房地产数据-python爬虫+数据可视化
使用python3.7对链家网中广州二手房的交易数据进行爬取,并使用python-highcharts对爬取到的数据进行可视化分析。
首先,配置需要的环境:
打开终端cmd,进入pip所在的目录,安装python-highcharts库:
pip install python-highcharts对链家网进行数据爬虫,得到json格式的数据:
LianJia_by_json.py
from selenium import webdriver
from bs4 import BeautifulSoup
import re
import xlwt
import urllib
import json
import os
import time
class spider:
def __init__(self,driver):
self.driver = driver
self.chengjiao_info_dict = {}
self.href_list = []
self.classification_dict = {}
# self.data_json_file = 'LianJia_'+time.strftime("%Y_%m_%d_%H_%M_%S", time.localtime())+'.json'
# print(self.data_json_file)
# exit(0)
def spider(self):
ele_ershoufang = self.driver.find_element_by_link_text('二手房')
ele_ershoufang.click()
handles = self.driver.window_handles
self.driver.switch_to.window(handles[-1])
self.driver.find_element_by_link_text('成交').click()
# 获取总共的页数
soup = BeautifulSoup(self.driver.page_source, 'lxml')
# page_info_list = soup.find("div",class_="page-box house-lst-page-box").find_all("a")
page_info = soup.select("div.page-box.house-lst-page-box")[0].get("page-data") # 获取到一个字符串
total_page = (page_info.split(':')[1]).split(',')[0]
# print(total_page)
self.get_chengjiao_house_href(int(total_page))
self.get_chengjiao_base_info()
# 获取一页中所有成交房源的信息
def get_chengjiao_house_href(self,total_page):
# 循环获得每一页中成交房源的连接
for page in range(1,total_page+1):
url = 'https://gz.lianjia.com/chengjiao/pg'+str(page)
response = urllib.request.urlopen(url)
html = response.read().decode("utf-8")
# print(html)
soup = BeautifulSoup(html, 'lxml')
href_info_list = soup.find("ul", class_="listContent").find_all("li")
# 在多次请求网页信息过程中,有时会出现返回的响应中房源信息为0条的情况,所以需要多次重复请求
while len(href_info_list)==0:
response = urllib.request.urlopen(url)
html = response.read().decode("utf-8")
# print(html)
soup = BeautifulSoup(html, 'lxml')
href_info_list = soup.find("ul", class_="listContent").find_all("li")
print(len(href_info_list))
for li in href_info_list:
# print(li)
pattern = re.compile('')
m = pattern.findall(str(li))[0]
href = m.split('"')[1]
self.href_list.append(href)
# break
print('第',page,'页:链接列表长度',len(self.href_list))
# sleep(2)
# break
def get_chengjiao_base_info(self):
# 循环操作,直到得到所有房源的信息
columns = 1
self.chengjiao_info_dict = {}
for url in self.href_list:
info_dict = {}
# 获取到当前房源的信息
response = urllib.request.urlopen(url)
html = response.read().decode("utf-8")
soup = BeautifulSoup(html,'lxml')
# 得到小区名
housing_name_info = (soup.find_all('div',class_='wrapper')[0]).get_text()
housing_name = housing_name_info.split(' ')[0]
# print(housing_name)
info_dict['小区名']=housing_name
price = (((soup.find_all('div',class_='info fr')[0]).find_all('div',class_='price')[0]).find_all('b')[0]).get_text()
print(price)
info_dict['单价:元/平'] = price
info_dict['总价:万'] = ((soup.find_all('span',class_='dealTotalPrice')[0]).find_all('i')[0]).get_text()
info_dict['成交日期'] = ((soup.find_all('div',class_='wrapper')[0]).find_all('span')[0]).get_text().split(' ')[0]
# print(info_dict['成/交日期'])
agent = (soup.find_all('div',class_="myAgent")[0]).find_all('a')
info_dict['所属区域'] = (agent[0]).get_text()+(agent[1]).get_text()
print(info_dict['所属区域'])
# self.key_list.append('小区名')
# self.chengjiao_info_dict['房源链接'] = url
# self.key_list.append('小区名')
base_info_list = soup.find('div',class_='content').find('ul').find_all('li')
# base_info_list = soup.fina('div',class_='content')
for info in base_info_list:
# print(info)
patten_title = re.compile('.*?"label">(.*?).*? ', re.S)
pattern_content = re.compile('.*?(.*?) ',re.S)
