20面试官21-04-17
面试官:说说你对vue的理解?
Vue.js(/vjuː/,或简称为Vue)是一个用于创建用户界面的开源JavaScript框架,也是一个创建单页应用的Web应用框架。2016年一项针对JavaScript的调查表明,Vue有着89%的开发者满意度。在GitHub上,该项目平均每天能收获95颗星,为Github有史以来星标数第3多的项目同时也是一款流行的JavaScript前端框架,旨在更好地组织与简化Web开发。Vue所关注的核心是MVC模式中的视图层,同时,它也能方便地获取数据更新,并通过组件内部特定的方法实现视图与模型的交互PS: Vue作者尤雨溪是在为AngularJS工作之后开发出了这一框架。他声称自己的思路是提取Angular中为自己所喜欢的部分,构建出一款相当轻量的框架最早发布于2014年2月
ue核心特性
数据驱动(MVVM)
MVVM表示的是 Model-View-ViewModel
Model:模型层,负责处理业务逻辑以及和服务器端进行交互
View:视图层:负责将数据模型转化为UI展示出来,可以简单的理解为HTML页面
ViewModel:视图模型层,用来连接Model和View,是Model和View之间的通信桥梁
在这里插入图片描述

组件化
1.什么是组件化一句话来说就是把图形、非图形的各种逻辑均抽象为一个统一的概念(组件)来实现开发的模式,在Vue中每一个.vue文件都可以视为一个组件2.组件化的优势
降低整个系统的耦合度,在保持接口不变的情况下,我们可以替换不同的组件快速完成需求,例如输入框,可以替换为日历、时间、范围等组件作具体的实现
调试方便,由于整个系统是通过组件组合起来的,在出现问题的时候,可以用排除法直接移除组件,或者根据报错的组件快速定位问题,之所以能够快速定位,是因为每个组件之间低耦合,职责单一,所以逻辑会比分析整个系统要简单
提高可维护性,由于每个组件的职责单一,并且组件在系统中是被复用的,所以对代码进行优化可获得系统的整体升级
面试官:说说你对双向绑定的理解?

什么是双向绑定
我们先从单向绑定切入单向绑定非常简单,就是把Model绑定到View,当我们用JavaScript代码更新Model时,View就会自动更新双向绑定就很容易联想到了,在单向绑定的基础上,用户更新了View,Model的数据也自动被更新了,这种情况就是双向绑定举个栗子

双向绑定的原理是什么
我们都知道 Vue 是数据双向绑定的框架,双向绑定由三个重要部分构成
数据层(Model):应用的数据及业务逻辑
视图层(View):应用的展示效果,各类UI组件
业务逻辑层(ViewModel):框架封装的核心,它负责将数据与视图关联起来
而上面的这个分层的架构方案,可以用一个专业术语进行称呼:MVVM这里的控制层的核心功能便是 “数据双向绑定” 。自然,我们只需弄懂它是什么,便可以进一步了解数据绑定的原理
理解ViewModel
它的主要职责就是:
数据变化后更新视图
视图变化后更新数据
当然,它还有两个主要部分组成
监听器(Observer):对所有数据的属性进行监听
解析器(Compiler):对每个元素节点的指令进行扫描跟解析,根据指令模板替换数据,以及绑定相应的更新函数
实现双向绑定
我们还是以Vue为例,先来看看Vue中的双向绑定流程是什么的
new Vue()首先执行初始化,对data执行响应化处理,这个过程发生Observe中
同时对模板执行编译,找到其中动态绑定的数据,从data中获取并初始化视图,这个过程发生在Compile中
同时定义⼀个更新函数和Watcher,将来对应数据变化时Watcher会调用更新函数
由于data的某个key在⼀个视图中可能出现多次,所以每个key都需要⼀个管家Dep来管理多个Watcher
将来data中数据⼀旦发生变化,会首先找到对应的Dep,通知所有Watcher执行更新函数
说说你对SPA(单页应用)的理解?

什么是SPA
SPA(single-page application),翻译过来就是单页应用SPA是一种网络应用程序或网站的模型,它通过动态重写当前页面来与用户交互,这种方法避免了页面之间切换打断用户体验在单页应用中,所有必要的代码(HTML、JavaScript和CSS)都通过单个页面的加载而检索,或者根据需要(通常是为响应用户操作)动态装载适当的资源并添加到页面页面在任何时间点都不会重新加载,也不会将控制转移到其他页面举个例子来讲就是一个杯子,早上装的牛奶,中午装的是开水,晚上装的是茶,我们发现,变的始终是杯子里的内容,而杯子始终是那个杯子结构如下图

SPA和MPA的区别
单页应用与多页应用的区别
|
| 单页面应用(SPA) | 多页面应用(MPA) |
|---|---|
| 组成 | 一个主页面和多个页面片段 |
| 刷新方式 | 局部刷新 |
| url模式 | 哈希模式 |
| SEO搜索引擎优化 | 难实现,可使用SSR方式改善 |
| 数据传递 | 容易 |
| 页面切换 | 速度快,用户体验良好 |
| 维护成本 | 相对容易 |
单页应用优缺点
优点:
具有桌面应用的即时性、网站的可移植性和可访问性
用户体验好、快,内容的改变不需要重新加载整个页面
良好的前后端分离,分工更明确
缺点:
不利于搜索引擎的抓取
首次渲染速度相对较慢
实现一个SPA
原理
监听地址栏中hash变化驱动界面变化
用pushsate记录浏览器的历史,驱动界面发送变化

实现
hash 模式
核心通过监听url中的hash来进行路由跳转
// 定义 Router
class Router {
constructor () {
this.routes = {}; // 存放路由path及callback
this.currentUrl = ‘’;
// 监听路由change调用相对应的路由回调
window.addEventListener('load', this.refresh, false);
window.addEventListener('hashchange', this.refresh, false);
}
route(path, callback){
this.routes[path] = callback;
}
push(path) {
this.routes[path] && this.routes[path]()
}
}
// 使用 router
window.miniRouter = new Router();
miniRouter.route(’/’, () => console.log(‘page1’))
miniRouter.route(’/page2’, () => console.log(‘page2’))
miniRouter.push(’/’) // page1
miniRouter.push(’/page2’) // page2
history模式
history 模式核心借用 HTML5 history api,api 提供了丰富的 router 相关属性先了解一个几个相关的api
history.pushState 浏览器历史纪录添加记录
history.replaceState修改浏览器历史纪录中当前纪录
history.popState 当 history 发生变化时触发
// 定义 Router
class Router {
constructor () {
this.routes = {};
this.listerPopState()
}
init(path) {
history.replaceState({path: path}, null, path);
this.routes[path] && this.routes[path]();
}
route(path, callback){
this.routes[path] = callback;
}
push(path) {
history.pushState({path: path}, null, path);
this.routes[path] && this.routes[path]();
}
listerPopState () {
window.addEventListener('popstate' , e => {
const path = e.state && e.state.path;
this.routers[path] && this.routers[path]()
})
}
}
// 使用 Router
window.miniRouter = new Router();
miniRouter.route(’/’, ()=> console.log(‘page1’))
miniRouter.route(’/page2’, ()=> console.log(‘page2’))
// 跳转
miniRouter.push(’/page2’) // page2
题外话:如何给SPA做SEO
下面给出基于Vue的SPA如何实现SEO的三种方式
SSR服务端渲染
将组件或页面通过服务器生成html,再返回给浏览器,如nuxt.js
静态化
目前主流的静态化主要有两种:(1)一种是通过程序将动态页面抓取并保存为静态页面,这样的页面的实际存在于服务器的硬盘中(2)另外一种是通过WEB服务器的 URL Rewrite的方式,它的原理是通过web服务器内部模块按一定规则将外部的URL请求转化为内部的文件地址,一句话来说就是把外部请求的静态地址转化为实际的动态页面地址,而静态页面实际是不存在的。这两种方法都达到了实现URL静态化的效果
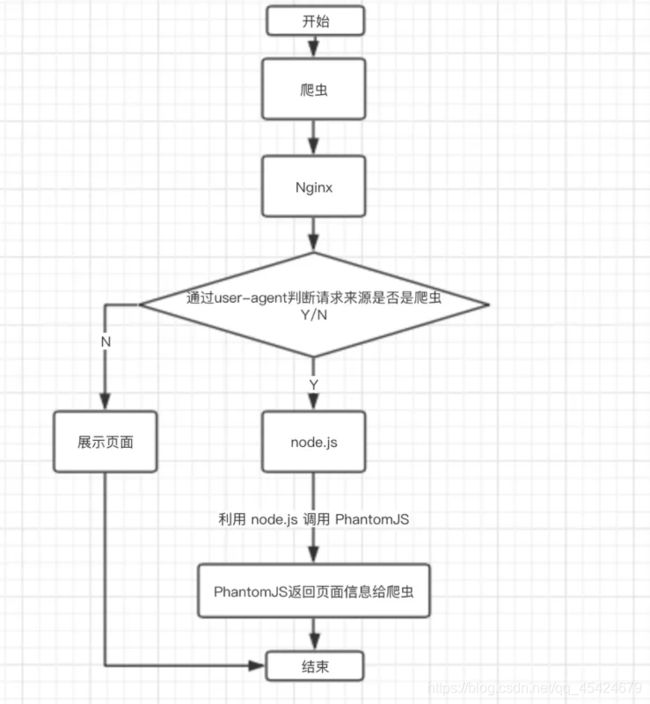
使用Phantomjs针对爬虫处理
原理是通过Nginx配置,判断访问来源是否为爬虫,如果是则搜索引擎的爬虫请求会转发到一个node server,再通过PhantomJS来解析完整的HTML,返回给爬虫。下面是大致流程图
Vue实例挂载的过程中发生了什么?
在调用beforeCreate之前,数据初始化并未完成,像data、props这些属性无法访问到
到了created的时候,数据已经初始化完成,能够访问data、props这些属性,但这时候并未完成dom的挂载,因此无法访问到dom元素
挂载方法是调用vm.$mount方法
说说你对Vue生命周期的理解
生命周期 描述
beforeCreate 组件实例被创建之初
created 组件实例已经完全创建
beforeMount 组件挂载之前
mounted 组件挂载到实例上去之后
beforeUpdate 组件数据发生变化,更新之前
updated 数据数据更新之后
beforeDestroy 组件实例销毁之前
destroyed 组件实例销毁之后
activated keep-alive 缓存的组件激活时
deactivated keep-alive 缓存的组件停用时调用
errorCaptured 捕获一个来自子孙组件的错误时被调用
具体分析
beforeCreate -> created
初始化vue实例,进行数据观测
created
完成数据观测,属性与方法的运算,watch、event事件回调的配置
可调用methods中的方法,访问和修改data数据触发响应式渲染dom,可通过computed和watch完成数据计算
此时vm.$el 并没有被创建
created -> beforeMount
判断是否存在el选项,若不存在则停止编译,直到调用vm.$mount(el)才会继续编译
优先级:render > template > outerHTML
vm.el获取到的是挂载DOM的
beforeMount
在此阶段可获取到vm.el
此阶段vm.el虽已完成DOM初始化,但并未挂载在el选项上
beforeMount -> mounted
此阶段vm.el完成挂载,vm.$el生成的DOM替换了el选项所对应的DOM
mounted
vm.el已完成DOM的挂载与渲染,此刻打印vm.$el,发现之前的挂载点及内容已被替换成新的DOM
beforeUpdate
更新的数据必须是被渲染在模板上的(el、template、render之一)
此时view层还未更新
若在beforeUpdate中再次修改数据,不会再次触发更新方法
updated
完成view层的更新
若在updated中再次修改数据,会再次触发更新方法(beforeUpdate、updated)
beforeDestroy
实例被销毁前调用,此时实例属性与方法仍可访问
destroyed
完全销毁一个实例。可清理它与其它实例的连接,解绑它的全部指令及事件监听器
并不能清除DOM,仅仅销毁实例
题外话:数据请求在created和mouted的区别
created是在组件实例一旦创建完成的时候立刻调用,这时候页面dom节点并未生成mounted是在页面dom节点渲染完毕之后就立刻执行的触发时机上created是比mounted要更早的两者相同点:都能拿到实例对象的属性和方法讨论这个问题本质就是触发的时机,放在mounted请求有可能导致页面闪动(页面dom结构已经生成),但如果在页面加载前完成则不会出现此情况建议:放在create生命周期当中