python爬虫--爬取网易云音乐评论
方1:使用selenium模块,简单粗暴。但是虽然方便但是缺点也是很明显,运行慢等等等。
方2:常规思路:直接去请求服务器
1.简易看出评论是动态加载的,一定是ajax方式。
2.通过网络抓包,可以找出评论请求的的URL
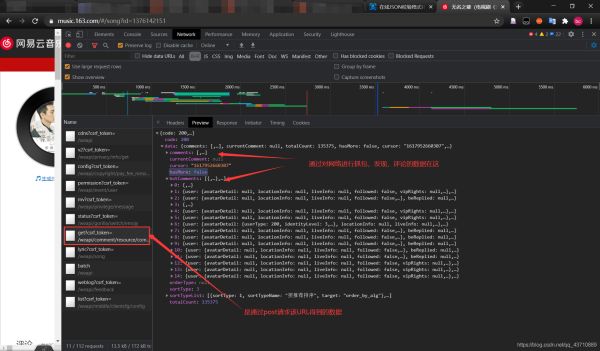
得到请求的URL

3.去查看post请求所上传的数据
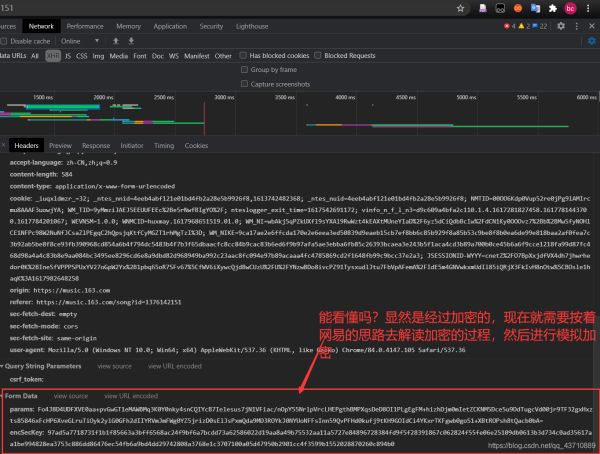
显然是经过加密的,现在就需要按着网易的思路去解读加密过程,然后进行模拟加密。
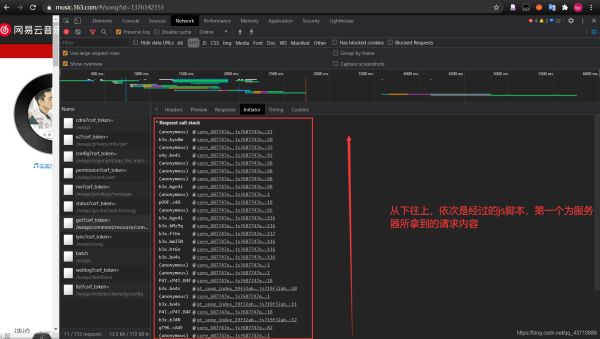
4.首先去查看请求是经过那些js到达服务器的
5.设置断点:依次对所发送的内容进行观察,找到评论对应的URL
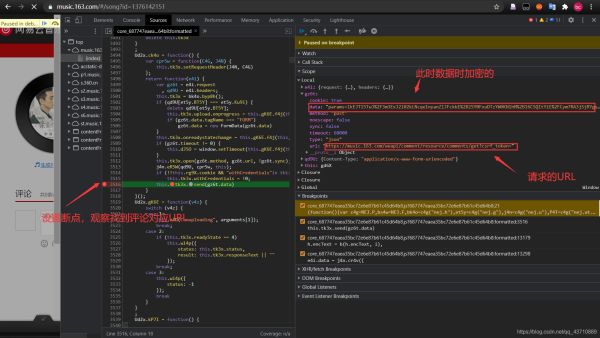
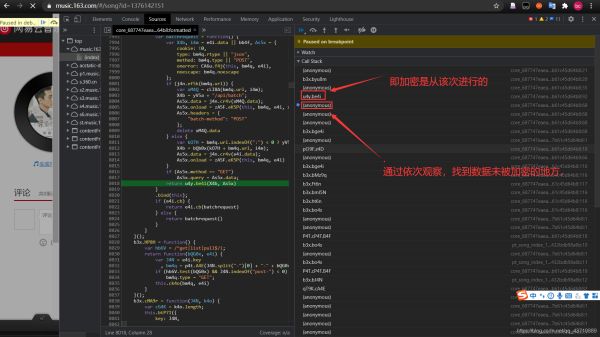
6.查找加密函数
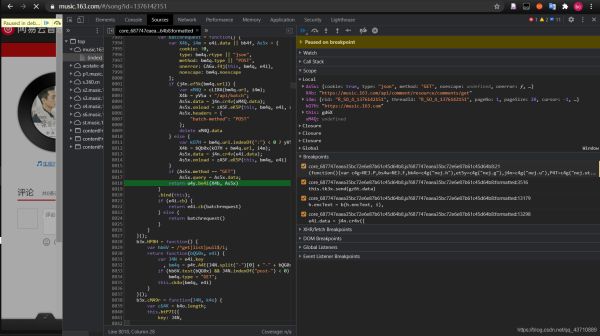
(忽略查找过程)找到:加密函数在
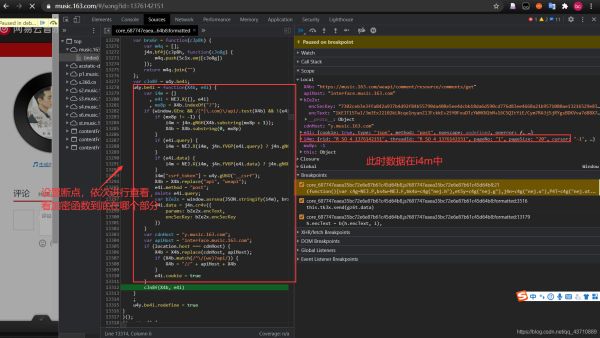
通过查找,找到加密函数具体位置:
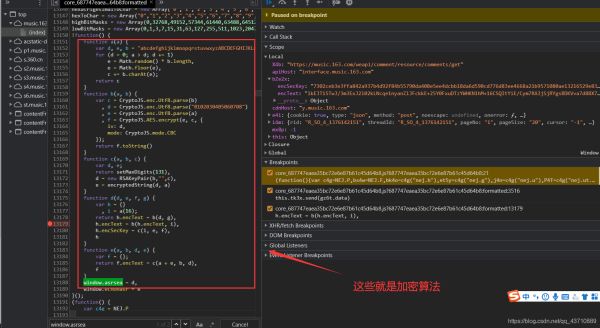
7.解读加密函数
运用的是AES,模式是:CBC
function a(a) { a=16
var d, e, b = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789", c = "";
for (d = 0; a > d; d += 1)
e = Math.random() * b.length, #生成随机数
e = Math.floor(e), #取整
c += b.charAt(e); #取出b中对应位置的字符
return c
}
function b(a, b) {
var c = CryptoJS.enc.Utf8.parse(b)
, d = CryptoJS.enc.Utf8.parse("0102030405060708")
, e = CryptoJS.enc.Utf8.parse(a) #e是数据
, f = CryptoJS.AES.encrypt(e, c, { #c就是加密密钥
iv: d, #iv是偏移量
mode: CryptoJS.mode.CBC # 模式:CBC加密
});
return f.toString()
}
function c(a, b, c) {
var d, e;
return setMaxDigits(131),
d = new RSAKeyPair(b,"",c),
e = encryptedString(d, a)
}
function d(d, e, f, g) { d:数据json串 e:"010001" f: g = "0CoJUm6Qyw8W8jud"
var h = {}
, i = a(16); #16位随机值
return h.encText = b(d, g), g是密钥
h.encText = b(h.encText, i), #返回的就是params i是密钥
