1. Billion-scale Commodity Embedding for E-commerce Recommendation in Alibaba
淘宝推荐系统主要面临三个问题:
可拓展性(scalability):一些现有的推荐系统方法在小规模数据集上效果很好,当涉及数十亿规模的数据集,表现并不好。
稀疏性(sparsity):用户与很少的商品有过交互行为,使训练比较困难。
冷启动(cold start):在淘宝上,每小时有百万级别的新商品上线,预测用户对这些商品的喜好具有挑战性。
为解决上述问题,本文采用了图嵌入(graph embedding)的方法,分为两个阶段:
匹配(matching)阶段:计算商品之间的相似性,从而根据用户的历史交互行为得到用户可能喜欢的相似商品,即从大规模商品集中召回一个比较小的候选集。
排序(ranking)阶段:即对召回的候选集进行精确排序。
本文主要针对匹配阶段的问题,采用了三种方法:BGE (Base Graph Embedding)、GES (Graph Embedding with Side information)、EGES (Enhanced Graph Embedding with Side information),下面依次介绍。
1.1 BGE (Base Graph Embedding)
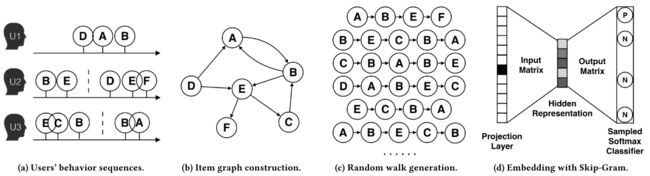
BGE的过程如图所示:
1)从用户行为中抽取序列表示,其中,如果使用用户的整个行为历史数据,则计算和存储资源消耗巨大;用户的行为在长时间是变化的,在短时间是相同的。由此,可对用户历史行为数据进行切割;
2)将序列表示为有向带权图,实际过程中需要对一些噪声数据进行过滤
3)得到有向带权图后,基于随机游走方法产生一批序列,转移概率基于边的权重
- 随后通过的方法学习每个商品的向量,优化目标是:
最终得到商品在输入矩阵中对应的embedding。
1.2 GES (Graph Embedding with Side information)
上述BGE方法可以较好得到item embedding,但是没有解决冷启动问题,由此引入GES的方法。在电商推荐系统中,边缘信息(side infromation)通常指类别、店铺、价格等,相似的边缘信息有相似的嵌入空间,例如喜欢尼康的用户也可能喜欢佳能。在加入边缘信息之后,我们称得到的embedding为商品的aggregated embeddings。商品的aggregated embeddings计作:
其中表示item embedding,,代表边缘信息对应的embedding。
1.3 EGES (Enhanced Graph Embedding with Side information)
不同的边缘信息在aggregated embeddings的权重是不同的,公式如下:
其中,表示第个边缘信息的权重,使其值大于0。
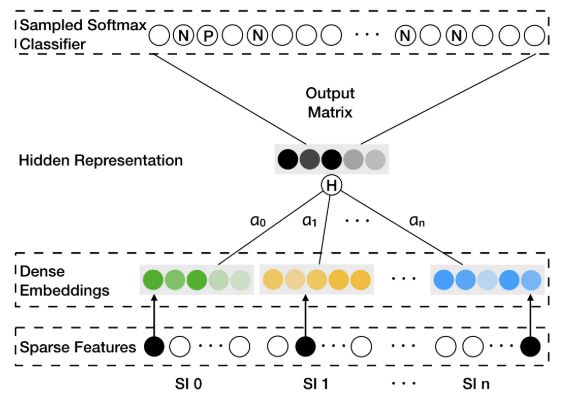
此时,损失函数可表示为:
其中表示商品u在输出矩阵中的embedding,通过反向传播进行学习:
对于边缘信息

2. Learning Tree-based Deep Model for Recommender Systems
推荐系统中召回策略主要有协同过滤和向量化召回。协同过滤不能面向全部的商品库,因此推荐结果的多样性和发现性比较差;向量化召回要求模型围绕着用户和向量的embedding展开,同时在顶层內积运算得到相似性。
对于以上问题,本文采用深度树匹配的召回策略,其核心是构造一棵兴趣树,叶子节点是全量的物品,每一层代表一种兴趣的细分,即:
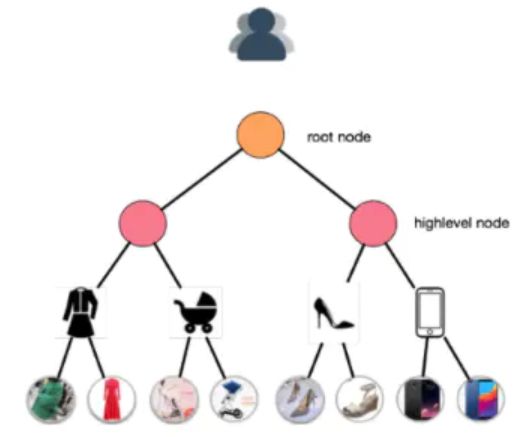
TDM模型的整体结构如下图:

2.1 基于树的高效检索
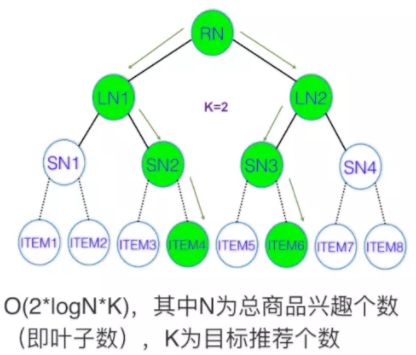
在已知深度树的情况下,可以采用Beam-Search的方式来实现高效检索:
逐层展开——每层topK节点集合作为候选
快速剪枝——每层非topK节点可停止搜索
挑选依据——用户对树节点的兴趣预估
2.2 基于树的兴趣建模
在已经得到深度树的情况下,对于新来用户,为找到其兴趣更大的分支,可考虑将树建立为最大堆树。
最大堆树下当前层最优topK子节点的父节点必然属于上层父节点最优topK。最大堆树完美支持了Beam-Search实现最优topK的性质:从根节点递归向下逐层挑选topK和拓展其子节点直至叶子节点。
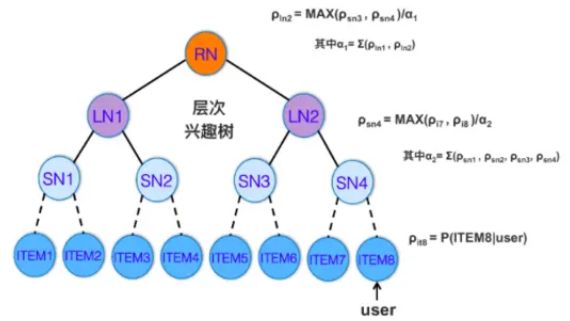
2.3 兴趣树的构建
树结构的构建对模型效果至关重要。
对于树结构的初始化,首先依据“相似的商品应具有相近的位置”的思想进行初始化。利用商品的类别信息,先对商品类别进行随机排序然后做二分割,直达每个结点代表一个商品类别;之后对每个类别中的商品进行随机排序然后做二分割,直达每个结点代表一个商品。属于多个类的商品会唯一的归为其中某一类,最终得到一个二叉树。
之后会对树结构不断进行调整学习,由于TDM对每个树结点都会学习一个隐含表示,通过k-means的方法能够会结点进行重新的聚类,对树重构。
最终模型会进行TDM训练和树重构的交替训练,使得树结构和网络表现都得以优化。
3. Learning and Transferring IDs Representation in E-commerce
本文介绍了一种ID类特征的表示方法。该方法基于item2vec方式,同时考虑了不同ID类特征之间的连接结构,在盒马鲜生app上取得了较好的应用效果。
3.1 Motivation
在电商推荐系统中,ID类特征是至关重要的特征。一般采用one-hot编码,但存在两个主要弊端:
1)高维稀疏。若有N个物品,那么用户交互过的物品的可能情况共2^N种情况,为了使我们的模型更加具有可信度,所需要的样本数量是随着N的增加呈指数级增加。
2)无法反应ID间的联系。对同质信息,如iphone 和 ipad,以及iphone 和 华为 在one-hot编码后,距离是一样的;对于异质信息如物品ID和商铺ID,它们的距离甚至无法衡量,但实际上,一家卖苹果手机的商铺和苹果手机之间,距离应该更近。
