相关源码
搭建scrapy的开发环境,本文介绍scrapy的常用命令以及工程目录结构分析,本文中也会详细的讲解xpath和css选择器的使用。然后通过scrapy提供的spider完成所有文章的爬取。然后详细讲解item以及item loader方式完成具体字段的提取后使用scrapy提供的pipeline分别将数据保存到json文件以及mysql数据库中.
首先爬取一个网站前,我们需要分析网络的url结构,伯乐在线的网站结构是采用顶级域名下有二级域名,来区分每种类别的信息,并且在文章专栏里面
有一个
- http://web.jobbole.com/all-posts/

是所有文章的总链接
-
在这个链接下,分页显示了所有的文章内容

因此对于这种爬取内容有一个总链接的话,就不需要采用深度优先或者广度优先策略,只需要将这个总链接下的每一页的内容取出即可.
说到每一页,查看url特点,发现就是在链接后面修改了页数,但是不能用这个方法,因为网站上文章数发生变化时,就必须要去修改源码。
如果是对每个分页上的写一页的链接进行跟踪,那么有多少页都无所谓了.
1 scrapy安装以及目录结构介绍

1.1 安装并创建 scrapy 项目
1.1.1 创建一个虚拟环境 article_spider

-
注意版本 3.5+

1.1.2 在这个虚拟环境内安装scrapy:
pip install -i https://pypi.douban.com/simple/ scrapy

注意安装的时候可能会报错,twisted找不到,那么就去https://www.lfd.uci.edu/~gohlke/pythonlibs/下载安装包,手动安装,安装的时候必须也是在这个虚拟环境内
1.1.3 建立scrapy项目
-
PyCharm里面没有提供建立scrapy的项目
需要在命令行内手动创建项目

1.1.4 在pycharm中打开刚创建的项目

1.2 目录结构介绍
- scrapy.cfg: 类似于django的配置,它大量的借鉴了django的设计理念
- settings.py: 包含了很多scrapy的配置,工程名字,spider_modules也指明了存放spiders的路径
- pipelines.py: 做跟数据存储相关的
- middlewares.py: 可以存放自己定义的middlewares,让scrapy变得更加可控
- items.py: 有点类似于django里面的form,定义数据保存的格式
- spiders文件夹:里面存放具体某个网站的爬虫,scrapy会在该文件夹里面找有多少个爬虫文件,只需要在这里面继承了spiders,就会被scrapy找到
1.3 初步爬取
刚创建好项目的时候这个文件夹是空的,默认并没有创建网站爬取的模板,但是提供了命令
scrapy genspider example example.com
example是spider的名称,后面是网站的域名
这里使用了scrapy提供的basic模板

为了创建一个Spider,必须继承 scrapy.Spider类, 且定义以下三个属性:
-
name: 用于区别Spider
该名字必须是唯一的,您不可以为不同的Spider设定相同的名字。 -
start_urls: 包含了Spider在启动时进行爬取的url列表
因此,第一个被获取到的页面将是其中之一。 后续的URL则从初始的URL获取到的数据中提取。 -
parse(): 是spider的一个方法
被调用时,每个初始URL完成下载后生成的Response对象将会作为唯一的参数传递给该函数。 该方法负责解析返回的数据(response data),提取数据(生成item)以及生成需要进一步处理的URL的Request对象。
2 PyCharm 调试scrapy 执行流程
2.1 注意Python解释器版本
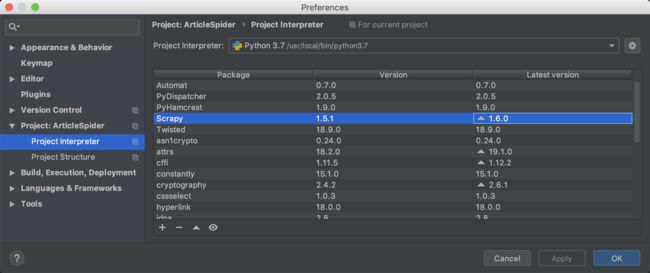
2.2 让scrapy在PyCharm中可调试
-
设置断点

PyCharm 中没有关于scrapy的模板,无法直接调试,需要我们自己手动编写一个main文件
设置工程目录,这样execute命令才会生效,找到该目录;
同时为了避免因环境问题无法找到该目录,使用os相关库调用
-
验证一下

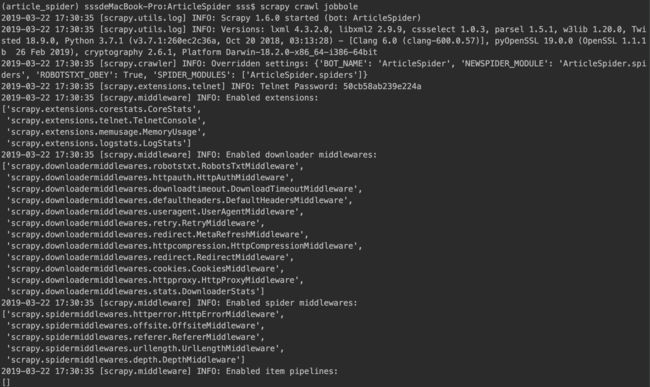
爬取
进入项目的根目录,执行下列命令启动spider
scrapy crawl xxx

