yolov3训练人脸数据库widerface
1.安装darknet
git 源码
git https://github.com/AlexeyAB/darknet.git详细安装项目里面已经写得非常清楚,支持Win Linux
具体操作指南见https://pjreddie.com/darknet/yolo/
2.下载widerface
可以自行百度,也可以下载百度云:链接:https://pan.baidu.com/s/1Qh6Jnv3uVHnziiFMD4y4yA 密码:e36e
3.生成VOC格式数据
widerface数据集有自带标注好的人脸框,我们需要做的就是将其生成VOC格式的labels,其他信息都没用到。
这里假设已经根据darknet官网实际操作了一遍训练voc,此时的位置为darknet根目录下:
![]()
cd VOCdevkit/脚本如下:
'''
face_labels.py
'''
import os,cv2
import numpy as np
from os import listdir, getcwd
rootdir="./wider_face" #widerface数据集所在目录
convet2yoloformat=True
resized_dim=(48, 48)
minsize2select=20#widerface中有大量小人脸,只取20以上的来训练
usepadding=True
datasetprefix="./darknet/VOCdevkit/VOC2007"
def convertimgset(img_set="train"):
imgdir=rootdir+"/WIDER_"+img_set+"/images"
gtfilepath=rootdir+"/wider_face_split/wider_face_"+img_set+"_bbx_gt.txt"
imagesdir=datasetprefix+"/JPEGImages"
vocannotationdir=rootdir+"/Annotations"
labelsdir=datasetprefix+"/labels"
if not os.path.exists(imagesdir):
os.mkdir(imagesdir)
if convet2yoloformat:
if not os.path.exists(labelsdir):
os.mkdir(labelsdir)
if convert2vocformat:
if not os.path.exists(vocannotationdir):
os.mkdir(vocannotationdir)
index=0
img_f=open(rootdir+"/"+img_set+".txt","w")
with open(gtfilepath,'r') as gtfile:
while(True ):#and len(faces)<10
filename=gtfile.readline()[:-1]
print filename
if(filename==""):
break;
#sys.stdout.write("\r"+str(index)+":"+filename+"\t\t\t")
#sys.stdout.flush()
imgpath=imgdir+"/"+filename
img=cv2.imread(imgpath)
if not img.data:
break;
imgheight=img.shape[0]
imgwidth=img.shape[1]
maxl=max(imgheight,imgwidth)
paddingleft=(maxl-imgwidth)>>1
paddingright=(maxl-imgwidth)>>1
paddingbottom=(maxl-imgheight)>>1
paddingtop=(maxl-imgheight)>>1
saveimg=cv2.copyMakeBorder(img,paddingtop,paddingbottom,paddingleft,paddingright,cv2.BORDER_CONSTANT,value=0)
showimg=saveimg.copy()
numbbox=int(gtfile.readline())
bboxes=[]
for i in range(numbbox):
line=gtfile.readline()
line=line.split()
line=line[0:4]
if(int(line[3])<=0 or int(line[2])<=0):
continue
x=int(line[0])+paddingleft
y=int(line[1])+paddingtop
width=int(line[2])
height=int(line[3])
bbox=(x,y,width,height)
x2=x+width
y2=y+height
#face=img[x:x2,y:y2]
if width>=minsize2select and height>=minsize2select:
bboxes.append(bbox)
cv2.rectangle(showimg,(x,y),(x2,y2),(0,255,0))
#maxl=max(width,height)
#x3=(int)(x+(width-maxl)*0.5)
#y3=(int)(y+(height-maxl)*0.5)
#x4=(int)(x3+maxl)
#y4=(int)(y3+maxl)
#cv2.rectangle(img,(x3,y3),(x4,y4),(255,0,0))
else:
cv2.rectangle(showimg,(x,y),(x2,y2),(0,0,255))
filename=filename.replace("/","_")
if convet2yoloformat:
height=saveimg.shape[0]
width=saveimg.shape[1]
txtpath=labelsdir+"/"+filename
txtpath=txtpath[:-3]+"txt"
ftxt=open(txtpath,'w')
for i in range(len(bboxes)):
bbox=bboxes[i]
xcenter=(bbox[0]+bbox[2]*0.5)/width
ycenter=(bbox[1]+bbox[3]*0.5)/height
wr=bbox[2]*1.0/width
hr=bbox[3]*1.0/height
txtline="0 "+str(xcenter)+" "+str(ycenter)+" "+str(wr)+" "+str(hr)+"\n"
ftxt.write(txtline)
ftxt.close()
index=index+1
img_f.close()
def convertdataset():
img_sets=["train","val"]
for img_set in img_sets:
convertimgset(img_set)
if __name__=="__main__":
convertdataset()PS::改脚本也是通过一篇博客修改的(忘记是那篇博客了,如有侵权联系删除),保证所有txt里面都有相对应的原图存下来。
python face_labels.py最终会生成VOC格式数据,这里只得到训练的图片以及标签,图片放在VOC2007/JPEGIMAGES/下,标签在labels下。train.txt 以及val.txt在widerface数据集下。我move到了darknet跟目录下。
4.修改配置文件
一共有三个文件需要修改。
1)data/face.names
2)cfg/face.data
3)cfg/yolov3-face.cfg
这三个文件都是由对应的voc文件copy而来。修改后结果如下:

我们只训练人脸,所以face.name里面就一类face.
