用一行Python代码实现按字符串内数字大小排列字符串顺序

熟悉编程的朋友应该不难理解,为什么字符串排序"10"会排在"2"的前面。因为字符串大小比较是对各字符的编码值逐个进行比较,“1”<“2”,所以"10"<“2”。
不过这不是本文想要达到的目标,本篇文章会用一行代码,让文本中出现的(任意多组)数字序号可以按照数字顺序进行排序。
〇、背景
最近在爬虫某漫画网站,帖子标题一般是这样的格式:
[作者] 标题标题 1 [55P]
[作者] 标题标题 2 [64P]
[作者] 标题标题 3 [75P]
……
[作者] 标题标题 8 [47P]
[作者] 标题标题 9 [44P]
[作者] 标题标题 10 [50P]
[作者] 标题标题 11 [44P]
[作者] 标题标题 12 [43P]
[作者] 标题标题 13 [44P]
……
我按照每篇帖子的标题作为文件夹名,将帖子里的所有图片下载到了对应的目录。
本地保存的结果是这样的:

在资源管理器中,这些数字顺序的文件夹都得到了“正确的”排序。
但是因为项目需求,我希望在程序中处理这些文件夹时,却出现了文章一开头出现的问题——10、11、12全都跑到了1的后面、2的前面,这是不符合我的预期的。
[作者] 标题标题 1 [55P]
[作者] 标题标题 10 [50P]
[作者] 标题标题 11 [44P]
[作者] 标题标题 12 [43P]
……
[作者] 标题标题 19 [36P]
[作者] 标题标题 2 [64P]
[作者] 标题标题 20 [33P]
[作者] 标题标题 21 [36P]
[作者] 标题标题 22 [33P]
[作者] 标题标题 23 [35P]
……
一、正则取出序号位置进行排序
如果文章的序号始终出现在同样的位置,那么用正则很容易将这个位置的序号“取出来”,转换为数字类型,然后利用sorted函数的第2个参数key进行排序即可。
比如本例可以用这样的代码进行排序:
folders = sorted(folders, key=lambda s: int(s.split()[-2]))
但是这样的算法并不够“干净”也不够“通用”,比如当文本中没有数字就会报错,或者数字不在规则设定的位置、或者有多组数字,也无法正确排序。
关键是Windows的资源管理器轻易就能做到的事情,为什么Python的排序就是不行呢?

二、微软的排序策略
生成测试样例代码:
for i in range(1, 20, 4):
for j in range(1, 20, 4):
with open(('abc%dxyz%d_extension'%(i, j))[:12], 'w'):
pass
在文件浏览器中查看排序效果,文件名可以按照数字大小进行排序,包含多组数字也能正确排序:

更加惊人地,我尝试使用不同的ASCII码生成文件名,查看排序策略,其实微软实现了更加复杂的排序方式:
生成测试样例代码:
for i in range(1, 256):
try:
with open(chr(i), 'w'):
pass
except:
pass
微软的排序策略:

微软的排序囊括了¼字符、注音字符、拉丁文等特殊字符,也按照了一定规律进行排序。
(然而却有人吐槽这一点,甚至希望把这个“Bug”去掉: Windows按名称排序问题)
那么微软是如何实现排序逻辑的呢?一开始我考虑是不是将0-9的编码定义得比其他字符优先级更低,但是这样可以实现"11">“1a”,却不能解释为什么"a1">“11”。

