数学建模笔记一数据标准化
数据标准化
数据标准化的意义
1.为什么要进行标准化?
一个目标变量(y)可以认为是由多个特征变量(x)影响和控制的,这些特征变量的量纲和数值的量级通常会不一样;而通过标准化处理,可以使得不同的特征变量具有相同的尺度(也就是说将特征的值控制在某个范围内),这样目标变量就可以由多个相同尺寸的特征变量进行控制,这样,在使用梯度下降法学习参数的时候,不同特征对参数的影响程度就一样了
简而言之:对数据标准化的目的是消除特征之间的差异性
2.标准化运用的条件
当原始数据不同维度上的特征的尺度(单位)不一致时,需要标准化步骤对数据进行预处理,反之则不需要进行数据标准化。
例如:
a 回归问题
b 机器学习算法
c 训练神经网络
d 聚类问题
e 分类问题
f 主成分分析(PCA)问题
引用1
数据标准化的具体实施
1.数据标准化和数据归一化的区别
数据归一化是数据标准化的一种典型做法,即将数据统一映射到[0,1]区间上.
数据的标准化是指将数据按照比例缩放,使之落入一个特定的区间.
min-max标准化(Min-max normalization)
min-max标准化方法是对原始数据进行线性变换。设minA和maxA分别为属性A的最小值和最大值,将A的一个原始值x通过min-max标准化映射成在区间[0,1]中的值x’,其公式为:
新数据=(原数据-最小值)/(最大值-最小值)
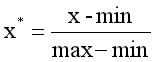
不足:当有新数据加入时需要重新进行数据归一化
优点:
1.在不涉及距离度量、协方差计算、数据不符合正态分布的时候,适合用Min-max normalization
有关协方差的知识
期望
2、即0-1标准化,又称最大值-最小值标准化,核心要义是将原始指标缩放到0~1之间的区间内,但不改变原始数据的分布
3、对于方差非常小的属性可以增强其稳定性;
4、维持稀疏矩阵中为0的条目。
# 归一化处理
X_train_norm = preprocessing.normalize(train_data, norm='l2', axis=1) # 直接用标准化函数
normalizer = preprocessing.Normalizer() # 也可以用标准化类,然后调用方法
X_train_norm2 = normalizer.fit_transform(train_data)
# 0-1标准化
X_train_minmax = preprocessing.minmax_scale(train_data, feature_range=(0, 1), axis=0, copy=True) # 直接用标准化函数
min_max_scaler = preprocessing.MinMaxScaler() # 也可以用标准化类,然后调用方法
X_train_minmax2 = min_max_scaler.fit_transform(train_data)
z-score 标准化(zero-mean normalization)
这种方法基于原始数据的均值(mean)和标准差(standard deviation)进行数据的标准化。将A的原始值x使用z-score标准化到x’。
z-score标准化方法适用于属性A的最大值和最小值未知的情况,或有超出取值范围的离群数据的情况。标准差标准化,归一化后的数据呈正态分布,即均值为零
公式为:新数据=(原数据-均值)/标准差
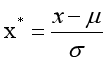
不足:假如原始数据没有呈高斯分布,标准化的数据分布效果并不好
在分类、聚类算法中,需要使用距离来度量相似性的时候、或者使用PCA技术进行降维的时候,Z-score standardization表现更好。
# z-score标准化1
X_train_zs = preprocessing.scale(train_data, axis=0, with_mean=True, with_std=True, copy=True) # 直接用标准化函数
zs_scaler = preprocessing.StandardScaler() # 也可以用标准化类,然后调用方法
X_train_zs2 = zs_scaler.fit_transform(train_data)
# z-score标准化2
def z_score(x, axis):
x = np.array(x).astype(float)
xr = np.rollaxis(x, axis=axis)
xr -= np.mean(x, axis=axis)
xr /= np.std(x, axis=axis)
# print(x)
return x
# z-score标准化3
data = (data - data.mean(axis = 0))/(data.std(axis = 0)) #简洁的语句实现了标准化变换,类似地可以实现任何想要的变换。
比重法
L2正则化:y = x/sqrt(Σx^2),即新数据=(原数据)/sqrt(平方和),被称为L2正则转换。
正则化则是通过范数规则来约束特征属性,通过正则化我们可以降低数据训练处来的模型的过拟合可能,和机器学习中所讲述的L1、L2正则的效果一样。在进行正则化操作的过程中,不会改变数据的分布情况,但是会改变数据特征之间的相关特性。
二值化
对于定量数据(特征取值连续),根据给定的阈值将其进行转换,如果大于阈值赋值为1,否则赋值为0;对于定性数据(特征取值离散,也有可能是文本数据),根据给定规则将其进行转换,符合规则的赋值为1,否则赋值为0。
