第六周python作业
1、第4章-18 猴子选大王
一群猴子要选新猴王。新猴王的选择方法是:让N只候选猴子围成一圈,从某位置起顺序编号为1~N号。从第1号开始报数,每轮从1报到3,凡报到3的猴子即退出圈子,接着又从紧邻的下一只猴子开始同样的报数。如此不断循环,最后剩下的一只猴子就选为猴王。请问是原来第几号猴子当选猴王?
我的代码:

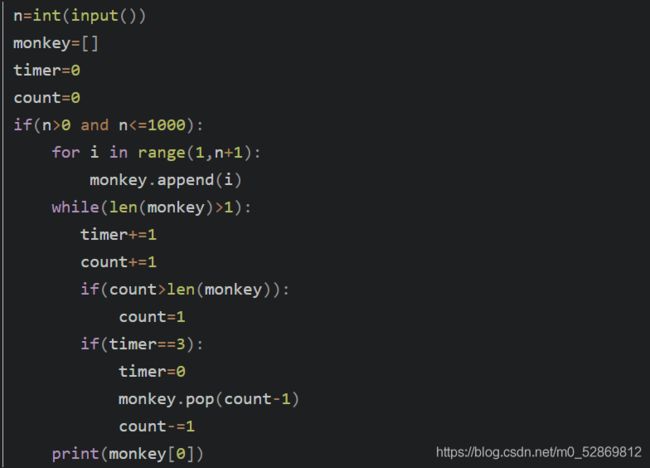
他人的代码:
反思:
这又是一道想了很久的题目,但是看到别人的代码的那一刻,我当场就是虎躯一震,这不是和我的思路差不多吗??!为了避免这种惨案再次发生,我对这两个代码进行了比较,以下是总结出来的主要问题:
思路上:首先,由于我一直没有一个很清晰的解题思路,所以想到什么方法就直接实践,一是没有做好记录,导致最后出来的包含了所有方法的一小部分,也就是由于代码没有进行及时的修改,现有的解题代码是在原来的解题代码上进行的,修改不彻底,无辜耗费大量时间和精力。其次,我没有很好地将每一个步骤想清楚如何用计算机语言表示出来,这也导致了上一个问题的出现
修改方法一:可以选择开多个窗口,在另一个窗口写下新的方法,再进行比对和修改,写出新的代码
好处:直观
坏处:要写好多次代码
**修改方法二:**在纸上写方法,然后自己脑子里面debug,直到找到最好的解决方法
好处:比起上一个方法,准确率更高
坏处:耗费时间长,脑子里面debug有可能算错,纸上写又很耗时间
目前打算两种都试试,看看哪个更适合,或者有新的
2、第4章-19 矩阵运算
给定一个n×n的方阵,本题要求计算该矩阵除副对角线、最后一列和最后一行以外的所有元素之和。副对角线为从矩阵的右上角至左下角的连线。
我的代码:
# -*- coding: utf-8 -*-
import numpy as np
# 初始化
n = int(input())
t = n
total = 0
diagonal = 0
last_column = 0
last_row = 0
storage = []
# 生成矩阵
for _ in range(n):
temporary = list(map(int, input().split()))
storage.extend(temporary)
matrix = np.array(storage).reshape((n, n))
# 计算出副对角线,最后一列和最后一行的所有元素之和还有所有元素之和,把他们相减
for i in range(n):
diagonal += matrix[t-1][i]
t -= 1
for j in range(n):
for m in range(n):
total += matrix[j][m]
last_row += matrix[n - 1][j]
last_column += matrix[j][n-1]
print(total-last_row-last_column-diagonal+matrix[n-1][0]+matrix[0][n-1]+matrix[n-1][n-1]
)
他人的代码:
n=int(input())
a=[]
sum=0
for i in range(n):
s=input()
a.append([int(n) for n in s.split()])
for j in range(n):
for k in range(n):
if j!=n-1 and k!=n-1 and j+k!=n-1:
sum+=a[j][k]
print(sum)
反思:
①在他人的代码里面使用的变量sum在我这里写成了total,其实我一开始也是想用sum的,然而直接给我报错"shadows built in name"??!stack overflow里面的解释好像是说(英文水平有限,理解错了请谅解)这是某种bug?Warning里面说这是种W292 error,应该又是违反了PEP8协议了,由于犯错次数太多,我把我的错误整理在下面,以后忘记了再回来看看,不用再到处找:
PEP 8: E231 missing whitespace after ‘,’
这个意思是逗号后面要有一个空格
PEP 8: W292 no newline at end of file
这里是要求你在末尾新起一行
PEP 8: E262 inline comment should start with ‘# ’
行内注释应该以’#'加空格开始
②好家伙原来还可以这样使用append把输入的不确定个数的元素插入到列表里面:
s=input()
a.append([int(n) for n in s.split()])
我也试过如果直接使用a.append(map(int,input().split())的话,得到的是一个“[map in XXX000…]"一串超长的类似于16进制表示变量储存位置的编码,小白直呼懵逼,不过extend倒是可以解决这个问题,也算是初次尝试了继承的便利
③哇我写了这么久的创建矩阵被一条:
if j!=n-1 and k!=n-1 and j+k!=n-1:
sum+=a[j][k]
自 信 心 遭 到 暴 击
这里使用的是反证法,而我使用的是直接证明法
做题目还是不能太死板,如果太久还是做不出来,老师教的反证法还是得搬出来用
绕了一个大圈子反而学会了numpy的应用
主要包括:
np.array([])创建numpy的array对象
np.reshape()进行矩阵切片生成运算
numpy还有很多功能,个人对线性代数感兴趣,这里埋个坑,以后把runoob上的numpy教程学了做好笔记发blog
3、第4章-20 求矩阵各行元素之和
本题要求编写程序,求一个给定的m×n矩阵各行元素之和。
我的代码:(iter version)

我的代码:(for in range version)

反思:以前在印尼语实验中师兄就跟我们强调过迭代器的效率和实用性之强,这次特意使用了一次迭代器来替换for in range,但是报错十分夸张:
以下是测试代码(from runoob):
import sys # 引入 sys 模块
list=[1,2,3,4]
it = iter(list) # 创建迭代器对象
while True:
try:
print (next(it))
except StopIteration:
sys.exit()
然后是报错:
ERROR:root:Internal Python error in the inspect module.
Below is the traceback from this internal error.
1
2
3
4
Traceback (most recent call last):
File "" , line 8, in <module>
print (next(it))
StopIteration
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "D:\anaconda\lib\site-packages\IPython\core\interactiveshell.py", line 3418, in run_code
