BFC、IFC、GFC、FFC
CSS2.1中只有BFC和IFC, CSS3中才有GFC和FFC。
到底什么是BFC、IFC、GFC和FFC
What's FC?
一定不是KFC,FC的全称是:Formatting Contexts,是W3C CSS2.1规范中的一个概念。它是页面中的一块渲染区域,并且有一套渲染规则,它决定了其子元素将如何定位,以及和其他元素的关系和相互作用。
BFC
BFC(Block Formatting Contexts)直译为"块级格式化上下文"。Block Formatting Contexts就是页面上的一个隔离的渲染区域,容器里面的子元素不会在布局上影响到外面的元素,反之也是如此。如何产生BFC?
float的值不为none。
overflow的值不为visible。
position的值不为relative和static。
display的值为table-cell, table-caption, inline-block中的任何一个。
那BFC一般有什么用呢?比如常见的多栏布局,结合块级别元素浮动,里面的元素则是在一个相对隔离的环境里运行。
IFC
IFC(Inline Formatting Contexts)直译为"内联格式化上下文",IFC的line box(线框)高度由其包含行内元素中最高的实际高度计算而来(不受到竖直方向的padding/margin影响)
IFC中的line box一般左右都贴紧整个IFC,但是会因为float元素而扰乱。float元素会位于IFC与与line box之间,使得line box宽度缩短。 同个ifc下的多个line box高度会不同。 IFC中时不可能有块级元素的,当插入块级元素时(如p中插入div)会产生两个匿名块与div分隔开,即产生两个IFC,每个IFC对外表现为块级元素,与div垂直排列。
那么IFC一般有什么用呢?
水平居中:当一个块要在环境中水平居中时,设置其为inline-block则会在外层产生IFC,通过text-align则可以使其水平居中。
垂直居中:创建一个IFC,用其中一个元素撑开父元素的高度,然后设置其vertical-align:middle,其他行内元素则可以在此父元素下垂直居中。
GFC
GFC(GridLayout Formatting Contexts)直译为"网格布局格式化上下文",当为一个元素设置display值为grid的时候,此元素将会获得一个独立的渲染区域,我们可以通过在网格容器(grid container)上定义网格定义行(grid definition rows)和网格定义列(grid definition columns)属性各在网格项目(grid item)上定义网格行(grid row)和网格列(grid columns)为每一个网格项目(grid item)定义位置和空间。
那么GFC有什么用呢,和table又有什么区别呢?首先同样是一个二维的表格,但GridLayout会有更加丰富的属性来控制行列,控制对齐以及更为精细的渲染语义和控制。
FFC
FFC(Flex Formatting Contexts)直译为"自适应格式化上下文",display值为flex或者inline-flex的元素将会生成自适应容器(flex container),可惜这个牛逼的属性只有谷歌和火狐支持,不过在移动端也足够了,至少safari和chrome还是OK的,毕竟这俩在移动端才是王道。
Flex Box 由伸缩容器和伸缩项目组成。通过设置元素的 display 属性为 flex 或 inline-flex 可以得到一个伸缩容器。设置为 flex 的容器被渲染为一个块级元素,而设置为 inline-flex 的容器则渲染为一个行内元素。
伸缩容器中的每一个子元素都是一个伸缩项目。伸缩项目可以是任意数量的。伸缩容器外和伸缩项目内的一切元素都不受影响。简单地说,Flexbox 定义了伸缩容器内伸缩项目该如何布局。
div水平垂直居中的方法
在平时,我们经常会碰到让一个div框针对某个模块上下左右都居中(水平垂直居中),其实针对这种情况,我们有多种方法实现。
方法一:
绝对定位方法:不确定当前div的宽度和高度,采用 transform: translate(-50%,-50%); 当前div的父级添加相对定位(position: relative;)
图片展示:

代码如下:
div{
background:red;
position: absolute;
left:50%;
top:50%;
transform: translate(-50%, -50%);
}
方法二:
绝对定位方法:确定了当前div的宽度,margin值为当前div宽度一半的负值
图片展示: 如方法一的图片展示
代码如下:
div{
width:600px;
height: 600px;
background:red;
position: absolute;
left:50%;
top:50%;
margin-left:-300px;
margin-top:-300px;
}
方法三:
绝对定位方法:绝对定位下top left right bottom 都设置0
图片展示: 如方法一的图片展示
代码如下:
div.child{
width: 600px;
height: 600px;
background: red;
position:absolute;
left:0;
top: 0;
bottom: 0;
right: 0;
margin: auto;
}
方法四:
flex布局方法:当前div的父级添加flex css样式
展示图如下:

代码如下:
.box{
height:800px;
-webkit-display:flex;
display:flex;
-webkit-align-items:center;
align-items:center;
-webkit-justify-content:center;
justify-content:center;
border:1px solid #ccc;
}
div.child{
width:600px;
height:600px;
background-color:red;
}
方法五:
table-cell实现水平垂直居中: table-cell middle center组合使用
展示图如下:

代码如下:
.table-cell {
display: table-cell;
vertical-align: middle;
text-align: center;
width: 240px;
height: 180px;
border:1px solid #666;
}
方法六:
绝对定位:calc() 函数动态计算实现水平垂直居中
展示图如下:
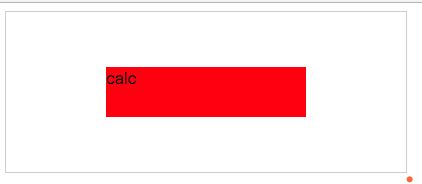
代码如下:
.calc{
position: relative;
border: 1px solid #ccc;
width: 400px;
height: 160px;
}
.calc .child{
position: absolute;
width: 200px;
height: 50px;
left:-webkit-calc((400px - 200px)/2);
top:-webkit-calc((160px - 50px)/2);
left:-moz-calc((400px - 200px)/2);
top:-moz-calc((160px - 50px)/2);
left:calc((400px - 200px)/2);
top:calc((160px - 50px)/2);
}
display: none;
- DOM 结构:浏览器不会渲染 display 属性为 none 的元素,不占据空间;
- 事件监听:无法进行 DOM 事件监听;
- 性能:动态改变此属性时会引起重排,性能较差;
- 继承:不会被子元素继承,毕竟子类也不会被渲染;
- transition:transition 不支持 display。
visibility: hidden;
- DOM 结构:元素被隐藏,但是会被渲染不会消失,占据空间;
- 事件监听:无法进行 DOM 事件监听;
- 性 能:动态改变此属性时会引起重绘,性能较高;
- 继 承:会被子元素继承,子元素可以通过设置 visibility: visible; 来取消隐藏;
- transition:visibility 会立即显示,隐藏时会延时
opacity: 0;
- DOM 结构:透明度为 100%,元素隐藏,占据空间;
- 事件监听:可以进行 DOM 事件监听;
- 性 能:提升为合成层,不会触发重绘,性能较高;
- 继 承:会被子元素继承,且,子元素并不能通过 opacity: 1 来取消隐藏;
- transition:opacity 可以延时显示和隐藏
在不改变当前代码的情况下,使这张图片的宽度为300px?