于是,考虑将该命令配置到我们的main文件中
-
调用execute()函数来执行spider命令,传入数组,即是执行启动spider的命令
-
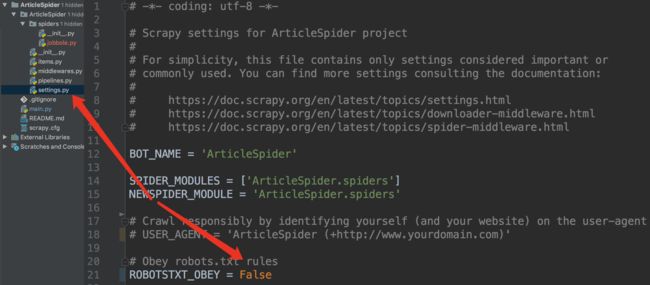
注意设置为
False
-
开始
debug运行main文件
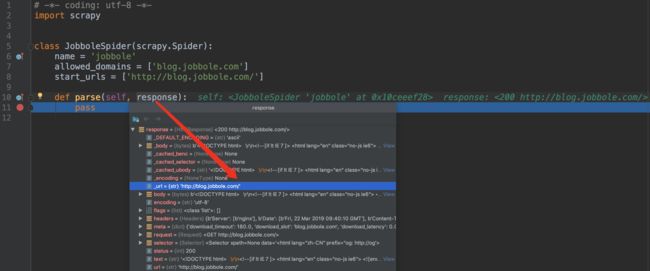
-
所爬取源文件的内容
下一步就是对其中的内容进行解析,获取想要爬取的字段内容!
3 xpath的用法
3.1 简介
- xpath使用路径表达式在xml和html文件中进行导航
- xpath包含标准函数库
- xpath是一个w3c的标准
3.2 xpath节点关系
html中被尖括号包起来的被称为一个节点
父节点 上一层节点
子节点 下一层节点
兄弟节点 同胞节点
先辈节点 父节节点,爷爷节点 ...
后代节点 儿子节点,孙子节点 ...
3.3 xpath的语法

xpath 谓语
其他语法

- 如果想通过属性取值则需要给定标签元素的内容,如果是任意标签则给定*
- 如果通过@class="class类"取值,则只会匹配class只有指定的元素;如果想指定包含指定class的元素则需要使用函数contains(@class,"class类")
3.4 准备爬取标题
欲爬取以下标题

先看看源码,获取其xpath
可以看到,我们的标题标题在 html/body/div[1]/div[3]/div[1]/div[1]/h1 这个嵌套关系下
我们在用xpath解析的时候,不需要自己一个一个地看嵌套关系
在F12下,在某个元素上面右键即copy->copy xpath就能获得该元素的xpath路径
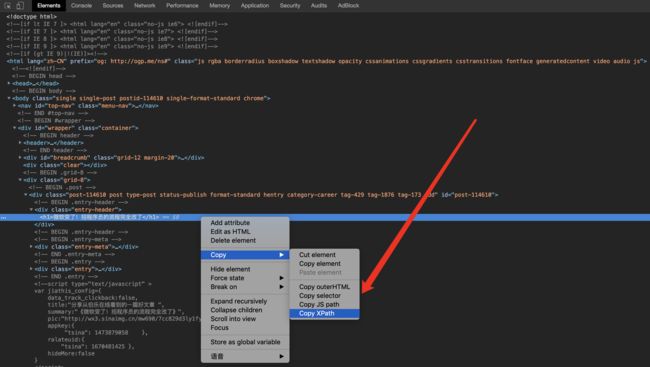
在Firefox和chrom浏览器中右键copy xpath得到的结果可能不一样
在Firefox中,得到的路径是/html/body/div[1]/div[3]/div[1]/div[1]/h1
在chrom中,得到的是//*[@id="post-110287"]/div[1]/h1
可以发现两种路径不一样,经过测试,第一种路径不能获得标题,第二种可以,原因在于,一般元素检查看到的是动态的返回来的html信息,比如js生成的,然后有些节点可能是在后台返回信息时才创建的,对于静态的网页就是检查源代码,定位的结果可能不一样,采用第二种id确定的方式更容易标准的定位。
- -*- coding: utf-8 -*-
import scrapy
class JobboleSpider(scrapy.Spider):
name = 'jobbole'
allowed_domains = ['blog.jobbole.com']
start_urls = ['http://blog.jobbole.com/114610/'] #放入想爬取的url
def parse(self, response):
#/html/body/div[3]/div[3]/div[1]/div[1] # Firefox
#//*[@id="post-114610"]/div[1]/h1 # Chrome
#scrapy返回的是一个selector而不是node,是为了方便进一步获取selector下面的selector
re_selector = response.xpath('//*[@id="post-114610"]/div[1]/h1')
re2_selector = response.xpath('//*[@id="post-114610"]/div[1]/h1/text()') #利用text()函数获取元素中的值
pass
-
爬取