exec(code_obj, self.user_global_ns, self.user_ns)
File "" , line 10, in <module>
sys.exit()
SystemExit
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "D:\anaconda\lib\site-packages\IPython\core\ultratb.py", line 1170, in get_records
return _fixed_getinnerframes(etb, number_of_lines_of_context, tb_offset)
File "D:\anaconda\lib\site-packages\IPython\core\ultratb.py", line 316, in wrapped
return f(*args, **kwargs)
File "D:\anaconda\lib\site-packages\IPython\core\ultratb.py", line 350, in _fixed_getinnerframes
records = fix_frame_records_filenames(inspect.getinnerframes(etb, context))
File "D:\anaconda\lib\inspect.py", line 1503, in getinnerframes
frameinfo = (tb.tb_frame,) + getframeinfo(tb, context)
AttributeError: 'tuple' object has no attribute 'tb_frame'
---------------------------------------------------------------------------
StopIteration Traceback (most recent call last)
<ipython-input-1-545929cfd7f5> in <module>
7 try:
----> 8 print (next(it))
9 except StopIteration:
StopIteration:
During handling of the above exception, another exception occurred:
SystemExit Traceback (most recent call last)
[... skipping hidden 1 frame]
<ipython-input-1-545929cfd7f5> in <module>
9 except StopIteration:
---> 10 sys.exit()
SystemExit:
During handling of the above exception, another exception occurred:
TypeError Traceback (most recent call last)
[... skipping hidden 1 frame]
D:\anaconda\lib\site-packages\IPython\core\interactiveshell.py in showtraceback(self, exc_tuple, filename, tb_offset, exception_only, running_compiled_code)
2036 stb = ['An exception has occurred, use %tb to see '
2037 'the full traceback.\n']
-> 2038 stb.extend(self.InteractiveTB.get_exception_only(etype,
2039 value))
2040 else:
D:\anaconda\lib\site-packages\IPython\core\ultratb.py in get_exception_only(self, etype, value)
821 value : exception value
822 """
--> 823 return ListTB.structured_traceback(self, etype, value)
824
825 def show_exception_only(self, etype, evalue):
D:\anaconda\lib\site-packages\IPython\core\ultratb.py in structured_traceback(self, etype, evalue, etb, tb_offset, context)
696 chained_exceptions_tb_offset = 0
697 out_list = (
--> 698 self.structured_traceback(
699 etype, evalue, (etb, chained_exc_ids),
700 chained_exceptions_tb_offset, context)
D:\anaconda\lib\site-packages\IPython\core\ultratb.py in structured_traceback(self, etype, value, tb, tb_offset, number_of_lines_of_context)
1434 else:
1435 self.tb = tb
-> 1436 return FormattedTB.structured_traceback(
1437 self, etype, value, tb, tb_offset, number_of_lines_of_context)
1438
D:\anaconda\lib\site-packages\IPython\core\ultratb.py in structured_traceback(self, etype, value, tb, tb_offset, number_of_lines_of_context)
1334 if mode in self.verbose_modes:
1335 # Verbose modes need a full traceback
-> 1336 return VerboseTB.structured_traceback(
1337 self, etype, value, tb, tb_offset, number_of_lines_of_context
1338 )
D:\anaconda\lib\site-packages\IPython\core\ultratb.py in structured_traceback(self, etype, evalue, etb, tb_offset, number_of_lines_of_context)
1191 """Return a nice text document describing the traceback."""