1.css方法
2.js方法
document.getElementsByTagName("img")[0].setAttribute("style","width:300px!important;")
7 种方法解决移动端 Retina 屏幕 1px 边框问题
造成边框变粗的原因
其实这个原因很简单,因为css中的1px并不等于移动设备的1px,这些由于不同的手机有不同的像素密度。在window对象中有一个devicePixelRatio属性,他可以反应css中的像素与设备的像素比。
devicePixelRatio的官方的定义为:设备物理像素和设备独立像素的比例,也就是 devicePixelRatio = 物理像素 / 独立像素。
解决边框变粗的6种办法
1、0.5px边框
在2014年的 WWDC,“设计响应的Web体验” 一讲中,Ted O’Connor 讲到关于“retinahairlines”(retina 极细的线):在retina屏上仅仅显示1物理像素的边框,开发者应该如何处理呢。
他们曾介绍到 iOS 8 和 OS X Yosemite 即将支持 0.5px 的边框:
[图片上传失败...(image-6431d2-1597762908407)]
0.5px边框
额的神呐!so easy! 果真如此吗?这样还不够(WWDC幻灯片通常是“唬人”的),但是相差不多。
问题是 retina 屏的浏览器可能不认识0.5px的边框,将会把它解释成0px,没有边框。包括 iOS 7 和之前版本,OS X Mavericks 及以前版本,还有 Android 设备。
解决方案:
解决方案是通过 JavaScript 检测浏览器能否处理0.5px的边框,如果可以,给html标签元素添加个class。
if (window.devicePixelRatio && devicePixelRatio >= 2) {
var testElem = document.createElement('div');
testElem.style.border = '.5px solid transparent';
document.body.appendChild(testElem);
if (testElem.offsetHeight == 1) {
document.querySelector('html').classList.add('hairlines');
}
document.body.removeChild(testElem);
}
// 脚本应该放在内,如果在里面运行,需要包装 $(document).ready(function() {})
然后,极细的边框样式就容易了:
div {
border: 1px solid #bbb;
}
.hairlines div {
border-width: 0.5px;
}
2、使用border-image实现
准备一张符合你要求的border-image:
[图片上传失败...(image-b220f2-1597762908407)]
底部边框
样式设置:
.border-bottom-1px {
border-width: 0 0 1px 0;
-webkit-border-image: url(linenew.png) 0 0 2 0 stretch;
border-image: url(linenew.png) 0 0 2 0 stretch;
}
上文是把border设置在边框的底部,所以使用的图片是2px高,上部的1px颜色为透明,下部的1px使用视觉规定的border的颜色。如果边框底部和顶部同时需要border,可以使用下面的border-image:
[图片上传失败...(image-d6c12a-1597762908407)]
上下边框
样式设置:
.border-image-1px {
border-width: 1px 0;
-webkit-border-image: url(linenew.png) 2 0 stretch;
border-image: url(linenew.png) 2 0 stretch;
}
到目前为止,我们已经能在iphone上展现1px border的效果了。但是我们发现这样的方法在非视网膜屏上会出现border显示不出来的现象,于是使用Media Query做了一些兼容,样式设置如下:
.border-image-1px {
border-bottom: 1px solid #666;
}
@media only screen and (-webkit-min-device-pixel-ratio: 2) {
.border-image-1px {
border-bottom: none;
border-width: 0 0 1px 0;
-webkit-border-image: url(../img/linenew.png) 0 0 2 0 stretch;
border-image: url(../img/linenew.png) 0 0 2 0 stretch;
}
}
缺点:
- 修改颜色麻烦, 需要替换图片
- 圆角需要特殊处理,并且边缘会模糊
3、使用background-image实现
background-image 跟border-image的方法一样,你要先准备一张符合你要求的图片。然后将边框模拟在背景上。
样式设置:
.background-image-1px {
background: url(../img/line.png) repeat-x left bottom;
-webkit-background-size: 100% 1px;
background-size: 100% 1px;
}
优点:
缺点:
- 修改颜色麻烦, 需要替换图片
- 圆角需要特殊处理,并且边缘会模糊
4、多背景渐变实现
与background-image方案类似,只是将图片替换为css3渐变。设置1px的渐变背景,50%有颜色,50%透明。
样式设置:
.background-gradient-1px {
background:
linear-gradient(180deg, black, black 50%, transparent 50%) top left / 100% 1px no-repeat,
linear-gradient(90deg, black, black 50%, transparent 50%) top right / 1px 100% no-repeat,
linear-gradient(0, black, black 50%, transparent 50%) bottom right / 100% 1px no-repeat,
linear-gradient(-90deg, black, black 50%, transparent 50%) bottom left / 1px 100% no-repeat;
}
/* 或者 */
.background-gradient-1px{
background: -webkit-gradient(linear, left top, left bottom, color-stop(.5, transparent), color-stop(.5, #c8c7cc), to(#c8c7cc)) left bottom repeat-x;