对于上述问题,出现了word2vec以及item2vec的解决方案,将ID类特征转换为一个低维的embedding向量,这种方式在电商推荐中取得了不错的效果。
本文提出的方式,基于item2vec,同时还考虑了不同ID类特征之间的连接结构,通过这些连接,在ItemID序列中的信息可以传播到其它类型的ID特征,并且可以同时学习这些ID特征的表示,如下所示:
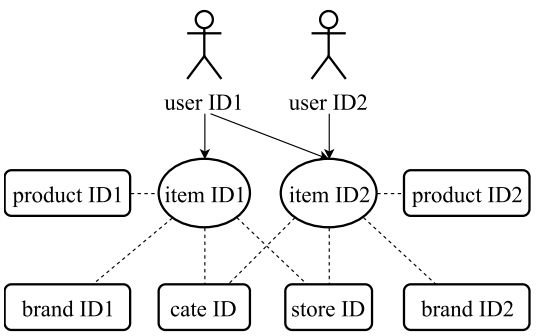
上面的学习方式在盒马app中有以下几方面的应用:
1)Measuring the similarity between items:建模物品之间的相似度
2)Transferring from seen items to unseen items:将已知物品的向量迁移到未知物品上
3)Transferring across different domains:将不同领域的向量进行迁移
4)Transferring across different tasks.:从不同的应用场景中进行迁移。
3.2 ID表示的学习
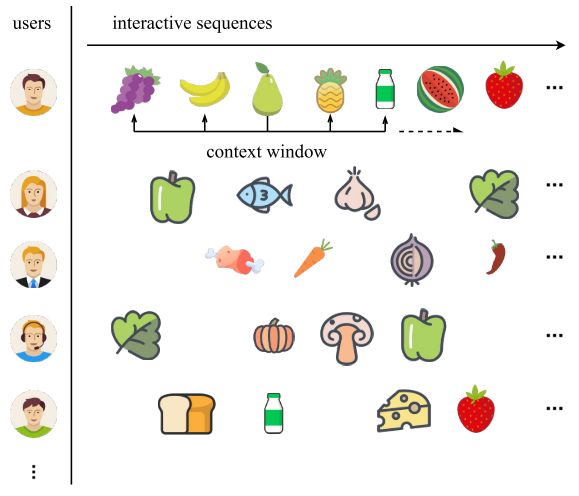
在电商领域,可以通过用户的隐式反馈,整理得到用户的一个交互序列。如果把每一个交互序列认为是一篇文档,那么我们可以通过Skip-Gram的方法来学习每一个item的向量。Skip-Gram的方法是最大化下面的对数概率:
其中,C是我们的上下文长度,假设长度是2,那么下图中梨的上下文就是前后的两个item:
在基本的Skip-Gram模型中,概率计算方式定义为如下的softmax方程:
其中,分别表示上下文向量和目标向量,D表示item的总数量。
当item的总数量十分巨大时,求解Skip-Gram的方法通常是负采样的方式,此时概率计算如下:
负采样(Log-uniform Negative-sampling)的流程如下:首先将D个物品按照其出现的频率进行降序排序,那么排名越靠前的物品,其出现的频率越高。采样基于Zipfian分布,每个物品采样到的概率如下:
由于分母都是一样的,分子依次为log(2/1),log(3/2)...log(D+1/D),是顺次减小的,同时求和为1。那么排名越靠前即出现频率越高的商品,被采样到的概率是越大的。可以求得其分布函数:
这样,当随机产生一个(0,1]之间的随机数r时,可以通过下面的转换快速得到对应的index:
3.3 ID间的结构联系
实际中的大量ID主要可以分为两组:
1)物品及其属性ID。
2)用户ID。
为将属性ID加入到物品ID上来,通过分层嵌入模型学习其低维表示,如下所示:
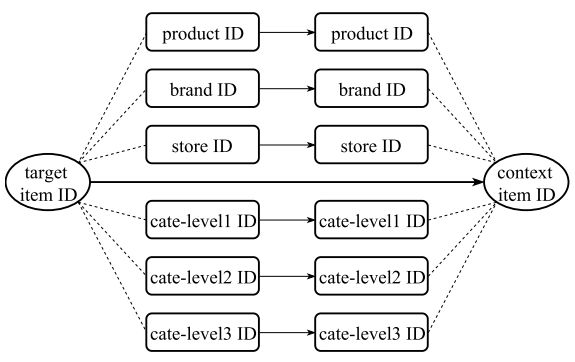
将第个商品的ID组定义如下:
则,Skip-gram的概率计算变为:
这里,每一种ID的向量长度可以是不同的,也就是说不同的ID类映射到不同的语义空间中。而权重的定义方式如下:
除了上面计算的item之间的共现概率外,我们还希望,属性ID和itemID之间也要满足一定的关系,简单理解就是希望itemID和其对应的属性ID关系越近越好,于是定义:
结合两部分的对数概率,加入正则项,则我们期望最大化的式子变为:
用户ID的Embedding通常通过其交互过的item表示,比如通过一个RNN模型或者简单的取平均的方式,这里我们将用户最近交互过的T个物品对应向量的平均值,来代表用户的Embedding:
3.4 应用
1)Measuring Items Similarity
在电商领域中,一种简单却有效的方式就是推荐给用户其喜欢的相似物品。通常使用cosine相似度来计算物品之间的相似度。那么应用上面的框架,基于得到的物品向量,便可以计算其相似度,进而推荐相似度最高的N个物品。
2)Transferring from Seen Items to Unseen Items
对于新的物品,无法得到其向量表示,这导致了许多推荐系统无法对新物品进行处理。但本文提出的方法可以在一定程度上解决冷启动问题。在模型训练时,我们添加了约束,即希望itemID和其对应的属性ID关系越近越好,如下式:
我们期望上面的式子越接近于1越好,因此:
那么对于新的物品,其对应的属性ID我们往往是知道的,基于其属性ID对应的向量,我们便可以近似计算新物品的向量。
3)Transferring across Different Domains
第三个应用主要是针对用户冷启动,在盒马平台上,相对于淘宝平台用户数量还是少很多的。那么对于盒马平台上的新用户,我们如何进行推荐呢?过程如下:
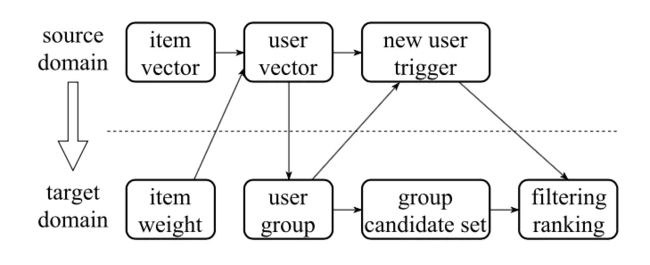
这里,用表示淘宝的用户,表示盒马的用户,表示既是淘宝又是盒马的用户,那么进行推荐的过程如下:
a. 计算淘宝用户之间的相似度,相似度的计算基于用户最近在淘宝交互过的T个商品的向量。可以是简单的平均,可以是加权平均。权重取决于人工的设定,比如购买是5,点击是1;
b. 基于计算的用户相似度,对中的用户进行k-均值聚类,这里聚成1000个类别;
c. 对于每个类别,选择N个最受欢迎的盒马上的物品,作为候选集;
d. 对于盒马上的一个新用户,如果它在淘宝上有交互记录,那么就取得他在淘宝上对应的用户向量,并计算该向量所属的类别;
e. 基于得到的类别,将经过筛选和排序后的该类别的候选集中物品中推荐给用户。
4)Transferring across Different Tasks
这里,我们主要对每个店铺第二天每个30分钟的配送需求进行预测,这里有三种不同的输入:
a. 仅使用过去7天每三十分钟的店铺配送量作为输入
b. 使用使用过去7天每三十分钟的店铺配送量作为输入 + 店铺ID的one-hot encoding
c. 使用使用过去7天每三十分钟的店铺配送量作为输入 + 店铺ID对应的向量。
输入经过全联接神经网络得到配送需求的预测值,并通过RMAE指标来计算误差。
参考资料
[1] https://www.jianshu.com/p/229b686535f1
[2] https://www.jianshu.com/p/647669169f98
[3] https://www.jianshu.com/p/285978e29458
阳春布德泽,万物生光辉。——汉乐府《长歌行》