# 在sublime中直接传入info没有报错,而在这里却需要转为字符串,否则报错?????
key = (patten_title.findall(str(info))[0]).strip()
# self.key_list.append(key)
value = (pattern_content.findall(str(info))[0]).strip()
info_dict[key] = value
# print(info_dict)
self.chengjiao_info_dict[url] = info_dict
# print(self.chengjiao_info_dict)
# 显示当前进度
print(len(self.href_list),':',columns)
# sleep(2)
self.write_house_info()
# 开始分类统计
# self.get_classification_dict()
columns += 1
# break
# self.write_classification()
# for key in self.info_dict.keys():
# self.key_list.append(key)
def write_house_info(self):
with open("LianJia_data_json_file",'w',encoding='utf-8') as fp:
json.dump(self.chengjiao_info_dict,fp,ensure_ascii=False)
if __name__ == "__main__":
url = 'https://gz.lianjia.com/'
driver = webdriver.Chrome()
driver.maximize_window()
driver.get(url)
sp = spider(driver)
sp.spider() 得到的json格式的数据LianJia_data_json_file.json的部分截图如下:
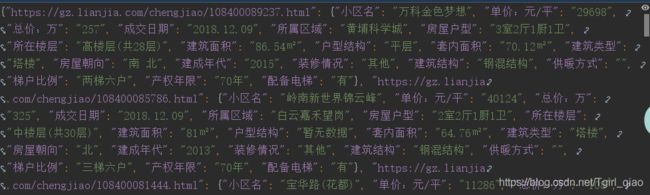
将获取到的json格式的数据转换为Excel格式,以便阅读:
LianJia_json_deal.py
import json
import xlwt
# 设置表头
def set_excel_title(LianJia_data_dict,LianJia_data_all):
LianJia_data_all.write(0,0,'href')
raw = 1
for k in (list(LianJia_data_dict.values())[0]).keys():
LianJia_data_all.write(0, raw, k)
print (k)
raw += 1
def set_excel_content(LianJia_data_dict,LianJia_data_all):
column = 1
for href in LianJia_data_dict:
LianJia_data_all.write(column, 0, href)
raw = 1
for value in (LianJia_data_dict[href]).values():
LianJia_data_all.write(column, raw, value)
raw += 1
column += 1
def get_data_excel():
with open('LianJia_data_json_file.json', 'r', encoding='utf-8') as fp:
LianJia_data_dict = json.load(fp)
wb = xlwt.Workbook(encoding='ascii')
LianJia_data_all = wb.add_sheet('LianJia_data_all')
set_excel_title(LianJia_data_dict,LianJia_data_all)
set_excel_content(LianJia_data_dict,LianJia_data_all)
wb.save('LianJia_data.xls')
if __name__ =="__main__":
get_data_excel()得到的excel表格LinaJia_data.xls的部分截图如下:

将得到的json数据进行分类统计,为数据可视化做准备:
LianJia_select.py
import json
import time
with open('LianJia_2019_01_08_12_42_25.json', 'r', encoding='utf-8') as fp:
LianJia_data_dict = json.load(fp)
select_dict={}
# sub_key为每个房源的每一项信息的关键子,如:户型结构、所属区域等
for sub_key in (list(LianJia_data_dict.values()))[0]:
# print(sub_key)
select_sub_dict = {}
for href in LianJia_data_dict:
# print(LianJia_data_dict[href][sub_key])
if LianJia_data_dict[href][sub_key] in select_sub_dict:
select_sub_dict[LianJia_data_dict[href][sub_key]] += 1
else:
select_sub_dict[LianJia_data_dict[href][sub_key]] = 1
select_dict[sub_key] = select_sub_dict
print(sub_key,':',select_dict[sub_key])
# print(select_dict)
with open('LianJia_select_data_file.json', 'w', encoding='utf-8') as fp:
json.dump(select_dict,fp,ensure_ascii=False)获得的分类后的json数据的分布截图取下:

所有的数据准备好后,就开始对数据进行可视化操作。
在python-highcharts库中,不同的可视化图形所需要的数据格式是不完全相同的,这里,针对自己所接触到的情况,总结如下:
饼状图pie:
data=[
{
'name':data name,
'y':data values,
'sliced': True, 需要突出显示的部分
'selected': True
},{
'name':data name,
'y':data values
},
……
]
没有x轴的配置。
折线图line/曲线图spline/柱形图column/面积图area:
data = [1,2,3,4,5,6,7,8,9,0]
categories = [] # 横坐标中每个数据的名称
配置X轴坐标:
options={
'xAxis': {'type': categories}, #以获取到的categories列表中的元素作为x轴的坐标
}
柱形图下钻column_drilldown:该图可以在每项大的分类中进行更进一步的分类统计
第一层数据: # 即大的分类的数据
data = [{
'name': "Chrome",
'y': 24.030000000000005, # 数据为该项的百分比
'drilldown': "Chrome"
},
……,
{
'name': "Proprietary or Undetectable",
'y': 0.2,
'drilldown': None #该项目不设置下钻
}]
第二层数据: # 大分类项的分类统计的数据
data_sub = [
["v11.0", 24.13],
["v8.0", 17.2],
["v9.0", 8.11],
["v10.0", 5.33],
["v6.0", 1.06],
["v7.0", 0.5]
]
配置X轴坐标:
options={
'xAxis': {'type': 'category'}, #这个是固定的
}开始进行数据可视化操作:
LianJia_hc.py
import json
from highcharts import Highchart
def get_data_dict(word):
with open('LianJia_select_data_2019_01_08_15_47_59.json', 'r', encoding='utf-8') as fp:
LianJia_select_data_dict = json.load(fp)
data_dict = LianJia_select_data_dict[word]
return data_dict
def get_chart(word):
data_dict = get_data_dict(word)
print(data_dict)
data = list(data_dict.values())
categories = list(data_dict.keys())
print(data)
print(len(data))
print(categories)
text = '链家二手'+word+'统计'
