python 数据分析 实际案例_python数据分析练习-电商交易案例

源代码以及所需资料都在里面的,欢迎交流~
链接:https://pan.baidu.com/s/175edfNAUGcJ7lBrAMt6QAg
提取码:ya51
#加载数据需要使用到的库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
#加载数据,加载之前用文本编辑器看下数据的格式,首行是什么,分隔符是什么等
data = pd.read_csv(r'D:竺明网络学习资料数据分析学习课件5-python0831-0903pandas+numpy实战order_info_2016.csv',index_col='id')
data.head()
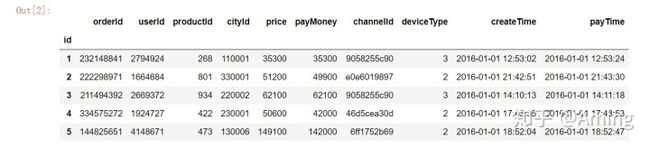
#加载好数据之后,第一部先分别使用describe和info方法看下数据的大概分布
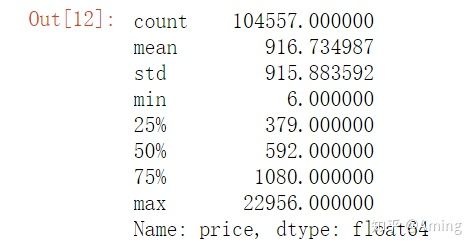
data.describe()

data.info()

#首先要做一个数据的清洗
#order_id
#因为是订单id所以不可能会有一样的订单号
#先看下order_id有没有重复值
#注意:当我们对一列取size属性的时候,返回的是行数,如果对于dataframe使用size,返回的是行乘以列的结果,也就是总的元素数
data.orderId.unique().size
#对比上面我们不难看出原本数量是104557现在是104530,说明有重复
#但是目前先不处理重复列,最后再处理,因为其他的列可能会影响到删除哪条重复的济记录
#所以先处理其他的列
data.head()
#userId
#userId我们只要从上面的describe和info看下值在不在正常范围就可以了
#对于用户订单数据,一个用户有可能有多个订单,重复值是合理的
data.userId.unique().size
#有重复且合理
#productId
# productId最小值为0,这本身就有问题,我们可以先看下0有多少
data.productId[(data.productId == 0)].size
#共有177条记录,数量不多,可能是因为商品的上架下架引起的,处理完其他值的时候我们把这些删掉
#上述小结:遇到异常值先不要着急处理先查看完全部之后有了大局观后在做判断
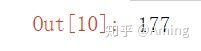
#cityId
#cityId类似于userId,值都在正常范围内,不需要处理
data.cityId.unique().size
#price
#price没有空值,且都大于0,但是自已看你会发现数值都过大,而且最后两位数都是00由此我们可以判断,该数值用的最小单位是分,因为不可能最便宜的都要600元
data.price = data.price/100
data.price.describe()
#这样一来就合理了
#payMoney
#payMoney 有负值,我们下单不可能是负值,所以这里对负值的记录要删除掉
# 展示负值的记录
data[(data.payMoney < 0 )]
# #删除负值的记录
data.drop(index=data[(data.payMoney < 0 )].index,inplace= True)
#这下在看下,发现就没有了
data[(data.payMoney < 0 )].index
#和上面一样将单位转化成元
data.payMoney = data.payMoney/100
data.head()

#channelId
#channelId根据info,可以看出他是有缺失值的,造成这种缺失值,能有可能是因为端的bug等原因造成下单后无法显示channelId字段
#数据量大的时候,删除少量的null记录是不会影响到统计结果,这里我们直接删除(因为只有8条空值数据,不多的)
#展示
data.drop(index=data[(data.channelId.isnull())].index,inplace=True)
data.info()
#以防万一可以确认一下
data[(data.channelId.isnull())].index

#deviceType的值可以看device_type.txt文件
device_type = pd.read_csv(r'D:竺明网络学习资料数据分析学习课件5-python0831-0903pandas+numpy实战device_type.txt',index_col='id')
device_type

#createTime和payTime都没有null,不过我们需要统计2016年的数据,所以把非2016年的删掉
#payTime类似,这里只按创建订单的时间,就不处理了
#先把createTime和payTime转化成datetime格式
data.createTime = pd.to_datetime(data.createTime)
data.payTime = pd.to_datetime(data.payTime)
data.info()
data.dtypes

import datetime
startTime = datetime.datetime(2016,1,1)
endTime = datetime.datetime(2016,12,31,23,59,59)
#有16年之前的数据,需要删除
data[data.createTime < startTime]
data.drop(index = data[data.createTime < startTime].index,inplace = True)
#处理16年之后的数据,将其删除
data[data.createTime > endTime]
data.drop(index = data[data.createTime > endTime].index,inplace = True)
#查看payTime中有没有早与createTime的,如果有也需要删除,因为这是不合理的
data[data.createTime > data.payTime]
#将这些不合理的数据删掉
data.drop(index = data[data.createTime > data.payTime].index,inplace = True)
data[data.createTime > data.payTime]