因此,微软一定是“贴心”地提取了文件名中出现的所有数字,然后再按照从左到右的序列依次排序,最终得到排序结果。
(然而我看到这篇帖子,才发现我又重复研究轮子了:Java实现Windows中的文件名排序)![]()
三、Python实现排序
既然没有捷径可走,那就想办法把所有的“数字”和“非数字字符”(不仅是英文)全部提出来。
比如目标字符串,目标达到这样的效果:
'he11owor1d' -> ['he', 11, 'owor', 1, 'd']
可以使用正则表达式进行匹配,不过正则表达式中,"\d+"只能匹配数字,"\D+"只能匹配非数字,"(\D+)(\d+)"可以取出所有的数字和非数字,但是却匹配不到字符串首的数字和字符串尾的非数字。
为了解决这一点,手动在串首和串尾分别增加一个英文和数字,就可以让原本字符串内的所有内容全部符合正则规则并匹配到,最后再删掉头尾就可以了。
(当然,头尾统一增加一个字符并不会影响排序顺序,所以这两个字符也可以不删)
正则表达式匹配:
s1 = re.findall(r'(\D+)(\d+)', 'a' + s + '0')
输出:
[('ahe', '11'), ('owor', '1'), ('d', '0')]
返回的结果是二维数组,通过sum函数组装成一维数组:
s2 = sum(s1, ())
输出:
('ahe', '11', 'owor', '1', 'd', '0')
这个很秀的操作是使用了sum函数的第2个控制参数:
sum(iterable, start=0, /)
Return the sum of a ‘start’ value (default: 0) plus an iterable of numbers
When the iterable is empty, return the start value.
This function is intended specifically for use with numeric values and may reject non-numeric types.
将数组中表示数字的字符串转化成数字,写成列表递推式可以用一行代码写出来:
s3 = [int(s) if s.isdigit() else s for s in s2]
输出:
['ahe', 11, 'owor', 1, 'd', 0]
接着将这个数组返回,作为sorted函数的第2个参数key的返回作为排序判断。
当对列表内的字符串进行排序时,会按照传入key的排序函数进行计算,分别计算得到的结果(每一个字符串对应一个数组),对结果进行排序。
数组的比对就是各元素逐一比较大小了,这样可以得到对字符串预期的排序结果。
包含生成测试样本的代码:
import os
import re
# 生成测试数据集
for i in range(1, 20, 4):
for j in range(1, 20, 4):
with open(('abc%dxyz%d_extension'%(i, j))[:12], 'w'):
pass
# 自定义排序函数
def filenamesort(s):
s1 = re.findall(r'(\D+)(\d+)', 'a' + s + '0')
s2 = sum(s1, ())
s3 = [int(s) if s.isdigit() else s for s in s2]
return s3
# 排序函数对含有数字的字符串的计算结果测试
s = 'he11owor1d'
print(filenamesort(s))
# 原始顺序和自定义排序结果
print(sorted(os.listdir()))
print(sorted(os.listdir(), key=filenamesort))
生成样本和输出排序结果:
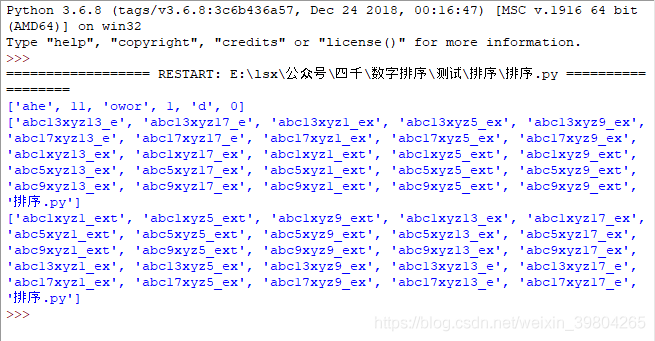
第2段是Python对列表的默认排序,第3段是使用我的自定义排序结果,可以看到结果符合预期。
但是微软做到的对¼和注音标记等符号也进行了排序,这个就不在我的需求范围内了。![]()
四、一行代码排序
当然,你还可以把这些代码继续简化,用一行代码来写出来:
print(sorted(os.listdir(), key=lambda s: [int(s) if s.isdigit() else s for s in sum(re.findall(r'(\D+)(\d+)', 'a'+s+'0'), ())]))
嗯,所以我不是标题党。![]()
INF、后记
后来经小小明大佬的指点,代码还可以进一步简化:
print(sorted(os.listdir(), key=lambda s: [int(s) if s.isdigit() else s for s in re.findall(r'\D+|\d+', 'a'+s+'0')]))
INF、后后记
后来又发现可以再简化短一点:
print(sorted(os.listdir(), key=lambda s: sum(((s, int(n)) for s, n in re.findall(r'(\D+)(\d+)', 'a%s0'%s)), ())))
这个方法减少了n次str.isdigit()函数的运算,所以理论上还会更快一些。
另一方面为了增加代码的复用性,还可以写成这样的两行:
fns = lambda s: sum(((s,int(n))for s,n in re.findall('(\D+)(\d+)','a%s0'%s)),())
print(sorted(os.listdir(), key=fns))