# 二值化
X_train_binary = preprocessing.binarize(train_data, threshold=0, copy=True) # 按照阈值threshold将数据转换成成0-1,小于等于threshold为 0
特征转换
● 文本特征属性转换:机器学习的模型算法均要求输入的数据必须是数值型的,所以对于文本类型的特征属性,需要进行文本数据转换,也就是需要将文本数据转换为数值型数据。常用方式如下: 词袋法(BOW/TF)、TF-IDF(Term frequency-inverse document frequency)、HashTF、Word2Vec(主要用于单词的相似性考量)。
from sklearn import preprocessing
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris
import pandas as pd
import numpy as np
# 将字符串转化为数字,用pd.Categorical
# pd.Categorical(data)
# iris_data['Species'] = iris_data["Species"].map({
0:"setosa",1:"versicolor",2:"virginica"})
X, y = iris_data.iloc[:, :-1], iris_data.iloc[:, -1]
train_data, test_data, train_target, test_target = train_test_split(X, y, test_size=0.25, stratify=y)
●缺省值填充:缺省值是数据中最常见的一个问题,处理缺省值有很多方式,主要包括以下四个 步骤进行缺省值处理: 确定缺省值范围->去除不需要的字段->填充缺省值内容->重新获取数据。
from sklearn import preprocessing
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris
import pandas as pd
import numpy as np
# 数据清洗
# 重复值处理
print('存在' if any(train_data.duplicated()) else '不存在', '重复观测值')
train_data.drop_duplicates()
# 缺失值处理
print('存在' if any(train_data.isnull()) else '不存在', '缺失值')
train_data.dropna() # 直接删除记录
train_data.fillna(method='ffill') # 前向填充
train_data.fillna(method='bfill') # 后向填充
train_data.fillna(value=2) # 值填充
train_data.fillna(value={
'sepal length (cm)':train_data['sepal length (cm)'].mean()}) # 统计值填充
# 缺失值插补
x = [[np.nan, '1', '3'], [np.nan, '3', '5']]
imputer = preprocessing.Imputer(missing_values='NaN', strategy='mean', axis=1)
y = imputer.fit_transform(x)
●哑编码(OneHotEncoder):也称哑变量处理,对于定性的数据(也就是分类的数据),可以采用N位的状态寄存器来对N个状态进行编码,每个状态都有一个独立的寄存器位,并且在任意状态下只有一位有效;是一种常用的将特征数字化的方式。比如有一个特征属性:[‘male’,‘female’],那么male使用向量[1,0]表示,female使用[0,1]
●二值化
●标准化(归一化)
from sklearn import preprocessing
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris
import pandas as pd
import numpy as np
# 标准差监测
xmean = data1.mean()
xstd = data1.std()
print('存在' if any(data1>xmean+2*xstd) else '不存在', '上限异常值')
print('存在' if any(data1<xmean-2*xstd) else '不存在', '下限异常值')
# 箱线图监测
q1 = data1.quantile(0.25)
q3 = data1.quantile(0.75)
up = q3+1.5*(q3-q1)
dw = q1-1.5*(q3-q1)
print('存在' if any(data1> up) else '不存在', '上限异常值')
print('存在' if any(data1< dw) else '不存在', '下限异常值')
data1[data1>up] = data1[data1<up].max()
data1[data1<dw] = data1[data1>dw].min()
数据标准化代码引用
引用