background-size: 100% 1px;
}
5、使用box-shadow模拟边框
利用css 对阴影处理的方式实现0.5px的效果
样式设置:
.box-shadow-1px {
box-shadow: inset 0px -1px 1px -1px #c8c7cc;
}
优点:
缺点:
6、viewport + rem 实现
同时通过设置对应viewport的rem基准值,这种方式就可以像以前一样轻松愉快的写1px了。
在devicePixelRatio = 2 时,输出viewport:
在devicePixelRatio = 3 时,输出viewport:
```html
这种兼容方案相对比较完美,适合新的项目,老的项目修改成本过大。
对于这种方案,可以看看《使用Flexible实现手淘H5页面的终端适配》
优点:
缺点:
7、伪类 + transform 实现
对于老项目,有没有什么办法能兼容1px的尴尬问题了,个人认为伪类+transform是比较完美的方法了。原理是把原先元素的 border 去掉,然后利用 :before 或者 :after 重做 border ,并 transform 的 scale 缩小一半,原先的元素相对定位,新做的 border 绝对定位。
单条border样式设置:
.scale-1px{
position: relative;
border:none;
}
.scale-1px:after{
content: '';
position: absolute;
bottom: 0;
background: #000;
width: 100%;
height: 1px;
-webkit-transform: scaleY(0.5);
transform: scaleY(0.5);
-webkit-transform-origin: 0 0;
transform-origin: 0 0;
}
四条boder样式设置:
.scale-1px{
position: relative;
margin-bottom: 20px;
border:none;
}
.scale-1px:after{
content: '';
position: absolute;
top: 0;
left: 0;
border: 1px solid #000;
-webkit-box-sizing: border-box;
box-sizing: border-box;
width: 200%;
height: 200%;
-webkit-transform: scale(0.5);
transform: scale(0.5);
-webkit-transform-origin: left top;
transform-origin: left top;
}
最好在使用前也判断一下,结合 JS 代码,判断是否 Retina 屏:
if(window.devicePixelRatio && devicePixelRatio >= 2){
document.querySelector('ul').className = 'scale-1px';
}
优点:
- 所有场景都能满足
- 支持圆角(伪类和本体类都需要加border-radius)
缺点:
- 对于已经使用伪类的元素(例如clearfix),可能需要多层嵌套
['1', '2', '3'].map(parseInt)
what & why ?
早在 2013年, 有人在微博上发布了以下代码段:
['10','10','10','10','10'].map(parseInt);
// [10, NaN, 2, 3, 4]
parseInt
parseInt() 函数解析一个字符串参数,并返回一个指定基数的整数 (数学系统的基础)。
const intValue = parseInt(string[, radix]);
string 要被解析的值。如果参数不是一个字符串,则将其转换为字符串(使用 ToString 抽象操作)。字符串开头的空白符将会被忽略。
radix 一个介于2和36之间的整数(数学系统的基础),表示上述字符串的基数。默认为10。 返回值 返回一个整数或NaN
parseInt(100); // 100
parseInt(100, 10); // 100
parseInt(100, 2); // 4 -> converts 100 in base 2 to base 10
注意: 在radix为 undefined,或者radix为 0 或者没有指定的情况下,JavaScript 作如下处理:
- 如果字符串 string 以"0x"或者"0X"开头, 则基数是16 (16进制).
- 如果字符串 string 以"0"开头, 基数是8(八进制)或者10(十进制),那么具体是哪个基数由实现环境决定。ECMAScript 5 规定使用10,但是并不是所有的浏览器都遵循这个规定。因此,永远都要明确给出radix参数的值。
- 如果字符串 string 以其它任何值开头,则基数是10 (十进制)。
更多详见parseInt | MDN
map
map() 方法创建一个新数组,其结果是该数组中的每个元素都调用一个提供的函数后返回的结果。
var new_array = arr.map(function callback(currentValue[,index[, array]]) {
// Return element for new_array
}[, thisArg])
可以看到callback回调函数需要三个参数, 我们通常只使用第一个参数 (其他两个参数是可选的)。 currentValue 是callback 数组中正在处理的当前元素。 index可选, 是callback 数组中正在处理的当前元素的索引。 array可选, 是callback map 方法被调用的数组。 另外还有thisArg可选, 执行 callback 函数时使用的this 值。
const arr = [1, 2, 3];
arr.map((num) => num + 1); // [2, 3, 4]
更多详见Array.prototype.map() | MDN
回到真实的事例上
回到我们真实的事例上
['1', '2', '3'].map(parseInt)
对于每个迭代map, parseInt()传递两个参数: 字符串和基数。 所以实际执行的的代码是:
['1', '2', '3'].map((item, index) => {
return parseInt(item, index)
})
即返回的值分别为:
parseInt('1', 0) // 1
parseInt('2', 1) // NaN
parseInt('3', 2) // NaN, 3 不是二进制
所以:
['1', '2', '3'].map(parseInt)
// 1, NaN, NaN
由此,加里·伯恩哈德例子也就很好解释了,这里不再赘述
['10','10','10','10','10'].map(parseInt);
// [10, NaN, 2, 3, 4]
如何在现实世界中做到这一点
如果您实际上想要循环访问字符串数组, 该怎么办? map()然后把它换成数字?使用编号!