页面上的查看源码跟检查控制台的element不一定一样,源码是源代码的html文件,控制台的element会有js动态生成的dom!!!
-
下面将源代码拷贝进项目来研究

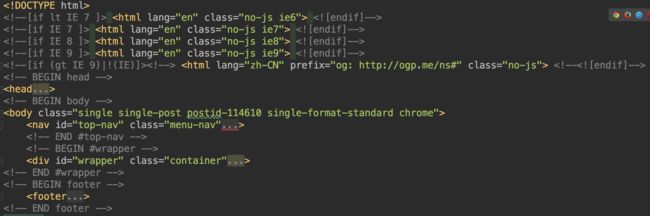
-
所以更改之后,也可正常爬取所需字段了!
3.5 准备爬取class
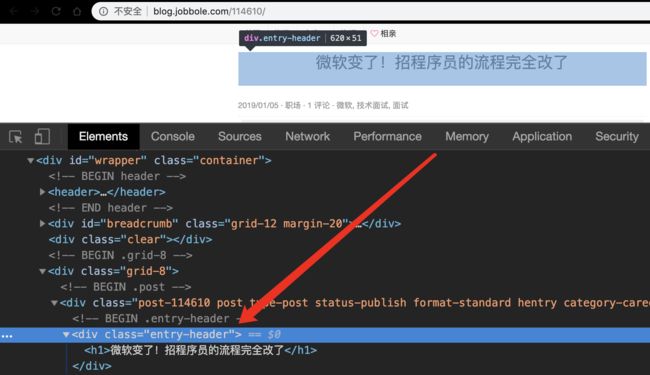
-
可看出该写法更加短小简洁高效!不易出错!

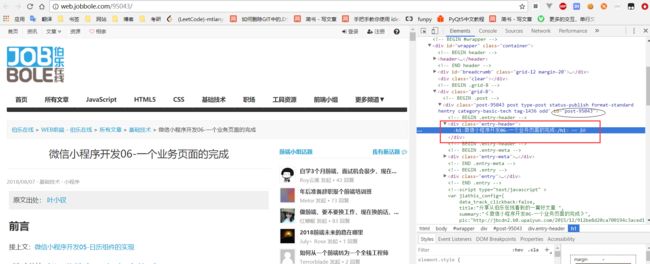
错误提示:
同一个页面的元素通过不同电脑的chrom浏览器进行源代码查看,标签结点信息发现不一样,在h1标签中多了个span标签,解决方法:清除浏览器缓存,以下是同一页面用一个内容的检查元素的对比图。
图1:未清除浏览器缓存前

图2:清除浏览器缓存后
3.6 shell命令调试
每一次调试都运行python脚本发送HTTP请求获取内容效率低下!
scrapy提供了一种shell模式,提高了调试的效率.
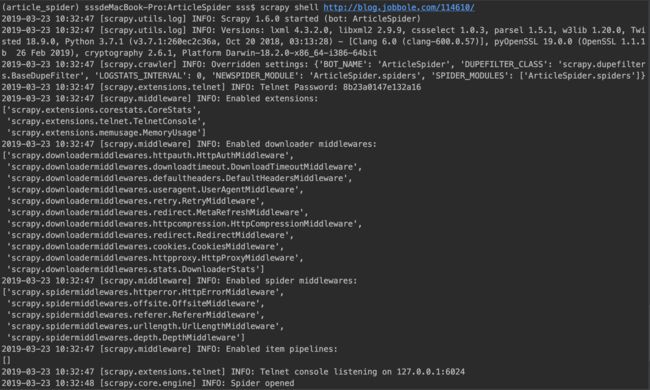
具体操作
在命令行中,之前的启动scrapy的命令是
scrapy crawl jobbole
现在可以在命令行中使用shell,命令为
scrapy shell 网址
然后就进入了调试区域
步骤如下图,注意启动scrapy必须在命令行中进入相应的虚拟环境以及项目的工作目录

我们关心的是其中的
response
-
下面开始调试
 title = response.xpath('//div[@class="entry-header"]/h1/text()')
title = response.xpath('//div[@class="entry-header"]/h1/text()')
-
访问数组的第一个值即可~

-
获取title下所有节点

3.7 爬取文章发布时间
-
该class全局唯一

 create_date = response.xpath("//p[@class='entry-meta-hide-on-mobile']/text()").extract()
create_date = response.xpath("//p[@class='entry-meta-hide-on-mobile']/text()").extract() 如果提取的字符串左右有回车符换行符等等,则需要使用
strip()将其去掉
re_selector.extract()[0].strip()
3.7 爬取文章评论数
-
找到可能是唯一判断标识的字段

-
空的呢!怎么肥事???