h.encSecKey = c(i, e, f), #返回的是encSecKey e和f定死,能产生变数的只能是i
h
function e(a, b, d, e) {
var f = {};
return f.encText = c(a + e, b, d),
f
}
window.asrsea = d
解读该过程即可:代码有注释。
8.参数如何获得:
function d(d, e, f, g) { d:数据json串 e:"010001" f: g = "0CoJUm6Qyw8W8jud"
var bZe2x = window.asrsea(JSON.stringify(i4m), brx6r(["流泪", "强"]), brx6r(Sc1x.md), brx6r(["爱心", "女孩", "惊恐", "大笑"]));
#使用网页控制台:发现都为定值;
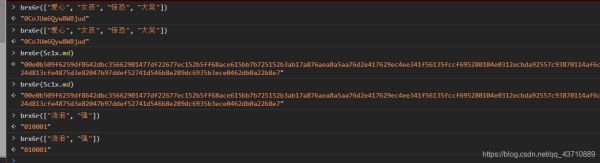
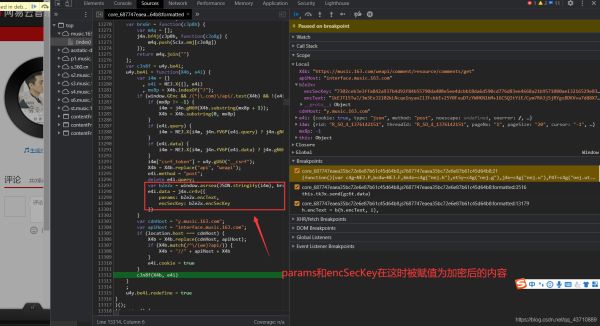
9.这时只需找到某一个i以及它对应的encSecKey 即可完成服务器的验证
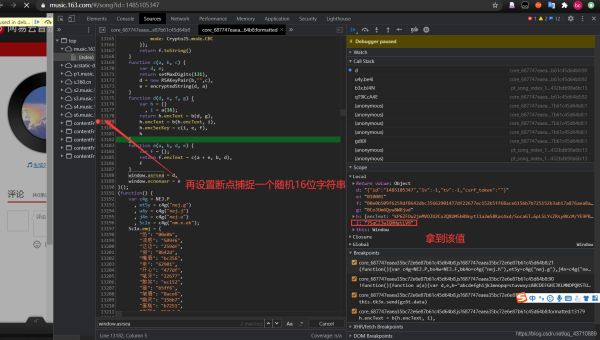
拿到该值之后开始编写代码
全部代码粘贴
#1.找到未加密的参数 #通过函数window.asrsea()进行加密
#2.想办法把参数进行加密,params--->encText encSecKey--->encSecKey
from Cryptodome.Cipher import AES
from base64 import b64encode
import requests,json
e = "010001"
f = "00e0b509f6259df8642dbc35662901477df22677ec152b5ff68ace615bb7b725152b3ab17a876aea8a5aa76d2e417629ec4ee341f56135fccf695280104e0312ecbda92557c93870114af6c9d05c4f7f0c3685b7a46bee255932575cce10b424d813cfe4875d3e82047b97ddef52741d546b8e289dc6935b3ece0462db0a22b8e7"
g = "0CoJUm6Qyw8W8jud"
i = "0hyFaCNAVzOIdoht"
url = 'https://music.163.com/weapi/comment/resource/comments/get?csrf_token='
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36'
}
def get_encSecKey():
return "4022359ea3110bcd034e0160c3b89e5e172fd0110a3cf765d9f366d9fd09840a1f4a4705ac43719fdb8bfeb44d3b92334733061ad10942131184a4dfba0ac9d2cf867b8b6236523c1ca5f44c0d2d82c1c2665a3137a9241c7373539c1aa8e5e9bb9d33dafc764b5d76c2ab34fc94df85e27a934c8a603fa713f2cf38c2b7bbae"