['10','10','10','10','10'].map(Number);
// [10, 10, 10, 10, 10]
作者解答:
概念:以第二个参数为基数来解析第一个参数字符串,通常用来做十进制的向上取整。
特点:接收两个参数parseInt(string,radix)
radix:解析字符串的基数,基数规则如下:
1) 区间范围介于2~36之间;
2 ) 当参数为 0,parseInt() 会根据十进制来解析;
3 ) 如果忽略该参数,默认的基数规则
parseInt('10',0);radix 为 0,parseInt() 会根据十进制来解析,所以结果为 10;
parseInt('10',1);radix 为 1,超出区间范围,所以结果为 NaN;
parseInt('10',2);radix 为 2,用2进制来解析,1乘以2的1次方+0乘以2的0次方,所以结果是2
parseInt('10',3);radix 为 3,用3进制来解析,1乘以3的1次方+0乘以3的0次方,所以结果是3
parseInt('10',4);radix 为 4,用4进制来解析,1乘以4的1次方+0乘以4的0次方,所以结果是4
函数节流与函数防抖
什么是函数节流与函数防抖
举个栗子,我们知道目前的一种说法是当 1 秒内连续播放 24 张以上的图片时,在人眼的视觉中就会形成一个连贯的动画,所以在电影的播放(以前是,现在不知道)中基本是以每秒 24 张的速度播放的,为什么不 100 张或更多是因为 24 张就可以满足人类视觉需求的时候,100 张就会显得很浪费资源。
再举个栗子,假设电梯一次只能载一人的话,10 个人要上楼的话电梯就得走 10 次,是一种浪费资源的行为;而实际生活正显然不是这样的,当电梯里有人准备上楼的时候如果外面又有人按电梯的话,电梯会再次打开直到满载位置,从电梯的角度来说,这时一种节约资源的行为(相对于一次只能载一个人)。
- 函数节流: 指定时间间隔内只会执行一次任务;
- 函数防抖: 任务频繁触发的情况下,只有任务触发的间隔超过指定间隔的时候,任务才会执行。
函数节流(throttle)
这里以判断页面是否滚动到底部为例,普通的做法就是监听 window 对象的 scroll 事件,然后再函数体中写入判断是否滚动到底部的逻辑:
$(window).on('scroll', function () {
// 判断是否滚动到底部的逻辑
let pageHeight = $('body').height(),
scrollTop = $(window).scrollTop(),
winHeight = $(window).height(),
thresold = pageHeight - scrollTop - winHeight;
if (thresold > -100 && thresold <= 20) {
console.log('end');
}
});
这样做的一个缺点就是比较消耗性能,因为当在滚动的时候,浏览器会无时不刻地在计算判断是否滚动到底部的逻辑,而在实际的场景中是不需要这么做的,在实际场景中可能是这样的:在滚动过程中,每隔一段时间在去计算这个判断逻辑。而函数节流所做的工作就是每隔一段时间去执行一次原本需要无时不刻地在执行的函数,所以在滚动事件中引入函数的节流是一个非常好的实践:
$(window).on('scroll', throttle(function () {
// 判断是否滚动到底部的逻辑
let pageHeight = $('body').height(),
scrollTop = $(window).scrollTop(),
winHeight = $(window).height(),
thresold = pageHeight - scrollTop - winHeight;
if (thresold > -100 && thresold <= 20) {
console.log('end');
}
}));
加上函数节流之后,当页面再滚动的时候,每隔 300ms 才会去执行一次判断逻辑。
简单来说,函数的节流就是通过闭包保存一个标记(canRun = true),在函数的开头判断这个标记是否为 true,如果为 true 的话就继续执行函数,否则则 return 掉,判断完标记后立即把这个标记设为 false,然后把外部传入的函数的执行包在一个 setTimeout 中,最后在 setTimeout 执行完毕后再把标记设置为 true(这里很关键),表示可以执行下一次的循环了。当 setTimeout 还未执行的时候,canRun 这个标记始终为 false,在开头的判断中被 return 掉。
function throttle(fn, interval = 300) {
let canRun = true;
return function () {
if (!canRun) return;
canRun = false;
setTimeout(() => {
fn.apply(this, arguments);
canRun = true;
}, interval);
};
}
函数防抖(debounce)
这里以用户注册时验证用户名是否被占用为例,如今很多网站为了提高用户体验,不会再输入框失去焦点的时候再去判断用户名是否被占用,而是在输入的时候就在判断这个用户名是否已被注册:
$('input.user-name').on('input', function () {
$.ajax({
url: `https://just.com/check`,
method: 'post',
data: {
username: $(this).val(),
},
success(data) {
if (data.isRegistered) {
$('.tips').text('该用户名已被注册!');
} else {
$('.tips').text('恭喜!该用户名还未被注册!');
}
},
error(error) {
console.log(error);
},
});
});
很明显,这样的做法不好的是当用户输入第一个字符的时候,就开始请求判断了,不仅对服务器的压力增大了,对用户体验也未必比原来的好。而理想的做法应该是这样的,当用户输入第一个字符后的一段时间内如果还有字符输入的话,那就暂时不去请求判断用户名是否被占用。在这里引入函数防抖就能很好地解决这个问题:
$('input.user-name').on('input', debounce(function () {
$.ajax({
url: `https://just.com/check`,
method: 'post',
data: {
username: $(this).val(),
},
success(data) {
if (data.isRegistered) {
$('.tips').text('该用户名已被注册!');
} else {
$('.tips').text('恭喜!该用户名还未被注册!');
}
},
error(error) {
console.log(error);
},
});
}));
其实函数防抖的原理也非常地简单,通过闭包保存一个标记来保存 setTimeout 返回的值,每当用户输入的时候把前一个 setTimeout clear 掉,然后又创建一个新的 setTimeout,这样就能保证输入字符后的 interval 间隔内如果还有字符输入的话,就不会执行 fn 函数了。
function debounce(fn, interval = 300) {
let timeout = null;
return function () {
clearTimeout(timeout);
timeout = setTimeout(() => {
fn.apply(this, arguments);
}, interval);
};
}
总结
其实函数节流与函数防抖的原理非常简单,巧妙地使用 setTimeout 来存放待执行的函数,这样可以很方便的利用 clearTimeout 在合适的时机来清除待执行的函数。
使用函数节流与函数防抖的目的,在开头的栗子中应该也能看得出来,就是为了节约计算机资源。
Set 和 Map 主要的应用场景在于 数据重组 和 数据储存
Set 是一种叫做集合的数据结构,Map 是一种叫做字典的数据结构
1. 集合(Set)
ES6 新增的一种新的数据结构,类似于数组,但成员是唯一且无序的,没有重复的值。
Set 本身是一种构造函数,用来生成 Set 数据结构。
new Set([iterable])
举个例子:
const s = new Set()
[1, 2, 3, 4, 3, 2, 1].forEach(x => s.add(x))
for (let i of s) {
console.log(i) // 1 2 3 4
}
// 去重数组的重复对象
let arr = [1, 2, 3, 2, 1, 1]
