盘上,每个Application都会申请各自的Executor来处理任务。
- Task:运行在Executor上的工作单元。
- Job:一个Job包含多个RDD及作用于相应RDD上的各种操作。
- Stage:是Job的基本调度单位,一个Job会分为多组Task,每组Task被称为Stage,或者也被称为TaskSet,代表一组关联的,相互之间没有Shuffle依赖关系的任务组成的任务集。
- RDD:是Resilient distributed datasets的简称,中文为弹性分布式数据集;是Spark最核心的模块和类
- DAGScheduler:根据Job构建基于Stage的DAG,并提交Stage给TaskScheduler
一个Application由一个Driver和若干个Job构成,一个Job由多个Stage构成,一个Stage由多个没有Shuffle关系的Task组成。
当执行一个Application时,Driver会向集群管理器申请资源,启动Executor,并向Executor发送应用程序代码和文件,然后在Executor上执行Task,运行结束后,执行结果会返回给Driver,或者写到HDFS或者其它数据库中。
与Hadoop MapReduce计算框架相比,Spark所采用的Executor有两个优点:
- 利用多线程来执行具体的任务减少任务的启动开销;
- Executor中有一个BlockManager存储模块,会将内存和磁盘共同作为存储设备,有效减少IO开销;
一图流:
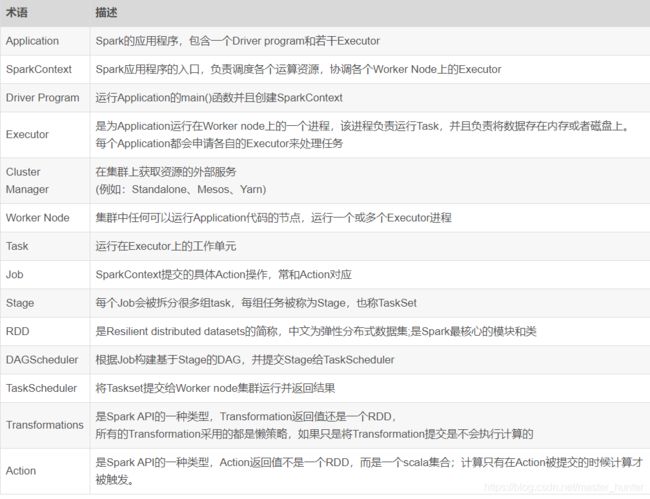
运行流程:
二、Spark运行模式
| 运行环境 |
模式 |
描述 |
| Local |
本地模式 |
常用于本地开发测试,本地还分为local单线程和local-cluster多线程; |
| Standalone |
集群模式 |
典型的Mater/slave模式,不过也能看出Master是有单点故障的;Spark支持 ZooKeeper来实现HA |
| On yarn |
集群模式 |
运行在yarn资源管理器框架之上,由yarn负责资源管理,Spark负责任务调度和计算 |
| On mesos |
集群模式 |
运行在mesos资源管理器框架之上,由mesos负责资源管理,Spark负责任务调度和计算 |
| On cloud |
集群模式 |
比如AWS的EC2,使用这个模式能很方便的访问Amazon的S3; Spark支持多种分布式存储系统:HDFS和S3 |
其中Mesos和YARN模式类似。目前用得比较多的是Standalone模式和YARN模式。
1.Standalone运行模式
Standalone模式是Spark实现的资源调度框架,其主要节点有Client节点、Master节点和Worker节点。Driver既可以运行在Master节点上,也可以运行在本地Client端。当用spark-shell交互式工具提交Spark的job时,Diver在Master节点上运行。当使用spark-submit工具提交Job或者在Eclipse、IDEA等开发平台上使用“new SparkConf().setMaster”方式运行Spark任务时,Diver是运行在本地Client端上的。

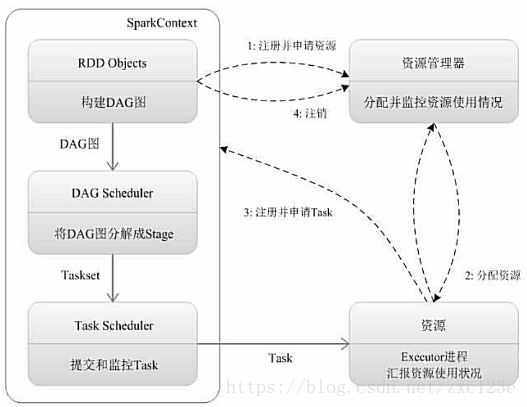
(1)首先,SparkContext连接到Master,向Master注册并申请资源
(2)Woker定期发送心跳信息给Master并报告Executor状态
(3)Master根据SparkContext的资源申请要求和Worker心跳周期内报告的信息决定在哪个Worker上分配资源,然后在该Worker上获取资源,启动StandloneExecutorBackend。
(4)StandloneExecutorBackend向SparkContext注册
