新年可能华人科学家们都过年去了,结果都没搞出个什么大新闻。
动漫网络的崛起,拥有290万张图片和7750万个标签

虽然肯定比不上ImageNet,但是确实很大......
一些喜欢捣鼓的人从动漫图片获取出了一个大规模数据集。他们写道,“ Danbooru 数据集比整个 ImageNet 还大,比当前最大的多描述数据集 MS COCO 还大”。 每张图片都有一大堆与其相关的元数据,包括它在图片网页板上的受欢迎程度(booru值)等。
数据集的构成问题:研究人员指出:“图片主要集中在女性动漫角色,但她们会被放置在各种各样的带有大量有标签物品或动作环境中,大量的图片意味着将会包含更多错误的图片。“
数据集的图像根据“安全”,“可疑”和“明确”进行了分类(是否是小黄图),发布时的粗略分布大概为 76.3% "安全",14.9% "可疑"和 8.7% "明确"图片。这个数据集的发布似乎引发了一些道德问题,我首先关心的是有这么多“明确”图片的数据集,几乎总是会导致各种猥琐的AI实验,这样会让人们对AI社群产生更深的偏见。
示例用途:研究人员设想数据集可用于一系列任务,从分类到图像生成,再到用元数据预测图像特征等等。
更进一步的正当用途:这个数据集更重要的是,可以鼓励人们开发具有更高抽象层次的模型,而不是那是只是简单地映射纹理组合(如ImageNet)的模型等等。 “插图往往是黑白的,而不是颜色,是线条艺术而不是照片,即使彩色插图往往也更少依赖于纹理,更多的依赖于线条(纹理被省略或用重复模式填充),在一个更高的抽象层次 进行思考- 一个豹不会被黑黄点的模式匹配那么简单识别出来。“,他们写。 “因为插图是通过一个完全不同的过程生成的,并且只关注显着的细节,同时抽象其他部分,所以它们可以用来测试标记者使用的更高级语义感知。”
更多:Danbooru2017: A large-scale crowdsourced and tagged animeillustration dataset (Gwern.)
Facebook Tensor Comprehensions试图将深度学习艺(Xuan)术(Xue)转化为工程科学

...代码库简化了高性能AI系统的创建......
Facebook AI Research发布了Tensor Comprehensions,这是一个将标准深度学习库代码自动转换为高性能代码的软件库。你可以认为这个软件就像一个非常有能力的执行助理,你的AI研究人员用C ++编写一些代码(PyTorch的支持正在开发中),然后把它交给Tensor Comprehensions,优化代码以创建自定义CUDA内核,以便在GPU上运行,并具有诸如硬件上的智能调度等良好特性。甚至还包括一个'进化搜索'功能,让你自动探索和选择最高性能的实现。
为什么很重要:深度学习正在从手艺(这也是为什么调侃为玄学)转向工业化科学; Tensor Comprehensions代表了人工密集型AI研发循环中的一个新层次,意味着该技术研究和部署的进一步加速。
更多信息:Announcing Tensor Comprehensions (FAIR).
更多:Tensor Comprehensions: Framework-AgnosticHigh-Performance Machine Learning Abstractions (Arxiv).
深度学习检测可疑URL
...词和字符级别的模型组合可以提高恶意URL的分类性能......
新加坡管理大学的研究人员发表了关于URLNet的详细信息,这是一种使用神经网络方法自动将URL分类为危险或安全点击的系统。
重要的是:“在不使用任何手工设计特征下,URLNet有着对基线的显着提升,”他们写道。到目前为止,类似的事情发生了很多遍:只要给予足够大的数据集,基于神经网络技术的模型往往比手工设计特征的系统更加好。 (注意:在许多领域获取数据很困难,而且模型需要快速更新以应对瞬息万变的世界,使得用不上深度学习。)
工作原理:URLNet使用卷积神经网络将URL分类为字符级和词级表示。词级嵌入有助于根据高级学习语义进行分类,而字符级嵌入允许它更好地推广到新单词,字符串和组合。研究人员写道:“字符级别CNN还允许在测试数据中轻松获得新URL的嵌入,因此可以从未见的单词中提取模式。”
对于单词级网络,系统做两件事:它接受新单词并学习它们的嵌入,并且还初始化一个新的特征级CNN以建立从字符嵌入获得的词嵌入。这意味着,即使在系统遇到新词把它标为“
数据集:研究人员从一家杀毒公司 VirusTotal 中生成了一组1500万个网址,创建了一个有着1400万个良性网站和100万个恶意网站的数据集。
结果:研究人员将他们的系统与基于支持向量机的基准方法进行了比较。研究人员在本文的“图5”中做了很好的可视化,显示他们系统的特征嵌入如何合理分割恶意URL,表明它已经学会了一些有力的潜在语义分类模型。
阅读更多:URLNet: Learning a URL Representation with Deep Learningfor Malicious Url Detection (Arxiv).
斯坦福研究人员在设计DAWNBench时遇到了再现危机