[... new Set(arr)] // [1, 2, 3]
Set 对象允许你储存任何类型的唯一值,无论是原始值或者是对象引用。
向 Set 加入值的时候,不会发生类型转换,所以5和"5"是两个不同的值。Set 内部判断两个值是否不同,使用的算法叫做“Same-value-zero equality”,它类似于精确相等运算符(===),主要的区别是NaN等于自身,而精确相等运算符认为NaN不等于自身。
let set = new Set();
let a = NaN;
let b = NaN;
set.add(a);
set.add(b);
set // Set {NaN}
let set1 = new Set()
set1.add(5)
set1.add('5')
console.log([...set1]) // [5, "5"]
-
Set 实例属性
constructor: 构造函数
-
size:元素数量
let set = new Set([1, 2, 3, 2, 1]) console.log(set.length) // undefined console.log(set.size) // 3
-
Set 实例方法
-
操作方法
add(value):新增,相当于 array里的push
delete(value):存在即删除集合中value
has(value):判断集合中是否存在 value
-
clear():清空集合
let set = new Set() set.add(1).add(2).add(1) set.has(1) // true set.has(3) // false set.delete(1) set.has(1) // falseArray.from方法可以将 Set 结构转为数组const items = new Set([1, 2, 3, 2]) const array = Array.from(items) console.log(array) // [1, 2, 3] // 或 const arr = [...items] console.log(arr) // [1, 2, 3]
-
遍历方法(遍历顺序为插入顺序)
keys():返回一个包含集合中所有键的迭代器
values():返回一个包含集合中所有值得迭代器
entries():返回一个包含Set对象中所有元素得键值对迭代器
-
forEach(callbackFn, thisArg):用于对集合成员执行callbackFn操作,如果提供了 thisArg 参数,回调中的this会是这个参数,没有返回值
let set = new Set([1, 2, 3]) console.log(set.keys()) // SetIterator {1, 2, 3} console.log(set.values()) // SetIterator {1, 2, 3} console.log(set.entries()) // SetIterator {1, 2, 3} for (let item of set.keys()) { console.log(item); } // 1 2 3 for (let item of set.entries()) { console.log(item); } // [1, 1] [2, 2] [3, 3] set.forEach((value, key) => { console.log(key + ' : ' + value) }) // 1 : 1 2 : 2 3 : 3 console.log([...set]) // [1, 2, 3]Set 可默认遍历,默认迭代器生成函数是 values() 方法
Set.prototype[Symbol.iterator] === Set.prototype.values // true所以, Set可以使用 map、filter 方法
let set = new Set([1, 2, 3]) set = new Set([...set].map(item => item * 2)) console.log([...set]) // [2, 4, 6] set = new Set([...set].filter(item => (item >= 4))) console.log([...set]) //[4, 6]因此,Set 很容易实现交集(Intersect)、并集(Union)、差集(Difference)
let set1 = new Set([1, 2, 3]) let set2 = new Set([4, 3, 2]) let intersect = new Set([...set1].filter(value => set2.has(value))) let union = new Set([...set1, ...set2]) let difference = new Set([...set1].filter(value => !set2.has(value))) console.log(intersect) // Set {2, 3} console.log(union) // Set {1, 2, 3, 4} console.log(difference) // Set {1}
-
2. WeakSet
WeakSet 对象允许你将弱引用对象储存在一个集合中
WeakSet 与 Set 的区别:
- WeakSet 只能储存对象引用,不能存放值,而 Set 对象都可以
- WeakSet 对象中储存的对象值都是被弱引用的,即垃圾回收机制不考虑 WeakSet 对该对象的应用,如果没有其他的变量或属性引用这个对象值,则这个对象将会被垃圾回收掉(不考虑该对象还存在于 WeakSet 中),所以,WeakSet 对象里有多少个成员元素,取决于垃圾回收机制有没有运行,运行前后成员个数可能不一致,遍历结束之后,有的成员可能取不到了(被垃圾回收了),WeakSet 对象是无法被遍历的(ES6 规定 WeakSet 不可遍历),也没有办法拿到它包含的所有元素
属性:
-
constructor:构造函数,任何一个具有 Iterable 接口的对象,都可以作参数
const arr = [[1, 2], [3, 4]] const weakset = new WeakSet(arr) console.log(weakset)
方法:
- add(value):在WeakSet 对象中添加一个元素value
- has(value):判断 WeakSet 对象中是否包含value
- delete(value):删除元素 value
- clear():清空所有元素,注意该方法已废弃
var ws = new WeakSet()
var obj = {}
var foo = {}
ws.add(window)
ws.add(obj)
ws.has(window) // true
ws.has(foo) // false
ws.delete(window) // true
ws.has(window) // false
3. 字典(Map)
集合 与 字典 的区别:
- 共同点:集合、字典 可以储存不重复的值
- 不同点:集合 是以 [value, value]的形式储存元素,字典 是以 [key, value] 的形式储存
const m = new Map()
const o = {p: 'haha'}
m.set(o, 'content')
m.get(o) // content
m.has(o) // true
m.delete(o) // true
m.has(o) // false
任何具有 Iterator 接口、且每个成员都是一个双元素的数组的数据结构都可以当作Map构造函数的参数,例如:
const set = new Set([
['foo', 1],
['bar', 2]
]);
const m1 = new Map(set);
m1.get('foo') // 1
const m2 = new Map([['baz', 3]]);
const m3 = new Map(m2);
m3.get('baz') // 3
如果读取一个未知的键,则返回undefined。
new Map().get('asfddfsasadf')
// undefined
注意,只有对同一个对象的引用,Map 结构才将其视为同一个键。这一点要非常小心。
const map = new Map();
map.set(['a'], 555);
map.get(['a']) // undefined
上面代码的set和get方法,表面是针对同一个键,但实际上这是两个值,内存地址是不一样的,因此get方法无法读取该键,返回undefined。
由上可知,Map 的键实际上是跟内存地址绑定的,只要内存地址不一样,就视为两个键。这就解决了同名属性碰撞(clash)的问题,我们扩展别人的库的时候,如果使用对象作为键名,就不用担心自己的属性与原作者的属性同名。