由于上述字段只是class中的一小部分!并不是class!
-
取得赞数
response.xpath("//span[contains(@class,'vote-post-up')]").extract()
 response.xpath("//span[contains(@class,'vote-post-up')]/h10/text()")
response.xpath("//span[contains(@class,'vote-post-up')]/h10/text()") -
提取得到赞数
 int (response.xpath("//span[contains(@class,'vote-post-up')]/h10/text()").extract()[0])
int (response.xpath("//span[contains(@class,'vote-post-up')]/h10/text()").extract()[0])
3.8 爬取文章收藏数
-
目标代码
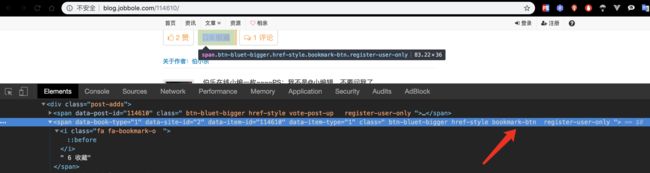
-
目标内容

可是我们只是想要个6数字而已呀,怎么办呢?使用正则提取即可!
response.xpath("//span[contains(@class,'bookmark-btn')]/text()").extract()[0]
# ' 收藏'
# 收藏数的标签设置和点赞数不一样,直接是收藏前面有数字,这里没有数字,其实是0收藏的意思。
# 对于含数字的话,我们应该使用正则表达式将数字部分提取出来。
import re
match_re = re.match('.*?(\d+).*',' 收藏')
if match_re:
fav_nums = int(match_re.group(1))
else:
fav_nums = 0
# 正则表达式注意要有?表示非贪婪匹配,可以获取两位数等
# 还有一点就是老师没有考虑的,如果没有收藏数,即匹配不到数字,说明收藏数为0.
3.9 爬取文章评论数

# 评论数和收藏数的标签设计是一样的,只需要更改xpath即可
comment_nums = response.xpath("//a[@href='#article-comment']/span/text()").extract()[0]
match_re = re.match('.*?(\d+).*', comment_nums)
if match_re:
comment_nums = int(match_re.group(1))
else:
comment_nums = 0
3.10 获取正文