(5)SparkContext将Application代码发送给StandloneExecutorBackend,并且SparkContext解析Application代码,构建DAG图,并提交给DAG Scheduler,分解成Stage(当碰到Action操作时,就会催生job,每个Job含有一个或多个Stage),然后将Stage(或者成为TaskSet)提交给Task Scheduler,Task Scheduler扶着将Task分配到相应的Worker,最后提交给StandloneExecutorBackend运行。
(6)StandExecutorBackend会建立Execytor线程池,开始执行Task,并向SparkContext报告,直至Task完成。
(7)所有Task完成后,SparkContext向Master注销,释放资源。
如果想深入了解可以去看底层编译scala代码,如StandaloneSchedulerBackend.start:
***
val appUIAddress = sc.ui.map(_.appUIAddress).getOrElse("")
val coresPerExecutor = conf.getOption("spark.executor.cores").map(_.toInt)
val initialExecutorLimit =
if (Utils.isDynamicAllocationEnabled(conf)) {
Some(0)
} else {
None
}
val appDesc = new ApplicationDescription(sc.appName, maxCores, sc.executorMemory, command,
appUIAddress, sc.eventLogDir, sc.eventLogCodec, coresPerExecutor, initialExecutorLimit)
//创建AppClient
client = new StandaloneAppClient(sc.env.rpcEnv, masters, appDesc, this, conf)
//启动AppClient
client.start()
***
本文就概括而言讲出运行原理。
2.Spark on Yarn
Spark on YARN模式根据Driver在集群中的位置分为两种模式,一种是YARN-Client模式(客户端模式),另一种是YARN-Cluster模式(集群模式)。
在YARN运行模式中,不需要启动Spark独立集群,所以这个时候去访问http://master:8080也是访问不了的。启动YARN客户端模式的Spark shell命令:
bin/spark-shell --master yarn-client
而打开cluster会报错:
bin/spark-shell --master yarn-cluster
原因在于这两种作业流程不同。
在集群模式下,Diver运行在Application Master上,Applocation Master进程同时负责驱动Application和从YARN中申请资源。该进程运行在YARN Container内,所以启动Application Master的Client可以立即关闭,而不必持续到Application的声明周期。
图YARN—Cluster模式运行流程:
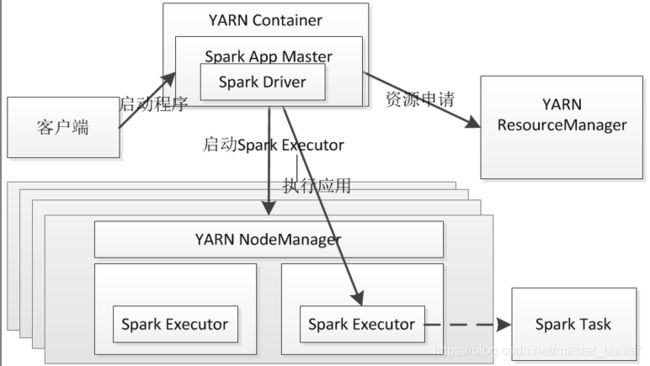
(1)客户端生成作业信息提交给ResourceManager。
(2)ResourceManager在某一个NodeManager(由YARN决定)启动Container,并将Application Master分配给该NodeManager。
(3)NodeManager接受到ResouceManager申请资源,ResouceManager分配资源的同时通知其他NodeManager启动相应的Executor。
