翻了翻之前的文件夹,找到这个之前整理的YOLO理解文档,在此基础上,做了一些修改,特做更新。
我相信很多同学在理解YOLO的时候是有很多疑惑的,尤其是1个cell,两个 bounding box,20个类别,简直头大。这篇文章带你来理解,如果有错误,不吝赐教。
相比于RCNN系列的算法,YOLO将分类问题转换为回归问题。关于RCNN系列,会在后面更新,请不要捉急。
既然是回归问题,就要用回归的思维来看待。什么意思呢?比如说,我们预测2019年12月的房价,它是有很多因素共同起作用,每个因素可以看作x,有了历史数据,假设房价是线性变化,那么我们只需要求得系数,就可把12月的x带进去,就得到了房价。整么来理解YOLO呢?
首先,图像就是输入,如果把图像分成块的话,每个块就是x,现在有很多这样的图像,那么只需要求得一组系数,对于新来的一幅图x’,就可以把x’带进去,就知道这个块或这幅图是什么东西。那么这个系数就可以看作是bounding box(就是把目标框住的那个框框)。虽然每个块只需要一个bounding box,但是,这个bounding box到底长什么样,我们不知道。与其这样,倒不如1个cell里面多高几个bounding box,那个好就用那个,反正,最后我只用其中一个就行了。开始的时候,我们并不知道bounding box的形状,只知道有几个。怎么办呢,别捉急。让CNN去学习吧。我们有几千万的训练集,还怕啥。我想这应该就是YOLO的核心思想了。我想,稍微分析下,应该就看出来,这种方法准确度应该是有问题的,而实验也证明了这一点。这很类似于RCNN中的bounding box regression(请参考我的其他博客)。
好吧,我表示原始论文看起来真他呀费劲。
找了很久,这篇博客写的也不错,可以看看。
https://segmentfault.com/a/1190000016692873?utm_source=tag-newest
话不多说,上菜。我感觉还是不要按照原文的思路来,太费劲了。
第一,先说一说IOU,置信度
先上图。
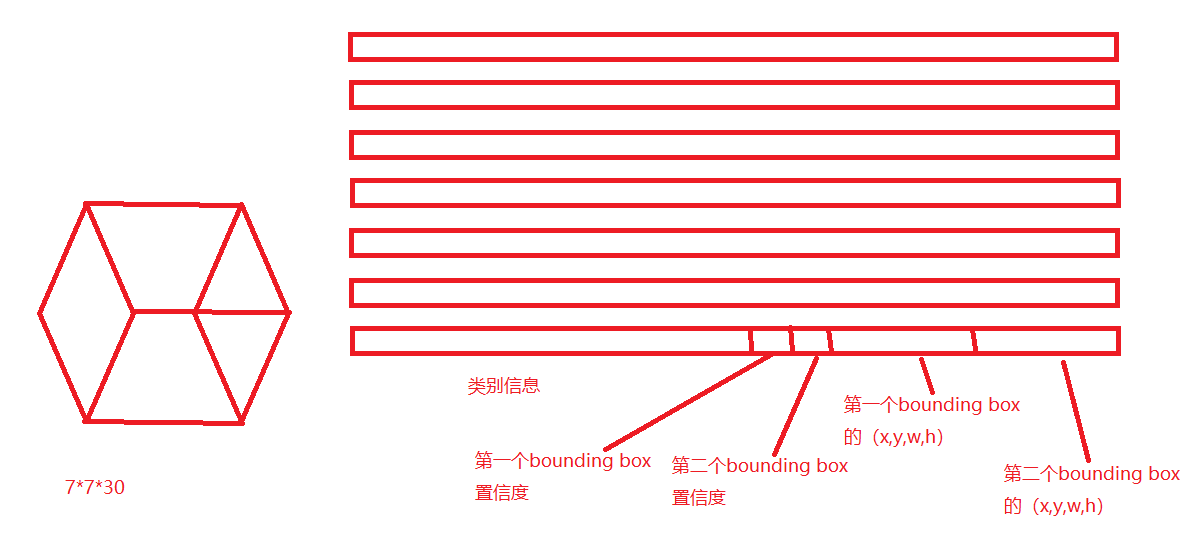
把图像分成77的块,那么对于输入的图像就可以构建一个77*30的张量,这些标签都是已知的。

P(object):就是说这个cell中存在物体的概率。怎么定义是否有目标呢?如果目标的中心点在这个cell里面,那么就认为有目标,如果不在,就没有目标。取值为0和1.
定义置信度:如果cell里面有目标,那么就用IOU来计算预测值(预测的bounding box)和真实值(真实的bounding box)差异。
P(class|objet):就是说这个cell存在物体,而且是某个类的概率。
那么最终,对于某个cell的一个box 预测某个类的概率就表示为:
P(class|objet)P(object)IOU
比如说上面的情况,只有一个类。
我们就可以定义这样的训练标签,如果有错误请指出。
【000000000000000000000000000000 // 第一个cell
000000000000000000000000000000
.......
1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,1,0,0.7,0.02,0.14,0.14,0,0,0,0 // 第23个cell
........
000000000000000000000000000000】 // 第49个cell
第二,再说一说网络结构
此处是截图
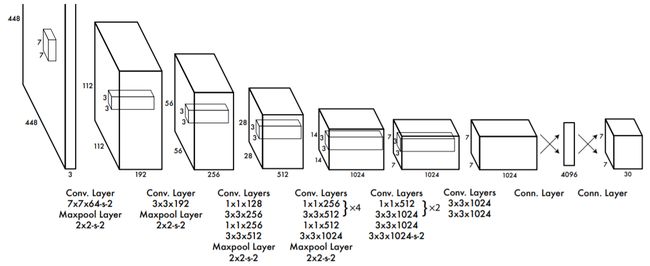
下面这个图视乎更直观一点。原始图像卷啊卷,就被卷成了7730这样的张量。这家伙跟cell有什么关系呢?比如说,cell是77的,卷啊卷,最后原始图像中的一个块,就成了77中的一个点。
第三,然后说一说训练过程
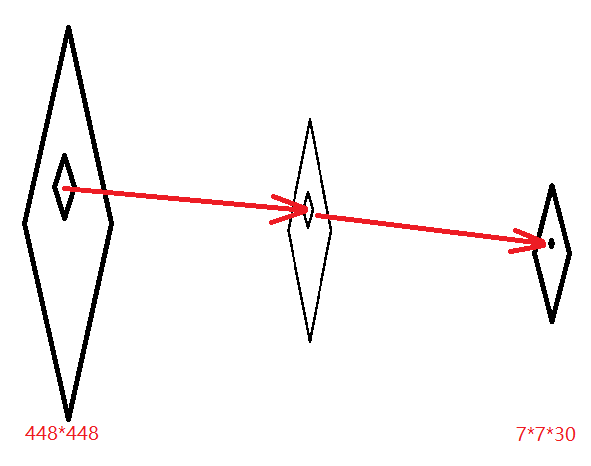
在上面我们可以看到,YOLO就是一个网络,卷积,池化,全连接,最后输出一个7730的tensor。此处应该有个图,我想应该很直观了,那就用本文的第一个图吧。
我觉得我们不能被有些博客给迷惑了。好吧,还是说说这个最终的tensor是个啥样的。就是这样的,一条粗粗链子。对于整个网络来说,你给他一幅图,它卷啊卷,池啊池,啪,输出一个7730的张量。假设这个张量就是OK的,就是我们想要的,那么,我们按照张量的结果,进行解析,就可以在图上画出这个(x,y,w,h)对应的区域。好了,一般情况下第一次肯定不可能就得到好的结果,那怎么办呢?我们在输入训练图像的时候,是不是有标签呢,而且是不是也有对应的类别的信息呢。整,把这些信息搞成7730的张量,这样不就可以用反向传播去迭代了嘛。一遍一遍的训练。你会发现,最后输出的张量,越来越是我们想要的。就是这么神奇。
第四,总结一下吧
我自己还是挺喜欢YOLO的,简单有效,思路清奇。YOLO有很多小细节,推荐的博客里面有介绍,我就不说了。后续会继续更新V2和V3版本。本文已同步至公众号,欢迎订阅。
