1、查找数据源,获取网址
携程旅游网址
2、导入需要的模块
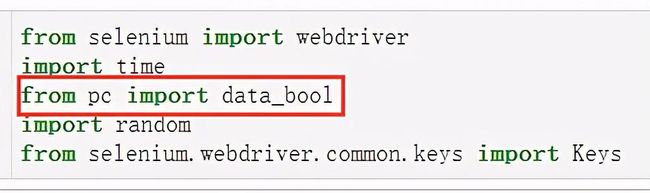
from selenium import webdriver
import time
from pc import data_bool
import random
from selenium.webdriver.common.keys import Keys
3、实例化对象
bool_=data_bool() #实例化
4、写入需要键入的地区,省份
diqu=['北京','上海','深圳','成都','广州','杭州','三亚','海口',
'乌鲁木齐','拉萨','武汉','南京','西安','南疆','大理','香格里拉',
'西双版纳','五台山','哈尔滨','甘肃','浙江','天津','江苏','福建',
'重庆','湖南','辽宁','山东','内蒙古','安徽','四川','湖北','海南',
'河北','青海','陕西','江西','宁夏','云南','吉林','河南','广西',
'黑龙江','山西','新疆','贵州','西藏','云南'] # 需要键入的地区 全国省份集合
5、设置函数,用异常捕获处理
查看参数数据

def result(driver):
#获取父级元素
parent=driver.find_element_by_class_name('main_col')
#获取景点等多信息
try:
str_introduce=parent.find_elements_by_css_selector('p.list_product_title')
except:
str_introduce=[]
print('头部获取到空值')
#获取跟团游或地点信息
try:
str_product=parent.find_elements_by_css_selector('p.list_product_tip')
except:
str_product=[]
print('跟团游获取到空值')
#获取列表字段的介绍信息
try:
list_box=parent.find_elements_by_css_selector('list_label_box')
list_box_item=[]
for i in list_box:
list_box_item.append(i.find_elements_by_css_selector('span'))
except:
list_box_item=[]
print('列表获取空值')
#获取供应商信息
try:
list_retail=parent.find_elements_by_css_selector('p.list_product_retail')
except:
list_retail=[]
print('供应商得到空值')
#获取评分信息
try:
str_grade=parent.find_elements_by_css_selector('p.list_change_grade')
except:
str_grade=[]
print('评分获得空值')
#获取出行人数信息
try:
str_number=parent.find_elements_by_css_selector('div.list_change_one')
except:
str_number=[]
print('出游人数获的空值')
#获取点评数量信息
try:
str_remark=parent.find_elements_by_css_selector('div.list_change_two')
except:
str_remark=[]
print('点评数量获得空值')
#获取价格信息
try:
str_price=parent.find_elements_by_css_selector('span.list_sr_price')
except:
str_price=[]
print('价格获取到空值')
#添加主要数据
try:
rank=[]
#以供应商的长度做位循环范围
for i in range(len(list_retail)):
box=[]
#景点信息
try:
introduce=str_introduce[i].text
except:
introduce='无'
#供应商
try:
retail=list_retail[i].text
except:
retail='无'
#评分信息
try:
grade=str_grade[i].text
except:
grade='0分'
#出行人数
try:
number=str_number[i].text
except:
number='0人'
#点评人数
try:
remark=str_remark[i].text
except:
remark='0条'
#价格
try:
price=str_price[i].text
except:
price='¥0元'
try:
#每一个 list_box_item
item=list_box_item[i]
#标签数据添加
for j in item:
box.append(j.text)
#添加到rank列表
except:
box=[]
rank.append([introduce,retail,grade,number,remark,price,box])
bool_.MemoryCsv(rank,'携程旅游数据.csv','a')
parent.find_element_by_css_selector('a.down').click()
except:
parent.find_element_by_css_selector('a.down').click()
price('数据丢失了\n')
6、定义函数抓取第一页
def range_(begin,end,driver): #三个参数(开始,停止,driver获取的信息)
for i in range(begin,end):
result(driver) #传入函数
time.sleep(random.randint(20,25)) #随机睡眠20-25秒
print(f'第{i}页') #打印页数
7、写入点击事件,自动打开网页查找携程
def t(x,x1,x2):
for index,i in enumerate(x[x1:x2]):
driver=webdriver.Chrome()
time.sleep(3)
driver.get('https://vacations.ctrip.com/?startcity=1&salecity=1&cityname=%E5%8C%97%E4%BA%AC')
input_tag=driver.find_element_by_class_name('search_txt') #查找输入
input_tag.send_keys(i)
time.sleep(1)
input_tag.send_keys(Keys.ENTER) #回车
time.sleep(3)
range_(0,35,driver)
driver.close()
print(f'{i}爬取完毕')
time.sleep(3)
8、导入多线程使用的模块,写入多线程
import threading
t1=threading.Thread(target=t,args=(diqu,11,23))
t2=threading.Thread(target=t,args=(diqu,23,31))
t3=threading.Thread(target=t,args=(diqu,31,36))
t1.start()
t2.start()
t3.start()
9、pc是一个py文件
里面是获取头部和存储的代码
import requests
import requests
import chardet
import random
import csv
from openpyxl import Workbook
from pandas import DataFrame,Series
class data_bool():
def __init__(self):
pass
def get_html(self, url): # 获取html的基本结构
# 获取头部
user_agent = [
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36',
"Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50"
]
headers = {'User-Agent': random.choice(user_agent)}
# 获取网址
response = requests.get(url=url, headers=headers)
# 获取编码
encoding = chardet.detect(response.content)
# 设置编码
response.encoding ='utf-8' # 获取编码值
return response
# 存储csv格式 只是支持二维列表[[],[]],支持多线程
def MemoryCsv(self, data: list, fileName: str, mode='w'):
with open(fileName, mode=mode, encoding='utf-8', newline='')as f:
csvfile = csv.writer(f)
# 写入data
for each in data:
csvfile.writerow(each)
print(fileName, "存储成功")
# 存储Excel 格式的函数 不支持多线程
def MemoryExcel(self, data, fileName):
wb = Workbook()
sheet = wb.active
for each in data:
sheet.append(each)
wb.save(fileName)
print(fileName, '存储成功')
def Memonry_pandas_csv(self,data:list,fileName,mode='w'):
DataFrame(data).to_csv(fileName,mode=mode,header=False,index=False)
你学会了吗?遇到问题可以点击下方蓝色字体可交流,可解答!
python免费学习资料以及群交流解答点击即可加入