options = {
'title':{'text':text},
'xAxis': {'categories': categories},
'plotOptions': {
'series': {
'dataLabels': {
'enabled': True, #显示出数据点的数值
'shadow': True, #数据标签边框有阴影
'backgroundColor': 'rgba(252, 255, 197, 0.7)' #设置数据点标签的背景色
# 'borderRadius': 10, # 圆角,默认是0,lable是方的,这里10已经比较园了
# 'borderWidth': 20, #这个是啥????
# 'padding': 5, #这个也不晓得是啥
# 'style': {'fontWeight': 'bold'},
}
}
}
}
H.set_dict_options(options)
# 绘制面积图
# H.add_data_set(data,'area')
# H.save_file(word.split(':')[0] + '_area')
# 绘制柱形图
H.add_data_set(data, 'bar')
H.save_file(word.split(':')[0]+'_bar')
# 绘制折线图
# H.add_data_set(data, 'line')
# H.save_file(word.split(':')[0] + '_line')
# 绘制曲线图
# H.add_data_set(data, 'spline')
# H.save_file(word.split(':')[0] + '_spline')
# def get_heatmap_chart():
if __name__ == "__main__":
# H = Highchart(width=950, height=600)
H = Highchart()
# get_chart('建筑结构')
get_chart('房屋户型')
# get_chart('房屋朝向')
# get_chart('成交日期')
# get_chart('单价:元/平')
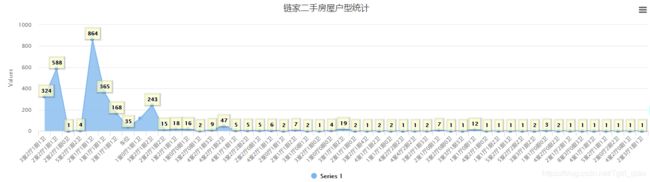
# get_chart('所属区域')在该程序总,可以绘制出数据的不同可视化图形,这里对房屋户型的折线图,曲线图,面积图及柱形图进行展示:



对二手房是否配备电梯进行饼状图可视化分析:
LianJia_hc_pie.py
import json
from highcharts import Highchart
def get_data_dict(word):
with open('LianJia_select_data_2019_01_08_15_47_59.json', 'r', encoding='utf-8') as fp:
LianJia_select_data_dict = json.load(fp)
data_dict = LianJia_select_data_dict[word]
return data_dict
def get_chart(word):
data_dict = get_data_dict(word)
# data = list(data_dict.values())
# categories = list(data_dict.keys())
data=[]
for key in data_dict:
data_list = []
data_list.append(key)
data_list.append(data_dict[key])
data.append(data_list)
text = '链家二手'+word+'统计'