content = response.xpath('//div[@class="entry"]').extract()[0]
# 对于文章内容,不同网站的设计不一样,我们一般保存html格式的内容
关于extract()方法和text()方法的区别:extract()是对一个selector的内容取出这个标签内的所有内容,包括当前的节点标签。text()方法一般是在xpath的路径内部,用于获取当前节点内的所有文本内容。
3.11 获取文章标签
# 文章标签
tag = response.xpath('//*[@id="post-114610"]/div[2]/p/a/text()').extract()
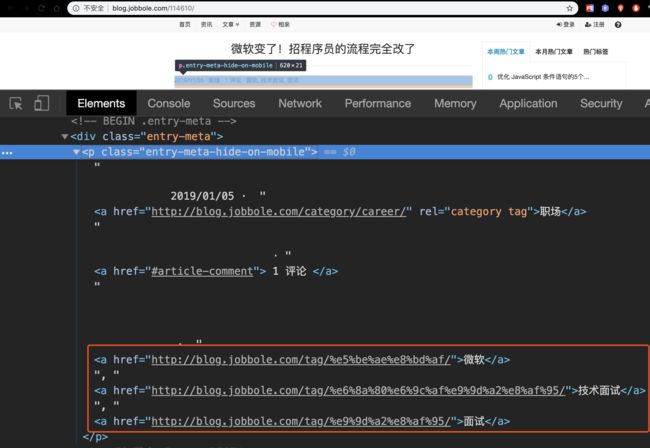
-
发现多了个评论数!
 response.xpath('//*[@id="post-114610"]/div[2]/p/a/text()').extract()
response.xpath('//*[@id="post-114610"]/div[2]/p/a/text()').extract() - 通过使用数组解决
tag_list = response.xpath("//p[@class = 'entry-meta-hide-on-mobile']/a/text()").extract()
tag_list = [element for element in tag_list if not element.strip().endswith("评论")]
# 有的网页在类型一栏中会得到评论数,以前的老设计,所以需要将关于评论的这一项去掉
tags = ",".join(tag_list)
4 css选择器实现字段解析
css选择器:通过一定的语法定位到某一个元素,与xpath选择的功能是一样的
4.1 css选择器的常见用法
| 表达式 | 说明 |
|---|---|
| * | 选择所有节点 |
| #container | 选择id为container的节点 |
| .container | 选取所有class包含container的节点 |
| li a | 选取所有li下的所有a节点 |
| ul + p | 选择ul后面的第一个p元素 |
| div#container>ul | 选取id为container的第一个ul子元素 |
| ul ~ p | 选取与ul相邻的所有p元素 |
| a[title] | 选取所有有title属性的a元素 |
| a[href=“http://jobbole.com”] | 选取所有href属性为jobbole.com值的a元素 |
| a[href*=“jobble”] | 选取所有href属性包含jobbole的a元素 |
| a[href^=“http”] | 选取所有href属性以http开头的a元素 |
| a[href$=".jpg"] | 选取所有href属性以jpg结尾的a元素 |
| input[type=radio]:checked | 选择选中的radio元素 |
| div:not(#container) | 选取所有id非container的div属性 |
| li:nth-child(3) | 选取第三个li元素 |
| tr:nth-child(2n) | 第偶数个tr |
| ::text | 利用伪类选择器获得选中的元素的内容 |
几乎对于所有的元素来说,用xpath和css都是可以完成定位功能的,但对前端朋友来说比较熟悉前端的写法,scrapy提供两种方法。css的写法是比xpath更简短的,在浏览器中都能直接获取。对前端熟悉的人可以优先考虑使用css选择器来定位一个元素,对于之前用xpath做实例的网页全用css选择器,代码如下
title = response.xpath("div.entry-header h1::text").extract()[0]
# '用 Vue 编写一个长按指令'
create_date = response.css("p.entry-meta-hide-on-mobile::text").extract()[0].strip().replace("·", "").strip()
# '2018/08/22'
praise_ums = response.css(".vote-post-up h10::text").extract_first()
if praise_ums:
praise_ums = int(praise_ums)
else:
praise_ums = 0
fav_nums = response.css(".bookmark-btn::text").extract()[0]
match_re = re.match('.*?(\d+).*',fav_nums)
if match_re:
fav_nums = int(match_re.group(1))
else:
fav_nums = 0
comment_nums = response.css("a[href='#article-comment'] span::text").extract()[0]
match_re = re.match('.*?(\d+).*', comment_nums)
if match_re:
comment_nums = int(match_re.group(1))
else:
comment_nums = 0
content = response.css("div.entry").extract()[0]
tags = response.css("p.entry-meta-hide-on-mobile a::text").extract()
tag_list = [element for element in tag_list if not element.strip().endswith("评论")]
tags = ",".join(tag_list)
注意,提示一个新的函数,extract_first(),这个函数就是相当于之前的extract()[0],但是前者好处在于避免了当取出数组为空的情况,这时候取[0]元素是会报错的,不得不做异常处理。extract()函数可以传入参数,表示如果找到的数组为空,那么就返回默认值。比如extract("")就表示如果前面取出数组为空,那么就返回空字符串.
5 spider批量爬取
首先,我们需要通过列表页爬取所有文章的url,前面部分只爬取了一个页面
start_urls这个list中只有一个url,没有涉及到如何解析这个字段,通过文章分页一页一页的传递给scrapy,让scrapy自动去下载其他页面.
5.1 在scrapy中,不需要自己使用request去请求一个页面返回,所以问题是如何将众多的url传递给scrapy完成下载呢?
查看伯乐在线的文章布局如下:
5.2 要点
在文章列表页中,每一篇文章是一个div块;
所以根据css选择器就能提取出文章列表中的每一篇的url;
需要考虑的问题是,提取出来的url是否精确,有无混杂其他推荐文章的url,这就需要css选择器足够准确!
获取了每一个具体文章的url后,如何将url传递给scrapy进行下载并返回response呢?
用到了scrapy.http中的Request类;
这个类中,可以直接传递url和callback参数,url为一个页面地址,callback为回调函数,表示对该页面进行的具体操作,所以将之前的某个具体文章的解析封装在另一个函数中,作为Request的回调函数。
还要考虑的一个地方是,提取出来的url可能不是一个完整的网址,只是域名的一部分,所以还需要将网址进行完善,比如加上域名部分,又或者原本是一个具体的文章网址,都需要处理
初始化好request之后,如何交给scrapy下载,使用yield这个关键字就可以了!
5.3 coding
-
开始调试
scrapy shell http://blog.jobbole.com/all-posts/ -
看出该范围并不准确!
 response.css(".floated-thumb .post-thumb a::attr(href)").extract()
response.css(".floated-thumb .post-thumb a::attr(href)").extract() -
通过增加该id进一步限定范围