(4)Application向ResourceManager上的Application Master注册汇报并完成相应的任务。
(5)Excutor向NodeManager上的Application Master主城汇报完成相应任务。
图YARN客户端模式的作业运行流程:

Application Master仅仅从YARN中申请资源给Excutor,之后Client会与Container通信进行作业的调度。
(1)客户端生成作业信息提交给ResouceManager。
(2)ResouceManager在本地NodeManager启动Container,并将Application Master分配给该NodeManager。
(3)NodeManager接收到ResourceManager的分配,启动Applicaton Master并开始初始化作业,此时这个NodeManager就称为Driver。
(4)Application向ResourceManager申请资源,ResourceManager分配资源同时通知其他NodeManager启动相应的Excutor。
(5)Executor向本地启动的Application Master注册汇报并完成相应的任务。
从两种模式下的作业运行流程来看。在YARN-Cluster模式下,SparkDriver运行在Application Master(AM)中,它扶着想YARN申请资源,并监督作业的运行状况,当用户提交了作业之后,就可以关掉Client,作业会继续在YARN上运行,所以YARN-Cluster模式不适合运行交互类型的作业。然而在YARN-Client模式下,AM仅仅向YARN请求Executor,Client会与请求得到的Container通信来调度它们的工作,也就是说Client不能离开。
总结起来就是,集群模式的Spark Driver运行在AM中,而客户端模式的Spark Diver运行在客户端。所以YARN-Cluster适用于生产,而YARN-Client适用于交互和调试,也就是希望快速看到应用输出信息。
三、Spark核心数据集
RDD(Resilient Distributed Datasets,弹性分布式数据集)是Spark中最重要的概念,可以简单的把RDD理解成一个提供了许多操作接口的数据集合,和一般数据集不同的是,其实际数据分布存储于一批机器中(内存或磁盘中),这里的分区可以简单地和Hadoop HDFS里面的文件来对比理解。
RDD何为弹性分布式数据集:
1、弹性之一:自动的进行内存和磁盘数据存储的切换;
2、弹性之二:基于Lineage的高效容错(第n个节点出错,会从第n-1个节点恢复,血统容错);
3、弹性之三:Task如果失败会自动进行特定次数的重试(默认4次);
4、弹性之四:Stage如果失败会自动进行特定次数的重试(可以只运行计算失败的阶段);只计算失败的数据分片;
5、checkpoint和persist
6、数据调度弹性:DAG TASK 和资源 管理无关
7、数据分片的高度弹性(人工自由设置分片函数),repartition
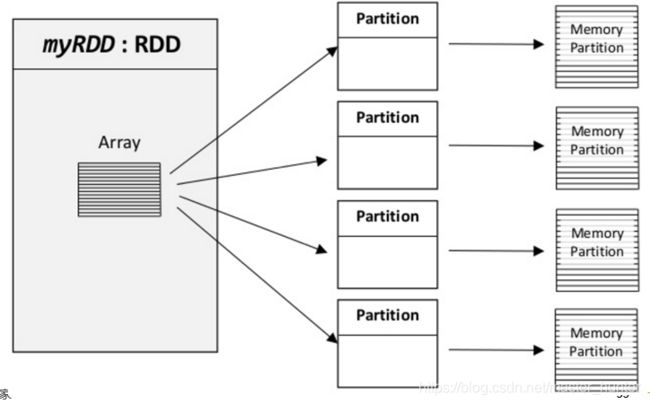
定义一个名为:“myRDD”的RDD数据集,这个数据集被切分成了多个分区,可能每个分区实际存储在不同的机器上,同时也可能存储在内存或硬盘上(HDFS)。
RDD 具有容错机制,并且只读不能修改,可以执行确定的转换操作创建新的 RDD。具体来讲,RDD 具有以下几个属性。
- 只读:不能修改,只能通过转换操作生成新的 RDD。
- 分布式:可以分布在多台机器上进行并行处理。
- 弹性:计算过程中内存不够时它会和磁盘进行数据交换。
- 基于内存:可以全部或部分缓存在内存中,在多次计算间重用。
RDD 实质上是一种更为通用的迭代并行计算框架,用户可以显示控制计算的中间结果,然后将其自由运用于之后的计算。
