深刻理解Tensor的概念及其常见的操作_以Pytorch框架为例
深刻理解Tensor的概念/结构及其常见的属性/操作_以Pytorch框架为例
- Tensor的几个重要的属性/方法
-
- 1. device:
- 2. data_ptr()
- 3. dtype
- 4. storage()
- 5. is_contiguous()
- Tensor的操作/manipulation
-
- 常用的API
- Tensor的数据结构
- 总结
- References
Tensor的几个重要的属性/方法
先来看一个例子:
# -*- coding: utf-8 -*-
import torch as th
data = th.tensor([[1,2], [3,4]])
print(data.device) # cpu
print(data.storage()) #1.0 2.0 3.0 4.0 [torch.FloatStorage of size 4]
print(data.data_ptr()) # 2405763261376
print(data.size()) # torch.Size([2, 2])
print(data.shape) # torch.Size([2, 2])
print(data.dtype) # torch.float32
print(data.is_contiguous()) # True
print(data_t.is_contiguous()) # False
1. device:
指定了Tensor该计算机上存放的位置 (默认为CPU的RAM)
CPU/GPU切换操作:
通过tensor.to()方法实现,
data_gpu = th.tensor([[1,2], [3,4]], device='cuda') # 创建时指定存放到GPU RAM
data_gpu2 = data.to(device='cuda') # 将CPU上的Tensor拷贝到GPU上
data_gpu3 = data.to(device='cuda:0') # 将CPU上的Tensor拷贝到指定GPU上
data2 = data_gpu2.to(device='cpu') # 将GPU上的Tensor拷贝到CPU上
简化的方式:
# tensor.cpu() == tensor.to(device='cpu')
# tensor.gpu() == tensor.to(device='cuda')
注: 一般情况下, Tensor初始加载后在CPU上, 然后将其拷贝到GPU进行运算 (得出的运算结果也在GPU上), 运算完成后再将其拷贝到CPU上。
2. data_ptr()
返回tensor首元素的内存地址, 常用来判断两个Tensor是不是共享内存
Example:
data_t = data.t() # Transpose
print(data.data_ptr() == data_t.data_ptr()) # True
(因为Transpose操作只是改变了stride信息,data_t 和data只想同一个memory)
3. dtype
指定了Tensor的数据类型 (默认为:torch.float32)
Tensor dtype的切换:
data2 = th.ones(4, 2, dtype=th.float32) # 使用create-fucntion创建时指定dtype
data_float32 = th.tensor([[1,2], [3,4]]).double() #强行cast到指定类型
data_float32_2 = th.tensor([[1,2], [3,4]]).to(th.double) # 通过to (更加general的方法)
4. storage()
storage是任何数值数据的1D-array, storage()返回任何n-DTensor的storage (总是1D array).
Tensor与Storage之间的关系: Tensor可以堪称是某个Storage的视图View, 多个Tensor可能share同一个storage。 为了对storage进行索引需要借助一些信息:size, storage offset, 和stride :
storage offset:storage中与相应Tensor中的第一个元素相对应的index;
stride: storage中每个维度上获取的下一个元素需要跳过的step;
size: 每个dimension的元素个数
由于在创建Tensor时, 默认的storage是按照Tensor的row展开的,总的来说:访问Tensor[i,j ]实际上就是在访问storage[storage offset+storage[0] * i + storage[1] * j ]
示意图:

注: 关于storage与Tensor必须要提的就是浅拷贝与深拷贝, 写代码时一定要清楚操作的是不是同一个storage, 否则会引起错误。如果想要深拷贝,可以使用clone方法, 如下:
data_clone = data.clone()
print(data.data_ptr == data_clone.data_ptr) # False
5. is_contiguous()
判断Tensor按行展开后的顺序与其storage的顺序是否一致
之前在创建Tensor时, 默认的storage是按照Tensor的row展开的,但是一些操作(如,transpose)会改变Tensor,这就会导致当前Tensor按行展开后的顺序与原始的storage不一致。不一致的话,在使用view等操作时会报错。
如何如何让不一致变为一致呢?(即data_t的is_contiguous()返回True)
data_t_contig = data_t.contiguous()
print(data_t_contig.is_contiguous())
print(data_t_contig.storage())
print(data.data_ptr == data_t_contig.data_ptr)
Output:

可以看到data_t_contig 的is_contiguous()==true, contiguous()方法会导致重新分类memory.
Tensor的操作/manipulation
可以向操作ndarray一样操作Tensor, 因为Tensor完全支持高级检索。 特别值得一提的是掩码技巧mask的使用。
# -*- coding: utf-8 -*-
import numpy as np
import torch as th
data = th.tensor([[1, 2, 3], [4, 5, 6]])
print(data[0] == data[0, :])
print(data[:, 1])
print(data[:, :-1])
mask = np.array([1, 0, 1], dtype=bool)
print(data[:, mask])
Output:

常用的API
Transpose:
data_t = data.transpose(0, 1)
data_t2 = th.transpose(data, 0, 1)
print(data_t.shape, data_t.shape == data_t2.shape)
output:
![]()
注: 调用这些API有两种方式:
(1)torch模块下调用相应方式
(2)作为具体Tensor object的一个方法来调用
Tensor的数据结构
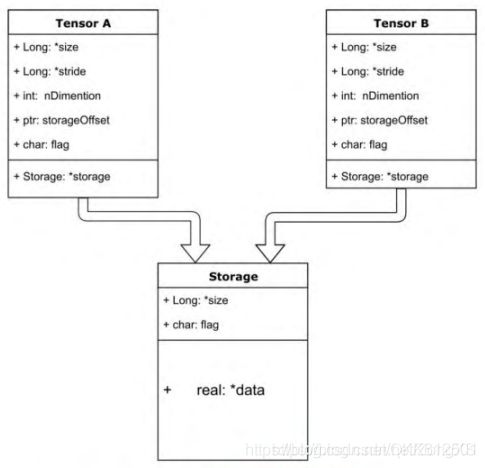
至此,相信对Tensor的结构应该有所了解,如下图:
tensor的结构分为头信息区(Tensor)和存储区(Storage),其中:
(1) 信息区主要保存着:tensor的形状(size)、维度(nDimension)、数据类型(type)、步长(stride)、偏移(storageOffset)等信息,因此信息区元素占用内存较少。
(2) 真正的数据则保存成连续数组,位于存储区(即CPU的RAM或者GPU RAM), 主要内存占用则取决于tensor中元素的数目,也即存储区的大小。
总结
有时间再续吧。。。。。
References
1.https://blog.csdn.net/ZongXS/article/details/105680541