#回过头来将orderId的重复记录删除
data[data.orderId.duplicated()]
data.drop(index = data[data.orderId.duplicated()].index,inplace = True)
data[data.orderId.duplicated()]
#再将productId中的0删除
data.drop(index=data[data.productId ==0].index,inplace=True)
#数据清理完毕,可以开始分析了
#一般都是先看下数据的总体情况
#总订单数,总下单用户数,总销售额,有流水的产品数
data.describe()

#总订单数
print(data.orderId.count())
#总下单用户数
print(data.userId.unique().size)
#总销售额
print(data.payMoney.sum())
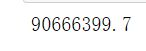
#有流水的产品数?
print(data.productId.unique().size)
#分析数据可以从两方面开始考虑,一个是维度,一个是指标,维度可以看做x轴,指标可以看成是y轴,同一个维度可以分析多个指标,同一个维度也可以做降维,升维.
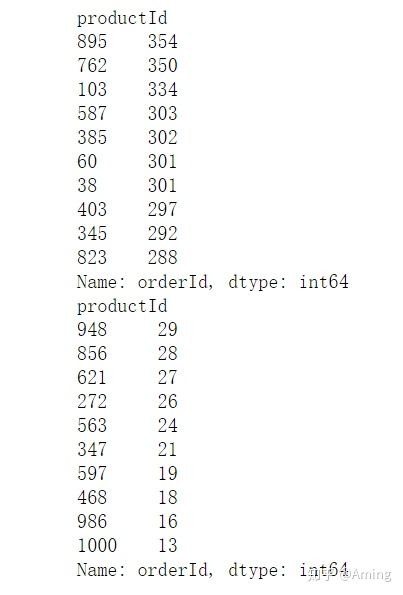
#先看下产品销量的前十个和后十个(卖的最好的,和卖的最不好的)
productId_ordercount = data.groupby('productId').count()['orderId'].sort_values(ascending = False)
print(productId_ordercount.head(10))
print(productId_ordercount.tail(10))
#对应销售额
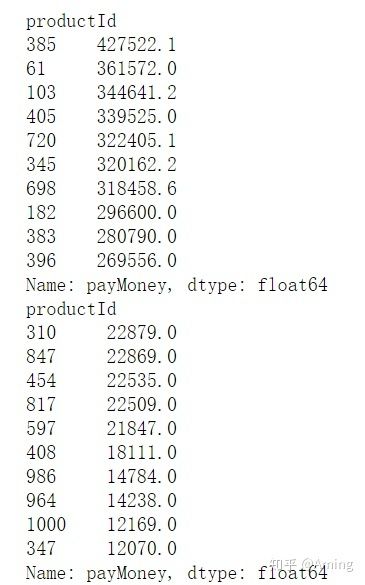
productId_turnover = data.groupby('productId').sum()['payMoney'].sort_values(ascending = False)
print(productId_turnover.head(10))
print(productId_turnover.tail(10))
#城市的分析可以和商品类似
#按照上面的维度可以看一下那个销量和销售额卖的最好和最差的10个
#销售量
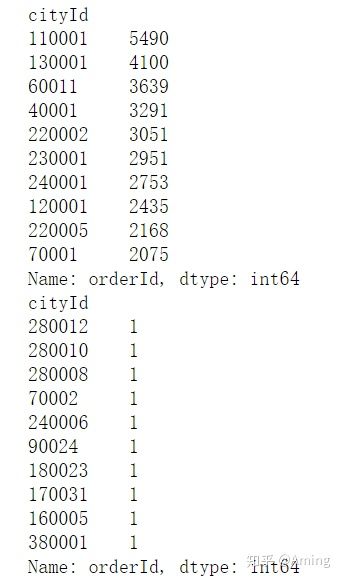
cityId_ordercount = data.groupby('cityId').count()['orderId'].sort_values(ascending = False)
print(cityId_ordercount.head(10))
print(cityId_ordercount.tail(10))
#销售额
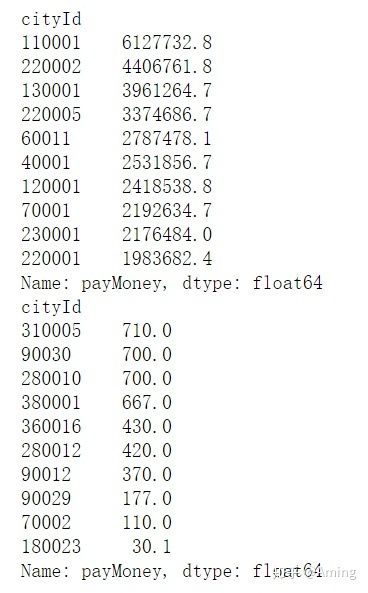
cityId_turnover = data.groupby('cityId').sum()['payMoney'].sort_values(ascending = False)
print(cityId_turnover.head(10))
print(cityId_turnover.tail(10))
#price
#对于价格,可以看下所有商品价格的分布,这样可以知道什么价格的商品卖的最好
#先按照100的区间去分桶
bins = np.arange(0,25000,100)
pd.cut(data.price,bins).sort_values(ascending = False)