options = {
'title':{'text':text},
'plotOptions': {
'series': {
'allowPointSelect': True,
'dataLabels': {
'enabled': True, #显示出数据点的数值
'shadow': True, #数据标签边框有阴影
'backgroundColor': 'rgba(252, 255, 197, 0.7)' #设置数据点标签的背景色
# 'borderRadius': 10, # 圆角,默认是0,lable是方的,这里10已经比较园了
# 'borderWidth': 20, #这个是啥????
# 'padding': 5, #这个也不晓得是啥
# 'style': {'fontWeight': 'bold'},
}
}
}
}
H.set_dict_options(options)
H.add_data_set(data, 'pie')
H.save_file(word.split(':')[0]+'_pie')
if __name__ == "__main__":
# H = Highchart(width=950, height=600)
H = Highchart()
get_chart('配备电梯')
# get_chart('房屋户型')
# get_chart('成交日期')
# get_chart('单价:元/平')
# get_chart('所属区域') 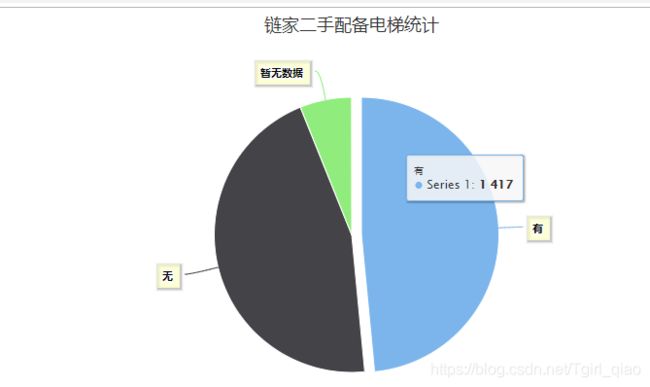
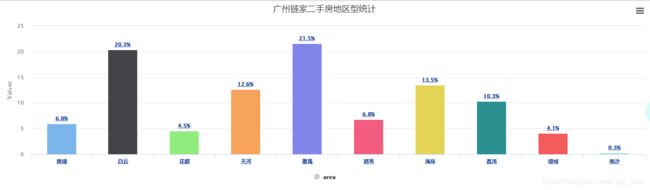
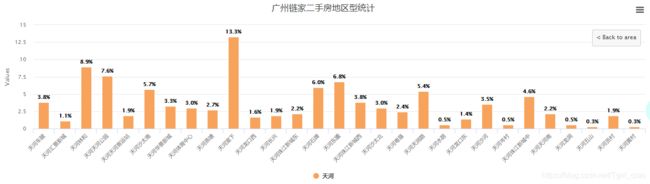
链家二手房所属区域进行下钻分析:
Lianjia_hc_column_dirlldown.py
import json
from highcharts import Highchart
'''
对链家二手房成交房所属区域进行下钻分析
'''
def get_data_dict():
with open('LianJia_select_data_2019_01_08_15_47_59.json', 'r', encoding='utf-8') as fp:
LianJia_select_data_dict = json.load(fp)
area_sub_dict = LianJia_select_data_dict['所属区域']
# area_dict为广州各个区的二手房统计情况
area_dict = {}
# area_sub_class_dict为各个区下属区域二手房统计情况
area_sub_class_dict = {}
for area_sub in area_sub_dict:
area = area_sub[:2]
# area_sub_class_dict[area] = []
area_sub_temp = []
if area in area_dict:
area_dict[area] += int(area_sub_dict[area_sub])
area_sub_temp.append(area_sub)
area_sub_temp.append(area_sub_dict[area_sub])
# area_sub_class_dict[area][area_sub] = area_sub_dict[area_sub]
area_sub_class_dict[area].append(area_sub_temp)
else:
area_dict[area] = int(area_sub_dict[area_sub])
area_sub_class_dict[area] = []
area_sub_temp.append(area_sub)
area_sub_temp.append(area_sub_dict[area_sub])
area_sub_class_dict[area].append(area_sub_temp)
get_chart(area_dict, area_sub_class_dict)
def get_chart(area_dict,area_sub_class_dict):
data = []
sum = 0
for value in area_dict.values():
sum += int(value)
# print(sum)
for area in area_dict:
dict = {}
dict['name'] = area
dict['y'] = ((int(area_dict[area]))/sum)*100
dict['drilldown'] = area
data.append(dict)
# print(data)
options = {
'title':{'text':'广州链家二手房地区型统计'},
'xAxis': {'type': 'category'},
'plotOptions': {
'series': {
'dataLabels': {
'enabled': True, #显示出数据点的数值
'shadow': True, #数据标签边框有阴影
'format': '{point.y:.1f}%',
# 'backgroundColor': 'rgba(252, 255, 197, 0.7)' #设置数据点标签的背景色
# 'borderRadius': 10, # 圆角,默认是0,lable是方的,这里10已经比较园了
# 'borderWidth': 20, #这个是啥????
# 'padding': 5, #这个也不晓得是啥
# 'style': {'fontWeight': 'bold'},
}
}
}
}
H.set_dict_options(options)
H.add_data_set(data, 'column', "area", colorByPoint=True)
for area in area_sub_class_dict:
data_sub = area_sub_class_dict[area]
for value in data_sub:
value[1] = (value[1]/int(area_dict[area]))*100
# print(data_sub)
H.add_drilldown_data_set(data_sub, 'column', area, name=area)
H.save_file('所属区域_column_drilldown')
if __name__ == "__main__":
# H = Highchart(width=950, height=600)
H = Highchart()
get_data_dict()大分类的数据可视化结果:
大类中进一步分析的可视化结果:
如白云区和天河区

在操作的过程中还存在一些待解决的问题:
1.在开始的时候,遇到一个charts库,也是python中highcharts的一个库,但用起来比较摸不着头脑,还不清楚他们的关系。
2.关于这些可视化图形的细节配置还有待进一步研究,目前只能粗略实现。
3.在代码的编写过程中,对文件的处理还不能达到理想的效果,如:在下一次运行程序生成文件的时候需要手动删除已有的文件。