假的,都是假的,深度学习什么的......
斯坦福研究人员讨论了他们在开发DAWNBench时遇到的一些困难。DAWNBench是一个评估深度学习方法的基准,它使用一系列不同的指标评估深度学习方法,如推理延迟和成本,以及训练时间等等。他们的结论对于大多数深度学习炼丹师们来说应该是熟悉的:不能理解为什么深度学习有好结果,仍然缺乏理论保证来理解,一个研究突破与另一个研究突破结合时是如何进行互动的。
为什么很重要:深度学习仍然处于“经验科学”阶段,像DAWNBench这样基准的到来,还有之前的比如Deep Reinforcement Learning that Matters(其结论是随机种子很大程度上决定了RL的最终表现)所说的,将有助于解决表面问题,并迫使深度学习社区制定更有力的方法。
更多:Deep Learning Pitfalls Encountered while DevelopingDAWNBench.
**更多: **Deep Reinforcement Learning that Matters (Arxiv).
让算法自动设计99%的神经架构:
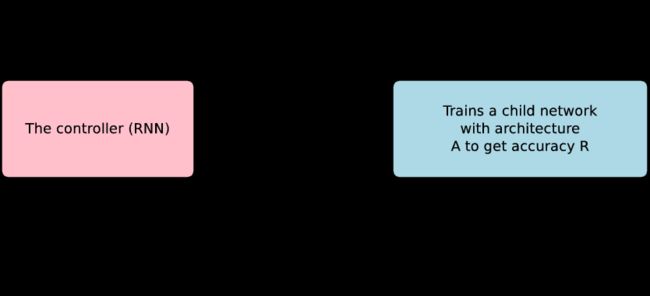
...研究人员想出一种方法可以让NAS技术在单个GPU上工作,而不是几百个...
AI中近期最引人注目的趋势之一就是神经架构搜索技术 (NAS)的出现,就是自动设计AI系统,如图像分类器。到目前为止,这些方法最大的缺点就是计算成本太高,一次使用数百个GPU,因此对于大多数研究人员来说是不可行的。随着SMASH的发布,去年开始发生了些变化,通过在准确性和灵活性方面略微进行取舍,使得在比较少的计算量情况下进行自动搜索。
现在,谷歌,CMU和斯坦福大学的研究人员已经通过一种新技术“高效神经架构搜索(ENAS)”, 向前推进了低成本NAS技术。该技术可以只用单个NVIDIA 1080 GPU不到一天的计算量来设计出一个最先端的系统。这代表该技术的计算成本降低了1000倍!这意味着我们甚至可以设计一些能够媲美大型系统的架构。
为什么重要:在过去几年中,很多聪明人都把大量时间花在设计神经网络架构上。像NAS这样的方法允许我们自动化特定体系结构的设计,使研究人员能够腾出更多的时间在基础任务上,比如发明NAS系统可以用来构建模型的新构建块,或者其他技术以进一步提高架构的效率设计。从广义上讲,像NAS这样的方法意味着我们可以简单地将大量工作从人类大脑卸载到计算机大脑。这无疑非常划算。
更多:Efficient Neural Architecture Search via ParameterSharing (Arxiv).