在大数据实际应用开发中存在许多迭代算法,如机器学习、图算法等,和交互式数据挖掘工具。这些应用场景的共同之处是在不同计算阶段之间会重用中间结果,即一个阶段的输出结果会作为下一个阶段的输入。
RDD 正是为了满足这种需求而设计的。虽然 MapReduce 具有自动容错、负载平衡和可拓展性的优点,但是其最大的缺点是采用非循环式的数据流模型,使得在迭代计算时要进行大量的磁盘 I/O 操作。
通过使用 RDD,用户不必担心底层数据的分布式特性,只需要将具体的应用逻辑表达为一系列转换处理,就可以实现管道化,从而避免了中间结果的存储,大大降低了数据复制、磁盘 I/O 和数据序列化的开销。
RDD 的操作分为转化(Transformation)操作和行动(Action)操作。转化操作就是从一个 RDD 产生一个新的 RDD,而行动操作就是进行实际的计算。
1. 构建操作
Spark 里的计算都是通过操作 RDD 完成的,学习 RDD 的第一个问题就是如何构建 RDD,构建 RDD 的方式从数据来源角度分为以下两类。
从内存里直接读取数据。
从文件系统里读取数据,文件系统的种类很多,常见的就是 HDFS 及本地文件系统。
第一类方式是从内存里构造 RDD,需要使用 makeRDD 方法,代码如下所示。
val rdd01 = sc.makeRDD(List(l,2,3,4,5,6))
这个语句创建了一个由“1,2,3,4,5,6”六个元素组成的 RDD。
第二类方式是通过文件系统构造 RDD,代码如下所示。
val rdd:RDD[String] == sc.textFile(“file:///D:/sparkdata.txt”,1)
这里例子使用的是本地文件系统,所以文件路径协议前缀是 file://。
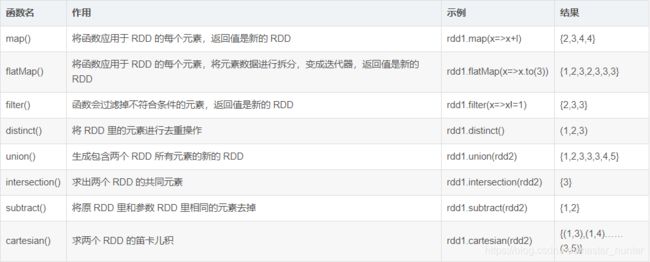
2. 转换操作
RDD 的转换操作是返回新的 RDD 的操作。转换出来的 RDD 是惰性求值的,只有在行动操作中用到这些 RDD 时才会被计算。
许多转换操作都是针对各个元素的,也就是说,这些转换操作每次只会操作 RDD 中的一个元素,不过并不是所有的转换操作都是这样的。
RDD转换操作(rdd1={1, 2, 3, 3},rdd2={3,4,5})
3. 行动操作
行动操作用于执行计算并按指定的方式输出结果。行动操作接受 RDD,但是返回非 RDD,即输出一个值或者结果。在 RDD 执行过程中,真正的计算发生在行动操作。表 2 描述了常用的 RDD 行动操作。
RDD 行动操作(rdd={1,2,3,3})

RDD 的操作是惰性的,当 RDD 执行转化操作的时候,实际计算并没有被执行,只有当 RDD 执行行动操作时才会促发计算任务提交,从而执行相应的计算操作。
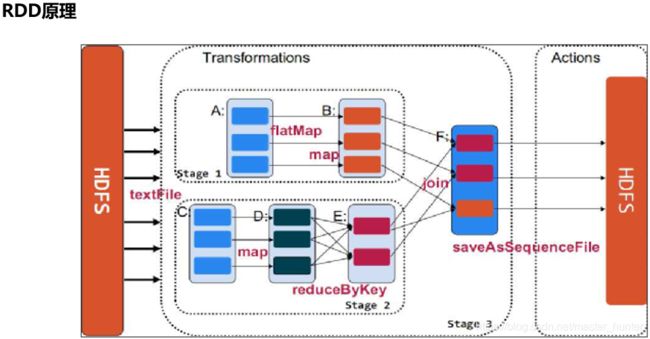
RDD的特点
- 它是集群节点上的不可改变的、已分区的集合对象;
- 通过并行转换的方式来创建如(map、filter、join等);
- 失败自动重建;
- 可以控制存储级别(内存、磁盘等)来进行重用;
- 必须是可序列化的;
- RDD只能从持久存储或通过Transformations操作产生,相比于分布式共享内存(DSM)可以更高效实现容错,对于丢失部分数据分区只需要根据它的lineage就可重新计算出来,而不需要做特定的checkpoint;
- RDD的数据分区特性,可以通过数据的本地性来提高性能,这与Hadoop MapReduce是一样的;
- RDD都是可序列化的,在内存不足时可自动降级为磁盘存储,把RDD存储于磁盘上,这时性能有大的下降但不会差于现在的MapReduce;
参阅:
Spark RDD是什么?
spark RDD 的弹性
一文搞定Spark的调度器的通信终端(SchedulerBackend)
深入理解Spark 2.1 Core (六):Standalone模式运行的原理与源码分析
计算机内存和磁盘的关系
spark的前世今生
Spark及其生态圈简介
Spark基本架构及运行原理