如果 Map 的键是一个简单类型的值(数字、字符串、布尔值),则只要两个值严格相等,Map 将其视为一个键,比如0和-0就是一个键,布尔值true和字符串true则是两个不同的键。另外,undefined和null也是两个不同的键。虽然NaN不严格相等于自身,但 Map 将其视为同一个键。
let map = new Map();
map.set(-0, 123);
map.get(+0) // 123
map.set(true, 1);
map.set('true', 2);
map.get(true) // 1
map.set(undefined, 3);
map.set(null, 4);
map.get(undefined) // 3
map.set(NaN, 123);
map.get(NaN) // 123
Map 的属性及方法
属性:
constructor:构造函数
-
size:返回字典中所包含的元素个数
const map = new Map([ ['name', 'An'], ['des', 'JS'] ]); map.size // 2
操作方法:
- set(key, value):向字典中添加新元素
- get(key):通过键查找特定的数值并返回
- has(key):判断字典中是否存在键key
- delete(key):通过键 key 从字典中移除对应的数据
- clear():将这个字典中的所有元素删除
遍历方法
- Keys():将字典中包含的所有键名以迭代器形式返回
- values():将字典中包含的所有数值以迭代器形式返回
- entries():返回所有成员的迭代器
- forEach():遍历字典的所有成员
const map = new Map([
['name', 'An'],
['des', 'JS']
]);
console.log(map.entries()) // MapIterator {"name" => "An", "des" => "JS"}
console.log(map.keys()) // MapIterator {"name", "des"}
Map 结构的默认遍历器接口(Symbol.iterator属性),就是entries方法。
map[Symbol.iterator] === map.entries
// true
Map 结构转为数组结构,比较快速的方法是使用扩展运算符(...)。
对于 forEach ,看一个例子
const reporter = {
report: function(key, value) {
console.log("Key: %s, Value: %s", key, value);
}
};
let map = new Map([
['name', 'An'],
['des', 'JS']
])
map.forEach(function(value, key, map) {
this.report(key, value);
}, reporter);
// Key: name, Value: An
// Key: des, Value: JS
在这个例子中, forEach 方法的回调函数的 this,就指向 reporter
与其他数据结构的相互转换
-
Map 转 Array
const map = new Map([[1, 1], [2, 2], [3, 3]]) console.log([...map]) // [[1, 1], [2, 2], [3, 3]] -
Array 转 Map
const map = new Map([[1, 1], [2, 2], [3, 3]]) console.log(map) // Map {1 => 1, 2 => 2, 3 => 3} -
Map 转 Object
因为 Object 的键名都为字符串,而Map 的键名为对象,所以转换的时候会把非字符串键名转换为字符串键名。
function mapToObj(map) { let obj = Object.create(null) for (let [key, value] of map) { obj[key] = value } return obj } const map = new Map().set('name', 'An').set('des', 'JS') mapToObj(map) // {name: "An", des: "JS"} -
Object 转 Map
function objToMap(obj) { let map = new Map() for (let key of Object.keys(obj)) { map.set(key, obj[key]) } return map } objToMap({'name': 'An', 'des': 'JS'}) // Map {"name" => "An", "des" => "JS"} -
Map 转 JSON
function mapToJson(map) { return JSON.stringify([...map]) } let map = new Map().set('name', 'An').set('des', 'JS') mapToJson(map) // [["name","An"],["des","JS"]] -
JSON 转 Map
function jsonToStrMap(jsonStr) { return objToMap(JSON.parse(jsonStr)); } jsonToStrMap('{"name": "An", "des": "JS"}') // Map {"name" => "An", "des" => "JS"}
4. WeakMap
WeakMap 对象是一组键值对的集合,其中的键是弱引用对象,而值可以是任意。
注意,WeakMap 弱引用的只是键名,而不是键值。键值依然是正常引用。
WeakMap 中,每个键对自己所引用对象的引用都是弱引用,在没有其他引用和该键引用同一对象,这个对象将会被垃圾回收(相应的key则变成无效的),所以,WeakMap 的 key 是不可枚举的。
属性:
- constructor:构造函数
方法:
- has(key):判断是否有 key 关联对象
- get(key):返回key关联对象(没有则则返回 undefined)
- set(key):设置一组key关联对象
- delete(key):移除 key 的关联对象
let myElement = document.getElementById('logo');
let myWeakmap = new WeakMap();
myWeakmap.set(myElement, {timesClicked: 0});
myElement.addEventListener('click', function() {
let logoData = myWeakmap.get(myElement);
logoData.timesClicked++;
}, false);
介绍下Set_Map_WeakSet和WeakMap的区别
5. 总结
- Set
- 成员唯一、无序且不重复
- [value, value],键值与键名是一致的(或者说只有键值,没有键名)
- 可以遍历,方法有:add、delete、has
- WeakSet
- 成员都是对象
- 成员都是弱引用,可以被垃圾回收机制回收,可以用来保存DOM节点,不容易造成内存泄漏
- 不能遍历,方法有add、delete、has
- Map
- 本质上是键值对的集合,类似集合
- 可以遍历,方法很多可以跟各种数据格式转换
- WeakMap
- 只接受对象作为键名(null除外),不接受其他类型的值作为键名
- 键名是弱引用,键值可以是任意的,键名所指向的对象可以被垃圾回收,此时键名是无效的
- 不能遍历,方法有get、set、has、delete
6. 扩展:Object与Set、Map
-
Object 与 Set
// Object const properties1 = { 'width': 1, 'height': 1 } console.log(properties1['width']? true: false) // true // Set const properties2 = new Set() properties2.add('width') properties2.add('height') console.log(properties2.has('width')) // true Object 与 Map
ES6 WeakMap和WeakSet的使用场景
JS 中的对象(Object),本质上是键值对的集合(hash 结构)
const data = {};
const element = document.getElementsByClassName('App');
data[element] = 'metadata';