1192
-> 1193 formatted_exception = self.format_exception_as_a_whole(etype, evalue, etb, number_of_lines_of_context,
1194 tb_offset)
1195
D:\anaconda\lib\site-packages\IPython\core\ultratb.py in format_exception_as_a_whole(self, etype, evalue, etb, number_of_lines_of_context, tb_offset)
1149
1150
-> 1151 last_unique, recursion_repeat = find_recursion(orig_etype, evalue, records)
1152
1153 frames = self.format_records(records, last_unique, recursion_repeat)
D:\anaconda\lib\site-packages\IPython\core\ultratb.py in find_recursion(etype, value, records)
449 # first frame (from in to out) that looks different.
450 if not is_recursion_error(etype, value, records):
--> 451 return len(records), 0
452
453 # Select filename, lineno, func_name to track frames with
TypeError: object of type 'NoneType' has no len()
既然这是别人已经测试通过后的代码,我相信应该是我的电脑内部缺少了某种配置,以后有空再找解决方法
4、第4章-21 判断上三角矩阵
上三角矩阵指主对角线以下的元素都为0的矩阵;主对角线为从矩阵的左上角至右下角的连线。
本题要求编写程序,判断一个给定的方阵是否上三角矩阵。
我的代码:
# -*- coding: utf-8 -*-
import numpy as np
import sys
# 初始化
T = int(input())
# 生成矩阵
for _ in range(T):
n = int(input())
count = 0
storage = []
for _ in range(n):
temporary = []
temporary = list(map(int, input().split()))
storage.extend(temporary)
matrix = np.array(storage).reshape((n, n))
# 矩阵判断(反证法)
"""
if matrix[0][0] == 0:
print("NO")
sys.exit()
"""
for i in range(n):
for j in range(i):
if matrix[i][j] != 0:
print("NO")
count += 1
if count == 0:
print("YES")
他人的代码:
x = int(input())
q = []
for y in range(x):
n = int(input())
a = []
count = 0
for i in range(n):
s = input()
a.append([int(n) for n in s.split()])
for j in range(n):
for k in range(n):
if j > k:
if a[j][k] == 0:
count += 1
if count == n * (n - 1) / 2:
q.append(1)
else:
q.append(0)
for z in range(x):
if q[z] == 1:
print("YES")
else:
print("NO")
反思:我的方法没有通过第二个检测点,对比代码后发现我的代码并没有检测出如果上三角部分有为0的部分应该如何处理,而他人的代码里面通过计算所有上三角矩阵元素中非零元素的个数来确保上三角元素全部都不为0
5、第4章-22 找鞍点
一个矩阵元素的“鞍点”是指该位置上的元素值在该行上最大、在该列上最小。
本题要求编写程序,求一个给定的n阶方阵的鞍点。
我的代码:
# -*- coding: utf-8 -*-
import numpy as np
# 初始化
n = int(input())
storage = []
count = 0
# 生成矩阵
for _ in range(n):
temporary = list(map(int, input().split()))
storage.extend(temporary)
matrix = np.array(storage).reshape((n, n))
# 通过两次比较法选出鞍点
for i in range(n):
for j in range(n):
Max = Min = matrix[i][j]
for m in range(n):
if matrix[i][m]> Max:
Max = matrix[i][m]
break
elif matrix[m][j]< Min:
Min = matrix[m][j]
break
if Max == matrix[i][j] and Min == matrix[i][j]:
print("{0:d} {1:d}".format(i,j))
count += 1
if count == 0:
print("NONE")
他人的代码:
n = int(input())
a = []
count = 0
count1 = 0
for i in range(n):
s = input()
a.append([int(n) for n in s.split()])
for j in range(n):
if count1 == n and count == n:
break
for k in range(n):
for k1 in range(n):
if a[j][k] >= a[j][k1]:
count += 1
if count == n:
for j1 in range(n):
if a[j][k] <= a[j1][k]:
count1 += 1
if count1 == n:
print("{} {}".format(j, k))
break
count1 = 0
count = 0
if count1 != n and count != n:
print("NONE")
思路大致相同,不必赘述