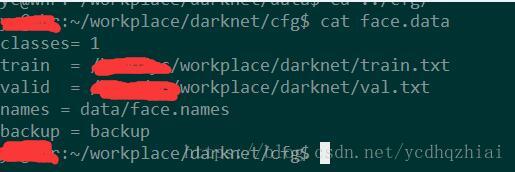
face.data里面填上对应的txt路径以及face.names路径就行。类别数量为1
最后是yolo3-face.cfg
1 [net]
2 # Testing
3 # batch=1
4 # subdivisions=1
5 # Training
6 batch= 64
7 subdivisions=16
8 width=416
9 height=416
10 channels=3
11 momentum=0.9
12 decay=0.0005
13 angle=0
14 saturation = 1.5
15 exposure = 1.5
16 hue=.1
17
18 learning_rate=0.001
19 burn_in=1000
20 max_batches = 100000 # 感谢mxj大神
21 policy=steps
22 steps=1,100,60000,80000
23 scales=.1,10,.1,.1
601 [convolutional]
602 size=1
603 stride=1
604 pad=1
605 filters=18 # filters = 3*(classes + 5),这里face是一类,所以是18
606 activation=linear
607
608 [yolo]
609 mask = 6,7,8
610 anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
611 classes=1 # 一类face
612 num=9
613 jitter=.3
614 ignore_thresh = .5
615 truth_thresh = 1
616 random=1
685 [convolutional]
686 size=1
687 stride=1
688 pad=1
689 filters=18
690 activation=linear
691
692 [yolo]
693 mask = 3,4,5
694 anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
695 classes=1
696 num=9
697 jitter=.3
698 ignore_thresh = .5
699 truth_thresh = 1
700 random=1
769 [convolutional]
770 size=1
771 stride=1
772 pad=1
773 filters=18
774 activation=linear
775
776 [yolo]
777 mask = 0,1,2
778 anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
779 classes=1
780 num=9
781 jitter=.3
782 ignore_thresh = .5
783 truth_thresh = 1
784 random=1
需要修改的地方都已经标红,最左侧为行号。
5训练
根据darknet官网操作指导,输入脚本
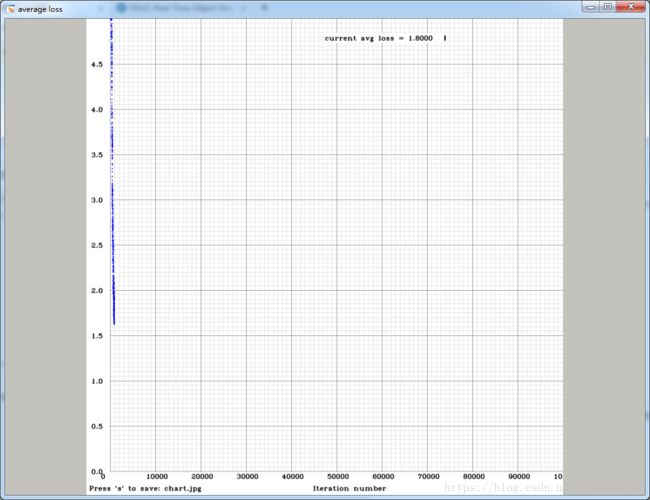
./darknet detector train cfg/face.data cfg/yolov3-face.cfg darknet53.conv.74万事大吉,慢慢等吧,贴一张刚刚训练的loss.
6测试
编写测试脚本,很简单安装官网上来就ok
./darknet detector test ./cfg/face.data ./cfg/yolov3-face.cfg ./backup/yolov3-face_16100.weights data/3.jpg附两张测试结果


这里是16100次之后的结果。