console.log(data['[object HTMLCollection]']) // "metadata"
但当以一个DOM节点作为对象 data 的键,对象会被自动转化为字符串[Object HTMLCollection],所以说,Object 结构提供了 字符串-值 对应,Map则提供了 值-值 的对应
本
JavaScript垃圾回收是一种内存管理技术。在这种技术中,不再被引用的对象会被自动删除,而与其相关的资源也会被一同回收。
Map和Set中对象的引用都是强类型化的,并不会允许垃圾回收。这样一来,如果Map和Set中引用了不再需要的大型对象,如已经从DOM树中删除的DOM元素,那么其回收代价是昂贵的。
为了解决这个问题,ES6还引入了另外两种新的数据结构,即称为WeakMap和WeakSet的弱集合。这些集合之所以是“弱的”,是因为它们允许从内存中清除不再需要的被这些集合所引用的对象。
使用场景:储存 DOM 节点,而不用担心这些节点从文档移除时,会引发内存泄漏。
有以下 3 个判断数组的方法,请分别介绍它们之间的区别和优劣
1. Object.prototype.toString.call()
每一个继承 Object 的对象都有 toString 方法,如果 toString 方法没有重写的话,会返回 [Object type],其中 type 为对象的类型。但当除了 Object 类型的对象外,其他类型直接使用 toString 方法时,会直接返回都是内容的字符串,所以我们需要使用call或者apply方法来改变toString方法的执行上下文。
const an = ['Hello','An'];
an.toString(); // "Hello,An"
Object.prototype.toString.call(an); // "[object Array]"
这种方法对于所有基本的数据类型都能进行判断,即使是 null 和 undefined 。
Object.prototype.toString.call('An') // "[object String]"
Object.prototype.toString.call(1) // "[object Number]"
Object.prototype.toString.call(Symbol(1)) // "[object Symbol]"
Object.prototype.toString.call(null) // "[object Null]"
Object.prototype.toString.call(undefined) // "[object Undefined]"
Object.prototype.toString.call(function(){}) // "[object Function]"
Object.prototype.toString.call({name: 'An'}) // "[object Object]"
Object.prototype.toString.call() 常用于判断浏览器内置对象时。
更多实现可见 谈谈 Object.prototype.toString
2. instanceof
instanceof 的内部机制是通过判断对象的原型链中是不是能找到类型的 prototype。
使用 instanceof判断一个对象是否为数组,instanceof 会判断这个对象的原型链上是否会找到对应的 Array 的原型,找到返回 true,否则返回 false。
[] instanceof Array; // true
但 instanceof 只能用来判断对象类型,原始类型不可以。并且所有对象类型 instanceof Object 都是 true。
[] instanceof Object; // true
3. Array.isArray()
功能:用来判断对象是否为数组
-
Array.isArray()与Object.prototype.toString.call()Array.isArray()是ES5新增的方法,当不存在Array.isArray(),可以用Object.prototype.toString.call()实现。if (!Array.isArray) { Array.isArray = function(arg) { return Object.prototype.toString.call(arg) === '[object Array]'; }; }
ES5/ES6 的定义对象的区别
-
class声明会提升,但不会初始化赋值。Foo进入暂时性死区,类似于let、const声明变量。
const bar = new Bar(); // it's ok
function Bar() {
this.bar = 42;
}
const foo = new Foo(); // ReferenceError: Foo is not defined
class Foo {
constructor() {
this.foo = 42;
}
}
-
class声明内部会启用严格模式。
// 引用一个未声明的变量
function Bar() {
baz = 42; // it's ok
}
const bar = new Bar();
class Foo {
constructor() {
fol = 42; // ReferenceError: fol is not defined
}
}
const foo = new Foo();
class` 的所有方法(包括静态方法和实例方法)都是不可枚举的。
// 引用一个未声明的变量
function Bar() {
this.bar = 42;
}
Bar.answer = function() {
return 42;
};
Bar.prototype.print = function() {
console.log(this.bar);
};
const barKeys = Object.keys(Bar); // ['answer']
const barProtoKeys = Object.keys(Bar.prototype); // ['print']
class Foo {
constructor() {
this.foo = 42;
}
static answer() {
return 42;
}
print() {
console.log(this.foo);
}
}
const fooKeys = Object.keys(Foo); // []
const fooProtoKeys = Object.keys(Foo.prototype); // []
-
class的所有方法(包括静态方法和实例方法)都没有原型对象 prototype,所以也没有[[construct]],不能使用new来调用。
function Bar() {
this.bar = 42;
}
Bar.prototype.print = function() {
console.log(this.bar);
};
const bar = new Bar();
const barPrint = new bar.print(); // it's ok
class Foo {
constructor() {
this.foo = 42;
}
print() {
console.log(this.foo);
}
}
const foo = new Foo();
const fooPrint = new foo.print(); // TypeError: foo.print is not a constructor
- 必须使用
new调用class。
function Bar() {
this.bar = 42;
}
const bar = Bar(); // it's ok
class Foo {
constructor() {
this.foo = 42;
}
}
const foo = Foo(); // TypeError: Class constructor Foo cannot be invoked without 'new'
-
class内部无法重写类名。
function Bar() {
Bar = 'Baz'; // it's ok
this.bar = 42;
}
const bar = new Bar();
// Bar: 'Baz'
// bar: Bar {bar: 42}
class Foo {
constructor() {
this.foo = 42;
Foo = 'Fol'; // TypeError: Assignment to constant variable
}
}
const foo = new Foo();
Foo = 'Fol'; // it's ok
全局作用域中,用 const 和 let 声明的变量不在 window 上,那到底在哪里?如何去获取?