def get_params(data): #data默认是json字符串
first = enc_params(data,g)
second = enc_params(first,i)
return second
def to_16(data):
pad = 16-len(data)%16
data +=chr(pad) * pad
return data
def enc_params(data,key): #加密过程
iv = "0102030405060708"
data = to_16(data)
aes = AES.new(key=key.encode('utf-8'),IV=iv.encode('utf-8'),mode=AES.MODE_CBC) #创建加密器
bs = aes.encrypt(data.encode('utf-8')) #加密
return str(b64encode(bs),"utf-8") #转化成字符串
#处理加密过程
'''
function a(a) { a=16
var d, e, b = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789", c = "";
for (d = 0; a > d; d += 1)
e = Math.random() * b.length, #生成随机数
e = Math.floor(e), #取整
c += b.charAt(e); #取出b中对应位置的字符
return c
}
function b(a, b) {
var c = CryptoJS.enc.Utf8.parse(b)
, d = CryptoJS.enc.Utf8.parse("0102030405060708")
, e = CryptoJS.enc.Utf8.parse(a) #e是数据
, f = CryptoJS.AES.encrypt(e, c, { #c就是加密密钥
iv: d, #iv是偏移量
mode: CryptoJS.mode.CBC # 模式:CBC加密
});
return f.toString()
}
function c(a, b, c) {
var d, e;
return setMaxDigits(131),
d = new RSAKeyPair(b,"",c),
e = encryptedString(d, a)
}
function d(d, e, f, g) { d:数据json串 e:"010001" f: g = "0CoJUm6Qyw8W8jud"
var h = {}
, i = a(16); #16位随机值
return h.encText = b(d, g), g是密钥
h.encText = b(h.encText, i), #返回的就是params i是密钥
h.encSecKey = c(i, e, f), #返回的是encSecKey e和f定死,能产生变数的只能是i
h
}'''
if __name__ == '__main__':
page = int(input('请输入需要爬取的页数:'))
print('开始爬虫!!!')
