今天笔者来介绍一下和调参有关的一些事情,作为算法工程师,调参是不可避免的一个工作。在坊间算法工程师有时候也被称为:调参侠。但是一个合格的算法工程师,调参这部分工作不能花费太多的气力,因为还有很多艰深的问题等着你去克服,怎么能在调参这块花大力气呢。所以自动调参的学习是一项必须学会的技能。这里笔者就介绍一个调参神器——贝叶斯调参
贝叶斯调参简介
说到自动调参大家首先会想到的就是网格搜索(网格搜索:“遍历所以的参数组合,从而选出最优的参数组合”)。笔者之前也经常会用到这个方法,但是后来搜索空间变大之后,发现网格搜索的速度太慢,所以转而投靠贝叶斯调参。接下来笔者简要介绍一下贝叶斯调参相对于网格搜索的优势:
- 贝叶斯调参采用高斯过程,会考虑到之前的参数信息,不断地更新先验;网格搜索则不会考虑先验信息。
- 贝叶斯调参迭代次数少,速度快;网格搜索会遍历所有的可能的参数组合,所以速度慢,参数多时易导致维度爆炸
- 贝叶斯调参针对非凸问题依然稳健;网格搜索针对非凸问题易得到局部最优。
当然贝叶斯调参背后涉及的高斯过程等一些数学知识,这里笔者水平有限,之后理解后再和大家详说,但是贝叶斯调参的思想就是:利用已有的先验信息去找到使目标函数达到全局最大的参数。
笔者通过实战也确实发现,贝叶斯调参确实能够很快的帮助我们发现一组还不错的参数。
实战部分
数据准备,随机产生一千个2分类的数据,每条数据的特征维度为10。
from sklearn.datasets import make_classification
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.model_selection import cross_val_score
from bayes_opt import BayesianOptimization
x, y = make_classification(n_samples=1000,n_features=10,n_classes=2)
采用GBDT默认的参数在二分类的数据上训练一遍,然后评估出模型的ROC-AUC得分,这里GBDT默认参数训练得到的模型的得分为0.952。
gbdt = GradientBoostingClassifier()
cross_val_score(gbdt, x, y, cv=20, scoring='roc_auc').mean()
### 结果是:0.952
python用户可以采用下方命令行可以快速的安装贝叶斯调试利器—— bayesian-optimization
pip install -i https://mirrors.aliyun.com/pypi/simple bayesian-optimization
这里需要定义好贝叶斯调参的目标函数,以及参数空间的范围。运行gbdt_op.maximize(),就可以开始用贝叶斯优化去搜索最优参数空间了。
from bayes_opt import BayesianOptimization
def gbdt_cv(n_estimators, min_samples_split, max_features, max_depth):
res = cross_val_score(
GradientBoostingClassifier(n_estimators=int(n_estimators),
min_samples_split=int(min_samples_split),
max_features=min(max_features, 0.999), # float
max_depth=int(max_depth),
random_state=2
),
x, y, scoring='roc_auc', cv=20
).mean()
return res
gbdt_op = BayesianOptimization(
gbdt_cv,
{'n_estimators': (10, 250),
'min_samples_split': (2, 25),
'max_features': (0.1, 0.999),
'max_depth': (5, 15)}
)
gbdt_op.maximize()
下方是调参过程,我们可以看到,各参数空间所对应的得分,以及每个参数空间的具体数值情况。
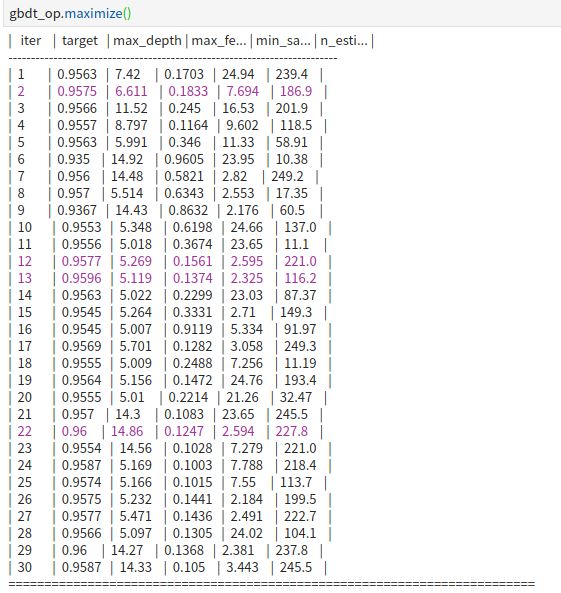
输出最优参数组合:
print(gbdt_op.max)
输出:
{'target': 0.9600151282051282,
'params': {'max_depth': 14.862826451133763,
'max_features': 0.12474933898472207,
'min_samples_split': 2.594293568638591,
'n_estimators': 227.79962861886497}}
用最优的参数组合定义一个新的GBDT,在和之前同样的数据上做训练,并生成评估得分。一旦出现更好的参数空间,会有通过不同颜色来区别。
gbdt1 = GradientBoostingClassifier(n_estimators=228,
max_depth=15,
min_samples_split=3,
max_features=0.12)
结果如下图所示:参数经贝叶斯优化的后GBDT 比之前默认参数的GBDT的ROC-AUC得分要高0.002。做个模型的朋友应该知道千分之二的算是一个不错的提升。


结语
其实贝叶斯调参最主要的优势,是节约了算法工程师的时间和精力,这样他们就可以把更多的时间和精力用来设计出精度更高,泛化能力更强的模型,去帮助业务的提升,这也是自动调参的意义所在。所以,还等什么,快把这样一个调参神器用起来吧。
参考
https://www.cnblogs.com/yangruiGB2312/p/9374377.html