在ES5中,顶层对象的属性和全局变量是等价的,var 命令和 function 命令声明的全局变量,自然也是顶层对象。
var a = 12;
function f(){};
console.log(window.a); // 12
console.log(window.f); // f(){}
但ES6规定,var 命令和 function 命令声明的全局变量,依旧是顶层对象的属性,但 let命令、const命令、class命令声明的全局变量,不属于顶层对象的属性。
let aa = 1;
const bb = 2;
console.log(window.aa); // undefined
console.log(window.bb); // undefined
在哪里?怎么获取?通过在设置断点,看看浏览器是怎么处理的:
通过上图也可以看到,在全局作用域中,用 let 和 const 声明的全局变量并没有在全局对象中,只是一个块级作用域(Script)中
怎么获取?在定义变量的块级作用域中就能获取啊,既然不属于顶层对象,那就不加 window(global)呗。
let aa = 1;
const bb = 2;
console.log(aa); // 1
console.log(bb); // 2
const和let会生成块级作用域,可以理解为
let a = 10;
const b = 20;
相当于:
(function(){
var a = 10;
var b = 20;
})()
ES5没有块级作用域的概念,只有函数作用域,可以近似理解成这样。 所以外层window必然无法访问。
为何会出现浏览器兼容问题
- 同一产品,版本越老 bug 越多
- 同一产品,版本越新,功能越多
- 不同产品,不同标准,不同实现方式
处理兼容问题的思路
- 要不要做
- 产品的角度(产品的受众、受众的浏览器比例、效果优先还是基本功能优先)
- 成本的角度 (有无必要做某件事)
2.做到什么程度
- 让哪些浏览器支持哪些效果
3..如何做
- 根据兼容需求选择技术框架/库(jquery)
- 根据兼容需求选择兼容工具(html5shiv.js、respond.js、css reset、normalize.css、Modernizr)
- 条件注释、CSS Hack、js 能力检测做一些修补
- 渐进增强(progressive enhancement): 针对低版本浏览器进行构建页面,保证最基本的功能,然后再针对高级浏览器进行效果、交互等改进和追加功能达到更好的用户体验
- 优雅降级 (graceful degradation): 一开始就构建完整的功能,然后再针对低版本浏览器进行兼容。
前端性能优化
- 减少 HTTP 请求
- 减少 DOM 操作
- 避免不必要的重绘与重排
- 优化 CSS 选择器(从右向左匹配)
- CSS/JS minify,减少文件体积
- 开启 Gzip 压缩
- 将 CSS 放到顶部,JavaScript 放到尾部
- 压缩图片以及使用 CSS Sprite
- 使用 CDN 加速,适当进行文件缓存
- 合理控制 cookie 大小(每次请求都会包含 cookie)
XSS
XSS是什么
XSS是一种经常出现在web应用中的计算机安全漏洞,它允许恶意web用户将代码植入到提供给其它用户使用的页面中。
比如这些代码包括HTML代码和客户端脚本。攻击者利用XSS漏洞旁路掉访问控制——例如同源策略(same origin policy)。
这种类型的漏洞由于被黑客用来编写危害性更大的网络钓鱼(Phishing)攻击而变得广为人知。
对于跨站脚本攻击,黑客界共识是:跨站脚本攻击是新型的“缓冲区溢出攻击“,而JavaScript是新型的“ShellCode”。
示例:
特点
能注入恶意的HTML/JavaScript代码到用户浏览的网页上,从而达到Cookie资料窃取、会话劫持、钓鱼欺骗等攻击。
<攻击代码不一定(非要)在 中>
原因
Web浏览器本身的设计不安全。浏览器能解析和执行JS等代码,但是不会判断该数据和程序代码是否恶意。
输入和输出是Web应用程序最基本的交互,而且网站的交互功能越来越丰富。如果在这过程中没有做好安全防护,很容易会出现XSS漏洞。
程序员水平参差不齐,而且大都没有过正规的安全培训,没有相关的安全意识。
XSS攻击手段灵活多变。
危害
- 盗取各类用户帐号,如机器登录帐号、用户网银帐号、各类管理员帐号
- 控制企业数据,包括读取、篡改、添加、删除企业敏感数据的能力
- 盗窃企业重要的具有商业价值的资料
- 非法转账
- 强制发送电子邮件
- 网站挂马
- 控制受害者机器向其它网站发起攻击
如何防范
- 将重要的cookie标记为http only, 这样的话Javascript 中的document.cookie语句就不能获取到cookie了.
- 表单数据规定值的类型,例如:年龄应为只能为int、name只能为字母数字组合。。。。
- 对数据进行Html Encode 处理
- 过滤或移除特殊的Html标签, 例如: