前几天有个小伙伴让我帮他写个代码,要求如下:
- 爬取知网文献
- 检索条件:学科类别勾选“社会科学一辑”所有“法学”类;
- 文献类型“期刊”,来源“cssci”,时间不限
- 主题词“地下空间”
我尝试了一下,电脑版搞不定(应该是我水平差),但是手机版,可以简单实现这个功能
功能介绍
流程:
- 用
selenium(浏览器自动化测试框架)打开浏览器 - 输入检索关键词
地下空间 - 筛选文献,把期刊来源设置为
cssci - 筛选学科(这部分后面再补充)
- 读取文献总数量,加载所有页面
- 读取每篇文献的
标题、作者、摘要、来源、引用、链接 - 保存成Excel文件

汇总成Excel
准备工作
在开始写代码之前,要保证两点:
1、你有Python的软件,安装好selenium 的库了
2、安装对应的浏览器驱动
Python的安装你可以点这里 Python程序的安装和运行
安装selenium 也很简单,在附件—>命令提示符 打开窗口,输入pip install selenium
关于安装对应的浏览器驱动,以 Chrome 浏览器,点击右上角点点点的那个符号,选择帮助 - 关于 Google Chrome
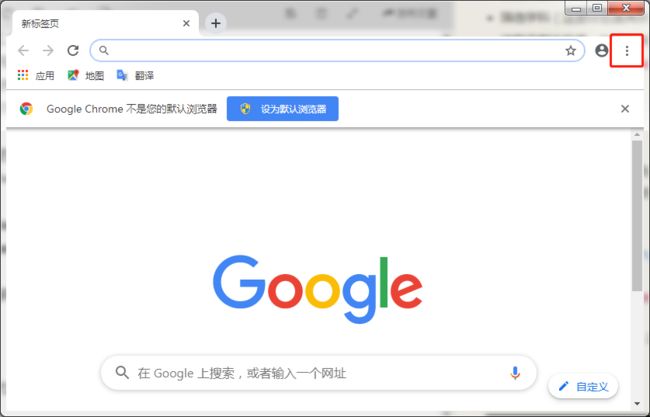
可以看到浏览器的版本号,然后我们去下载一个驱动

版本号
打开 https://npm.taobao.org/mirrors/chromedriver ,选择一个和你版本比较接近的安装文件

我是Windows系统,所以我下载chromedriver_win32.zip
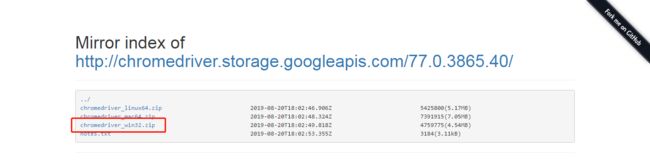
下载之后,把这个文件解压,里面只有一个.exe后缀的驱动文件。把它剪切到 Python 安装目录的 Scripts 文件夹里。

怎么找到 Python 的安装目录,你可以在附件—>命令提示符 ,打开命令提示符,输入where python。比如我的安装目录,在C盘下面

开始干活
selenium是个很神奇的东西,它可以帮你模拟浏览器的操作
先把库都放进来
from selenium import webdriver # selenium用于打开浏览器
import time # 把关于时间的库加进来,这个是系统自带的
import xlwt # 这个库是为了后面保存Excel
把浏览器打开,用time.sleep人为的暂停一会,速度太快了自己都看不清操作~
browser = webdriver.Chrome()
# 打开博客
browser.get('http://wap.cnki.net/touch/web/guide')
time.sleep(0.3)
进入搜索,输入主题。可以根据ID搜索,也可以根据class搜索
topic = "地下空间"
browser.find_element_by_id('btnSearch').click()
browser.find_element_by_id('keyword_ordinary').send_keys(topic)
browser.find_element_by_class_name('btn-search').click()
time.sleep(0.3)

输入主题词
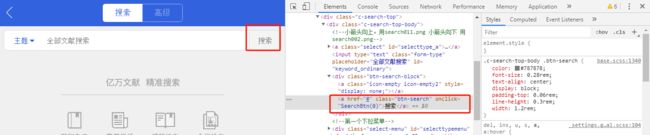
点击搜索
筛选文献,把期刊来源勾选为“cssci”
browser.find_element_by_id("articletype_a").click()
time.sleep(0.3)
browser.find_element_by_css_selector("a[data-value=\"14\"]").click()

勾选期刊
获取文献数量
num = browser.find_element_by_class_name('search-number').text
num = int(num[:-1])

获取文献数量
加载所有页面
for i in range(int(num/10)):
browser.find_element_by_class_name('c-company__body-item-more').click()
time.sleep(0.3)

加载所有页面
获取文献信息
title = browser.find_elements_by_class_name('c-company__body-title')
author = browser.find_elements_by_class_name('c-company__body-author')
link = browser.find_elements_by_class_name('c-company-top-link')
content = browser.find_elements_by_class_name('c-company__body-content')
company = browser.find_elements_by_class_name('color-green')
info = browser.find_elements_by_class_name('c-company__body-info')

获取文献信息
保存到Excel
# 定义保存Excel的位置
workbook = xlwt.Workbook() #定义workbook
sheet = workbook.add_sheet(topic) #添加sheet
head = ['标题', '作者', '摘要', '来源', '引用', '链接'] #表头
for h in range(len(head)):
sheet.write(0, h, head[h]) #把表头写到Excel里面去
i = 1 #定义Excel表格的行数,从第二行开始写入,第一行已经写了表头
for n in range(len(title)):
sheet.write(i, 0, title[n].text)
sheet.write(i, 1, author[n].text)
sheet.write(i, 2, content[n].text)
sheet.write(i, 3, company[n].text)
sheet.write(i, 4, info[n].text)
sheet.write(i, 5, link[n].get_attribute('href'))
i += 1
workbook.save('C:/Users/Administrator/Desktop/知网.xls')
完整代码
# -*- coding: utf-8 -*-
"""
Created on Wed Nov 13 15:25:33 2019
@author: Yenny
"""
from selenium import webdriver
import time
import xlwt
browser = webdriver.Chrome()
# 打开博客
browser.get('http://wap.cnki.net/touch/web/guide')
time.sleep(0.3)
# 进入搜索,输入主题
topic = "地下空间"
browser.find_element_by_id('btnSearch').click()
browser.find_element_by_id('keyword_ordinary').send_keys(topic)
browser.find_element_by_class_name('btn-search').click()
time.sleep(0.3)
# 筛选文献
browser.find_element_by_id("articletype_a").click()
time.sleep(0.3)
browser.find_element_by_css_selector("a[data-value=\"14\"]").click()
# 筛选学科
# browser.find_element_by_id("menu-toggle").click()
# browser.find_element_by_class_name('c-filter-title').click()
# 获取文献数量
num = browser.find_element_by_class_name('search-number').text
num = int(num[:-1])
# 加载所有页面
for i in range(int(num/10)):
browser.find_element_by_class_name('c-company__body-item-more').click()
time.sleep(0.3)
# 获取文献信息
title = browser.find_elements_by_class_name('c-company__body-title')
author = browser.find_elements_by_class_name('c-company__body-author')
link = browser.find_elements_by_class_name('c-company-top-link')
content = browser.find_elements_by_class_name('c-company__body-content')
company = browser.find_elements_by_class_name('color-green')
info = browser.find_elements_by_class_name('c-company__body-info')
# 保存到Excel
# 定义保存Excel的位置
workbook = xlwt.Workbook() #定义workbook
sheet = workbook.add_sheet(topic) #添加sheet
head = ['标题', '作者', '摘要', '来源', '引用', '链接'] #表头
for h in range(len(head)):
sheet.write(0, h, head[h]) #把表头写到Excel里面去
i = 1 #定义Excel表格的行数,从第二行开始写入,第一行已经写了表头
for n in range(len(title)):
sheet.write(i, 0, title[n].text)
sheet.write(i, 1, author[n].text)
sheet.write(i, 2, content[n].text)
sheet.write(i, 3, company[n].text)
sheet.write(i, 4, info[n].text)
sheet.write(i, 5, link[n].get_attribute('href'))
i += 1
workbook.save('C:/Users/Administrator/Desktop/知网.xls')