-
这就对了嘛!
 response.css("#archive .floated-thumb .post-thumb a::attr(href)").extract()
response.css("#archive .floated-thumb .post-thumb a::attr(href)").extract() -
取到url
 response.css(".next.page-numbers::attr(href)").extract_first("")
response.css(".next.page-numbers::attr(href)").extract_first("")
5.4 开发流程
- 利用Request函数执行访问指定url并通过callback回调函数处理进入url后的操作
- 利用parse.urljoin自动将对应url添加域名,参数1是域名,参数2是url
- 利用yield实现异步请求
- 利用::attr()伪类选择器获取对应属性的值
6 item设计
6.1 非结构性数据 VS 结构性数据
6.1.1 为何不使用dict数据类型
数据爬取的主要目的就是从非结构的数据源得到结构性数据,解析完成的数据返回问题,
最简单的就是将这些字段分别都放入一个字典里,返回给scrapy.
虽然字典也很好用,但是dict缺少结构性的东西,比如字段的名字容易出错,比如fav_nums写成了fav_num,那么dict的管理就会出错。
6.1.2 item类的作用
为了将这些东西结构化,sccrapy提供了item类,可以像django一样指定字段,比如说,定义一个article_item,这个article_item有title,creat_date等字段,通过很多爬取到的item内容来实例化,就不会出错了.
item类似于字典,但是比dict的功能强大,对item进行实例化和数据赋值之后,通过yeild传递给scrapy,scrapy发现这是一个item实例时,将item路由到pipeline中去,那么在pipeline中就可以集中处理数据的保存,去重等,这就是item的作用.
6.2 item类操作步骤
6.2.1 修改settings.py文件,使item传递给pipeline生效
查看scrapy的源码,其中就有pipelines,提供了scrapy一些默认的pipline,可以加速编码过程

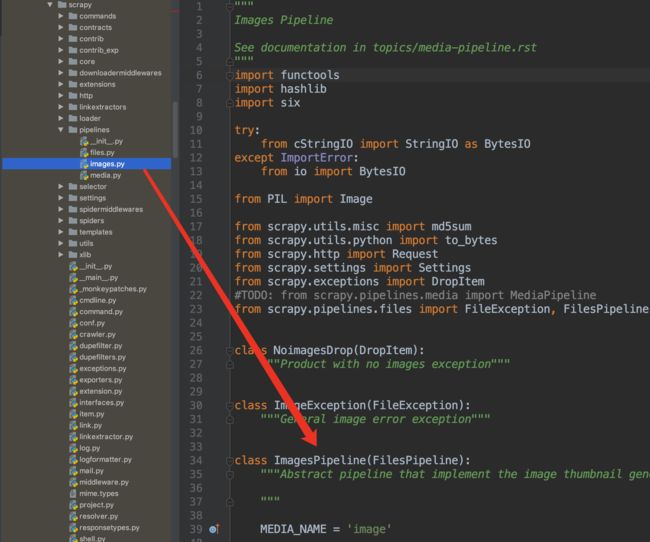
- pipeline主要用于做数据处理,item赋值之后就会传递到
pipeline.py中,需要将settings中的为了使item传递给pipeline生效,必须在settings.py文件中将一段注释的代码取消注释 -
在settings中设置下载图片的pipeline,添加到配置的ITEM_PIPELINES中(为item流经的管道,后面的数字表示处理顺序,数字越小就越早进入pipeline)

设置好之后可以在pipelines中打断点,进行调试。
image.py里面就是存放的关于下载图片的pipline,其中ImagesPipeline这个配置好之后就可以自动下载图片
scrapy 爬虫中完成图片下载到本地
将文章封面图片下载下来,并保存到本地,如何做?
scrapy提供了自动下载图片的机制,只需在settings.py中配置
在ITEM_PIPELINES中加一个scrapy的ImagePipeline即可
同时还要配置图片存放的地址IMAGES_STORE参数
以及下载图片的地址是item中的哪个字段IMAGES_URLS_FIELD参数
scrapy 提供了设置图片的保存路径,后面添加路径,可以是绝对路径,如果放到项目目录下,可使用相对路径
-
譬如,想保存在如下目录
-
配置好下载图片的pipeline之后运行检验是否配置成功,运行
main.py

是因为下载图片缺少跟图片相关的包PIL
pip install -i https://pypi.douban.com/simple pillow

-
再次运行,发现成功爬了一大堆,保存本地功能实现!


-
设置断点,进行调试

-
path即为路径值

6.2.2 在items.py文件中定义JobBoleArticleItem类
该类要继承scrapy.Item,定义的内容就是有哪些字段,并且写明字段的类型,scrapy中只有Field()类型,所以定义字段的方法为:title = scrapy.Field(),其余同理
在jobbole.py文件中,引入JobBoleArticleItem类,并且实例化一个对象,article_item = JobBoleArticleItem(),当解析出来每一个字段值后,对这个对象的每一个属性或者说字段进行填充:article_item["title"] = title,注意都定义好后需要提交给scrapy:yield article_item。
在pipelines.py文件中,如果字段中需要去下载文章封面图,并且保存到本地,获取保存到本地路径,就涉及到自定义pipeline,自己定义一个ArticleImagePipeline(ImagesPipeline)类,有继承关系,并且设置不同功能的pipeline执行的顺序,先下载图片保存本地,获取路径之后将其填充到item的front_image_path属性中,再将这个item提交给ArticlespiderPipeline(object),完成结构化数据的管理,比如存入数据库等等。
定义MD5函数