fp = open('./网易云评论.txt', 'w', encoding='utf-8')
for j in range(1,page+1):
page_num = str(j*20)
data = {
'csrf_token': "",
'cursor': "-1",
'offset': "0",
'orderType': "1",
'pageNo': "1",
'pageSize': page_num,
'rid': "R_SO_4_1376142151",
'threadId': "R_SO_4_1376142151"
}
response = requests.post(url,data={
"params":get_params(json.dumps(data)),
"encSecKey":get_encSecKey()
},headers=headers)
result = json.loads(response.content.decode('utf-8'))
#hotComments
for hot in range(len(result['data']['hotComments'])):
fp.write('hotComments' + ' ')
fp.write('昵称:' + result['data']['hotComments'][hot]['user']['nickname'] + '\n')
fp.write('评论:' + result['data']['hotComments'][hot]['content'] + '\n')
if result['data']['hotComments'][hot]['user']['vipRights'] == None:
fp.write('vip:yes' + '\n')
else:
fp.write('vip:no' + '\n')
fp.write('点赞数' + str(result['data']['hotComments'][hot]['likedCount']) + '\n')
fp.write('-------------------------------------' + '\n')
#print(result['data']['hotComments'][1]['user']['nickname'])
#comments
for r in range(20):
fp.write('comments')
fp.write('昵称:'+result['data']['comments'][r]['user']['nickname']+'\n')
fp.write('评论:'+result['data']['comments'][r]['content']+'\n')
if result['data']['comments'][r]['user']['vipRights'] == None:
fp.write('vip:yes'+'\n')
else:
fp.write('vip:no'+'\n')
fp.write('点赞数'+str(result['data']['comments'][r]['likedCount'])+'\n')
fp.write('-------------------------------------'+'\n')
print('爬取完毕!!!')
效果图
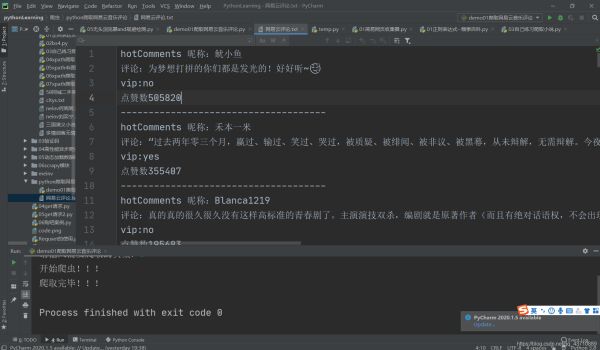
通过这次爬虫实验,在爬取的过程中,遇到各种困难,收货很多。掌握遇到加密,该如何处理的步骤,以及拓宽自己的思路,去运用各种工具。以及各种自己想不到的思路。最起码,下次遇到如此加密的数据获取,心里有了一些底气。
也了解了大互联网公司对数据进行加密的一种方式,以及网页运作的更深一步的了解,受益颇多。
到此这篇关于如何用Python网络爬虫爬取网易云音乐评论的文章就介绍到这了,更多相关python爬取网易云音乐评论内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!