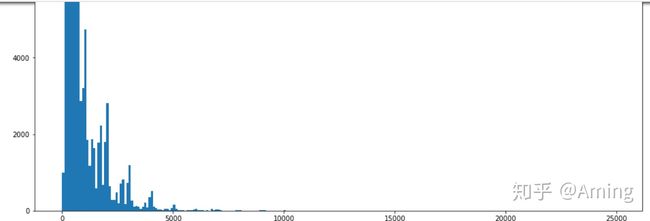
#直方图
#觉得尺寸小的话可以先设置下figsize,觉得后面的值没有必要展示,可以不用2500,改成10000:
plt.figure(figsize=(16,16))
plt.hist(data['price'],bins)
#很多价格区间中是没有商品的,如果有竞争对手的数据,可以看看是否需要补商品填充对应的价格区间
#这里将之前切好的桶进行分组计数使用value_counts()来完成
price_cut_count = pd.cut(data.price,bins).value_counts()
print(price_cut_count)

#这里括号判断,我个人理解非常像简写的if语句,它会将符合条件的值转成true,反之false
price_cut_result = (price_cut_count == 0 )
#利用上一步做好的变量,用.values的特性(取出所有为true的值)在用.index取出所有是true(为0)的索引
price_cut_result[price_cut_result.values].index
#这里就可以就可以非常详细的显示有哪些里面没有任何商品的

#之前按照100来密度太高,我们试着使用1000分桶看下
bins = np.arange(0,5000,1000)
price_cut = pd.cut(data.price,bins).value_counts()
#看看1000分桶的时候5000以下的饼图
m = plt.pie(x =price_cut.values,labels= price_cut.index, autopct = '%d%%', shadow = True)
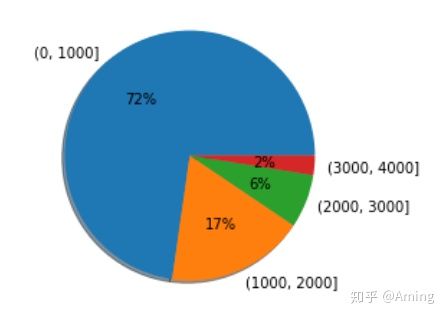
#channelId
''''渠道的分析类似与productId,可以给出成交量最多的渠道,订单数最多的渠道等,渠道很多的时候是需要需要花钱买流量的,
所以还需要根据渠道的盈利情况和渠道成本进行综合比较,同时也可以和商品等多个维度综合分析,看看不同的卖的最好的商品是否相同.'''
#好吧我承认这边的跨表查询暂时不会,先放放
#下单时间分析
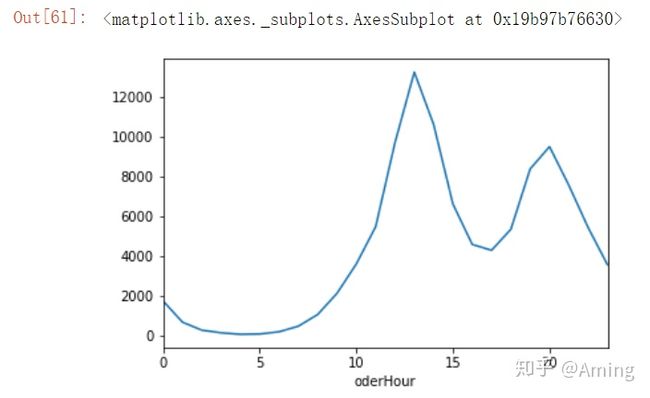
#按小时的下单量分布,可以按时间做推广,这样可以提到享受量
#中午12,13,14点下单比较多,应该是午休的时候,然后是晚上20点左右,晚上20点左右几乎是所有互联网产品的高峰,下单高峰要注意网站的稳定性,和可用性
#先新建一个oderHour,使用.dt.hour将createTime中的小时提取出来
data['oderHour'] = data.createTime.dt.hour
#使用groupby将oderHour分组,数据保留orderId,这样我们可以从数据的角度看到那个时间段的下单人数最多
data.groupby('oderHour').count()['orderId'].sort_values(ascending = False)
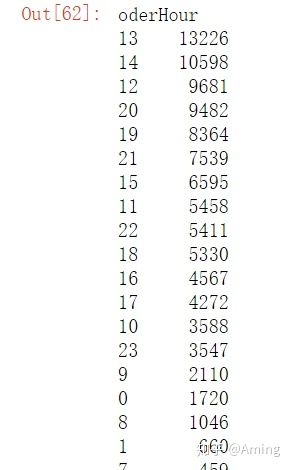
#也可以直接用.plot()函数将其转变成一个折线图,更加直观
data.groupby('oderHour').count()['orderId'].plot()