7 将item数据保存到MySQL
7.1 保存item到json文件方法:
方法一: 在pipelines.py中,自定义pipeline类保存item为json文件,并且在settings.py文件中完成配置
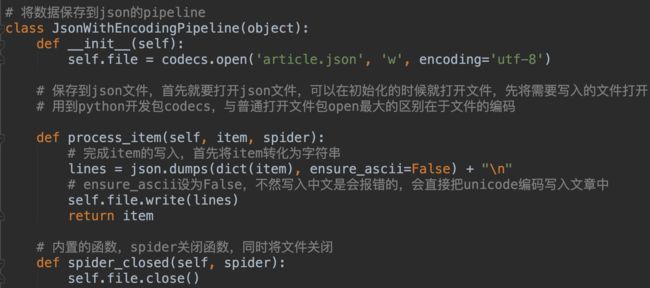

方法二: scrapy本身也提供了写入json的机制
scrapy提供了 field exporter机制,可以将item方便的导出成各种类型的文件,比如csv,xml,pickle,json等。使用方法,在pipelines.py中引入:from scrapy.exporters import JsonItemExporter

在settings中配置下该pipeline并运行

7.2 item存入MySQL
7.2.1 方法一:自定义pipeline完成存入mysql,同步机制
1 在navicat中建立article_spider数据库,并且相应的表和字段
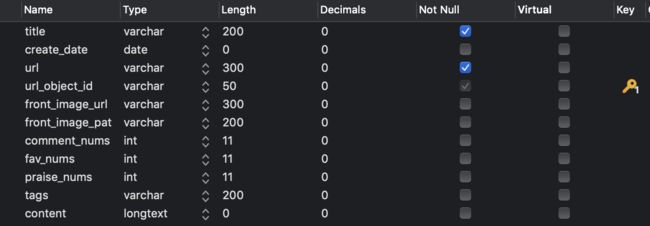
- 修改jobbole.py中的create_date为date类型(便于存储到mysql中的date类型)
-
先看时间是否正确并调试校验

-
无误~

2 安装mysql的驱动
pip3 install mysqlclient

- 如果是在linux下,命令是
sudo apt-get install libmysqlclient-devimp - 如果是在centos下,命令
sudo yum install python-devel mysql-devel
3 编写mysqlpipeline


-
报错无法解决,等候你们的解答!

上述方法(execute和commit操作是同步操作)在后期爬取加解析会快于数据存储到mysql,会导致阻塞。使用twisted框架提供的api可以完成数据的异步写入。
方法2:用到twisted的异步机制
有了方法1,为什么还要方法2,spider解析的速度肯定是超过mysql数据入库的速度,如果后期爬取的item越来越多,插入速度很不上解析速度,就会堵塞。
Twisted这个框架提供了一种将mysql关系数据库插入异步化的操作,将mysql操作变成异步化操作,方法一中的execute()和commit()是一种同步化的操作,意思就是execute不执行完,就不能往下执行,进行提交。在数据量不是很大的情况下还是可以采用方法1的,对于方法2,可以直接复制使用,需要修改的就是do_insert()函数中的内容。
Twisted框架提供了一种工具,连接池,将mysql操作变成异步操作,目前支持的是关系型数据库。
-
在setting.py中配置相关数据信息
itemloader机制
当需要解析提取的字段越来越多,写了很多xpath和css选择器,后期维护起来就很麻烦,scrapy提供的item loader机制就可以将维护工作变得简单。
具体原理
item loader提供的是一种容器,可以在其中配置item的哪个字段需要怎么的选择器.
直接调用item_loader.load_item(),可以获得item,通过选择器获得的内容都为list,未经处理,比如是list的第一个值或者评论数需要正则表达式匹配之类.
而scrapy又提供了from scrapy.loader.processors import MapCompose类,可以在items.py定义item字段类型的时候,在Field中可以添加处理函数
设计思路
- 使用itemLoader统一使用add_css/add_xpath/add_value方法获取对应数据并存储到item中
- 在item中使用scrapy.Field的参数input_processor执行MapCompose方法执行对输入值的多次函数处理
具体操作
-
引入依赖

# jobbole.py 解析字段,使用选择器
# 首先需要实例化一个ItemLoader类的对象
item_loader = ItemLoader(item=JobBoleArticleItem(),response = response) # 实例化一个对象
"""有三种重要的方法
item_loader.add_css() # 通过css选择器选择的
item_loader.add_xpath()
item_loader.add_value() # 不是选择器选择的,而是直接填充
"""
item_loader.add_css("title",".entry-header h1::text")
item_loader.add_value("url",response.url)
item_loader.add_value("url_object_id",get_md5(response.url))
item_loader.add_css("create_date", "p.entry-meta-hide-on-mobile::text")
item_loader.add_value("front_image_url",[front_image_url])
item_loader.add_css("praise_nums", ".vote-post-up h10::text")
item_loader.add_css("fav_nums", ".bookmark-btn::text")
item_loader.add_css("comment_nums", "a[href='#article-comment'] span::text")
item_loader.add_css("content", "div.entry")
item_loader.add_css("tags","p.entry-meta-hide-on-mobile a::text")
# 获取article_item
article_item = item_loader.load_item()
"""
调用默认的load_item()方法有两个问题,第一个问题会将所有的值变成一个list,虽然听起来不合理,但是从另外的角度来看,也是合理的
因为通过css选择器取出来的极有可能就是一个list,不管是取第0个还是第1个,都是一个list,所以默认情况就是list
如何解决问题呢,list里面只取第一个,以及对某个字段的list加一些额外的处理过程
在item.py对字段进行定义,scrapy.Field()里面是有参数的,input_processor表示对输入的值预处理过程,后面MapCompose()类中可以传递很多函数名的参数,表示从左到右依次处理
title = scrapy.Field(
input_processor = MapCompose(add_jobbole)
)
"""
# items.py 字段定义的时候加入处理过程
from scrapy.loader.processors import MapCompose,TakeFirst,Join
from scrapy.loader import ItemLoader
import datetime
import re
def add_jobbole(value):
return value+"-jobbole"
def date_convert(value):
try:
create_date = datetime.datetime.strptime(value, "%Y/%m/%d").date()
except Exception as e:
create_date = datetime.datetime.now().date()
return create_date
def get_nums(value):
# 对收藏数和评论数的正则处理
try:
match_re = re.match('.*?(\d+).*', value)
if match_re:
nums = int(match_re.group(1))
else:
nums = 0
except:
nums = 0
return nums
def remove_comment_tags(value):
#去掉tags中提取的评论项
# 注意input_processor中的预处理是对list中的每个元素进行处理,所以只需要判断某一项是不是包含评论,置为空即可
if "评论" in value:
return ""
else:
return value
def return_value(value):
# 这个函数是用于处理关于front_image_url字段的,本来传入就需要是list,所以不需要默认的输出处理
# 如此一来,这个字段就是一个list模式的,所以在插入语句插入的时候,是字符串类型,那么就需要取第一个值进行插入
return value
def image_add_http(value):
if "http" not in value:
value = "http:"+ value
return value
class JobBoleArticleItem(scrapy.Item):
title = scrapy.Field()
# MapCompose这个类可以将传进来的值,从左到右,连续两个函数对它处理,可以传递任意多个函数,甚至可以是匿名函数
create_date = scrapy.Field(input_processor = MapCompose(date_convert))
url = scrapy.Field()
# url实际是个变长的,可以对url做一个md5,让长度变成固定长度,把url变成唯一的长度固定的值
url_object_id = scrapy.Field()
front_image_url = scrapy.Field(input_processor = MapCompose(image_add_http),output_processor =MapCompose() )
# 如果希望把封面图保存到本地中,把封面下载下来,记录一下在本地存放的路径
front_image_path = scrapy.Field()
# 在python中数据只有一种类型,Field类型,不想django可以指明字段是int类型的等等
praise_nums = scrapy.Field(input_processor = MapCompose(get_nums))
fav_nums = scrapy.Field(input_processor = MapCompose(get_nums))
comment_nums = scrapy.Field(input_processor = MapCompose(get_nums))
content = scrapy.Field()
tags = scrapy.Field(input_processor = MapCompose(remove_comment_tags),output_processor = Join(","))
# 很多item的字段都是取list的第一个,是否需要在每个Field中都添加output_processor呢
# 可以通过自定义itemloader来解决,通过重载这个类,设置默认的输出处理设置,就可以统一处理了
class ArticleItemLoader(ItemLoader):
# 自定义itemloader
default_output_processor = TakeFirst()
整体代码调试:爬取伯乐在线文章并且将内容存入数据库
在实际保存到数据库的代码调试过程中,会遇到很多出其不意的问题,某个文章出现访问异常,或者没有封面图等异常情况,这种时候应该学会使用try_catch,捕获异常并且进行处理,从而处理个别异常文章。
报错信息:_mysql_exceptions.OperationalError: (1366, "Incorrect string value: '\xF0\x9F\x98\x8C\xE9\x99...' for column 'content' at row 1")
这个问题的原因来自于mysql的编码问题,解决办法为将mysql中数据库以及表的格式和连接数据库时的charset都要设置为utf8mb4格式,就解决了。
