Hadoop 完美解决start-all.sh不能启动resourcemanager的问题
一、集群描述
主机:CentOS7.8
jdk1.8
hadoop、hive、hbase、zookeeper:CDH5.14.2
| namenode | datanode1 | datanode2 | |
|---|---|---|---|
| NameNode | ✔(主) | ✔(备) | ✘ |
| DataNode | ✔ | ✔ | ✔ |
| JournalNode | ✔ | ✔ | ✔ |
| QuorumPeerMain | ✔ | ✔ | ✔ |
| ResourceManager | ✘ | ✔(主) | ✔(备) |
| NodeManager | ✔ | ✔ | ✔ |
| HMaster | ✔(主) | ✘ | ✔(备) |
| HRegionServer | ✔ | ✔ | ✔ |
二、问题描述
还记得上学期学习的时候,老师说过备用ResourceManager要手动启动,手动关闭,start-all.sh、start-yarn.sh都是是不能启动的。
启动的时候要这样:
[root@datanode2 ~]# yarn-daemon.sh start resourcemanager
关闭的时候要这样:
[root@datanode2 ~]# yarn-daemon.sh stop resourcemanager
当时觉得麻烦就麻烦点吧,毕竟刚开始水平有限,也没有必要深究那么多,所以这个问题到了现在不仅没有解决,反而变本加厉。
前几天将集群的CentOS6换成了7,进行了一次大换血,结果这回连主ResourceManager都启动不起来了!需要手动启动!
start-all.sh命令其实就是连续执行了start-dfs.sh和start-yarn.sh这两个命令,而在starting yarn daemons的时候只是在namenode上启动ResourceManager,虽然我的namenode上根本就没有ResourceManager。。。而另外两个装有ResourceManager的结点没有收到要启动的命令,所以自然就没有ResourceManager进程。
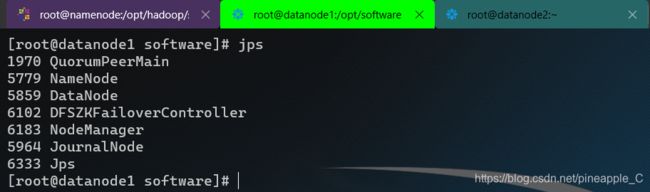
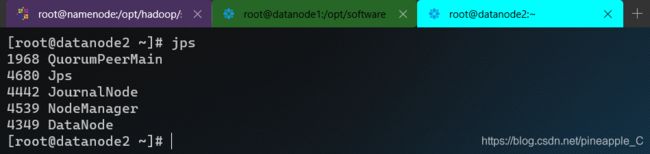
三、问题分析
starting yarn daemons后只是对namenode下达了启动ResourceManager的命令,不像NodeManager对三个结点都下达了启动命令。
所以我觉得可能是start-yarn.sh这个脚本有问题,在有了一定的shell编程基础后,我也尝试着写一些shell脚本。
看一下这个脚本
[root@namenode /]# vim $HADOOP_HOME/sbin/start-yarn.sh
开头的注释即提到 Start all yarn daemons. Run this on master node.
要在主节点上启动所有的yarn守护进程,我是在namenode上启动的呀,所有这一点没有问题,继续往下看。
在31行发现了问题,与33行的NodeManager启动命令相比较,它用的是yarn-daemon.sh这个脚本而不是yarn-daemons.sh
hadoop和yarn都有一个daemon.sh和daemons.sh,这个在$HADOOP_HOME/sbin目录下都能看得到
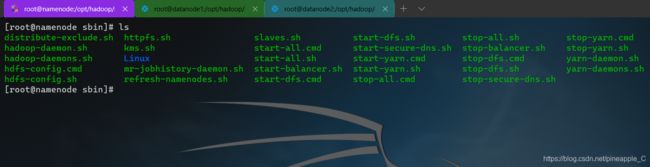
daemon.sh就是在本节点上启动守护进程,而daemons.sh是在所有节点上启动守护进程。daemons.sh会读取$HADOOP_CONF_DIR下的slaves文件(这个在搭集群的时候要写好的),里面保存着每个节点的域名或域名映射。然后daemons.sh就会在每个节点上运行daemon.sh脚本,从而达到在每台机器上都启动守护进程的目的。不得不说,这很妙!
这下问题就变得简单了,只要在31行给daemon加个s就行!虽然会在没有RM的namenode上也启动一下RM,不过这是小问题了,我的主要目的已经达到了。
四、解决问题
以下修改只需在主节点上完成
修改start-yarn.sh
最简单的就直接给31行的daemon加个s就行了,下面的写法主要是为了模仿start-dfs.sh的输出格式(强迫症)
echo "Starting yarn daemons"
bin=`dirname "${BASH_SOURCE-$0}"`
bin=`cd "$bin"; pwd`
DEFAULT_LIBEXEC_DIR="$bin"/../libexec
HADOOP_LIBEXEC_DIR=${HADOOP_LIBEXEC_DIR:-$DEFAULT_LIBEXEC_DIR}
. $HADOOP_LIBEXEC_DIR/yarn-config.sh
echo "Starting Resourcemanagers on [datanode1 datanode2]"
# start resourceManager
"$bin"/yarn-daemons.sh --config $YARN_CONF_DIR start resourcemanager
echo "Starting NodeManagers on [namenode datanode1 datanode2]"
# start nodeManager
"$bin"/yarn-daemons.sh --config $YARN_CONF_DIR start nodemanager
# start proxyserver
#"$bin"/yarn-daemon.sh --config $YARN_CONF_DIR start proxyserver
启动展示:
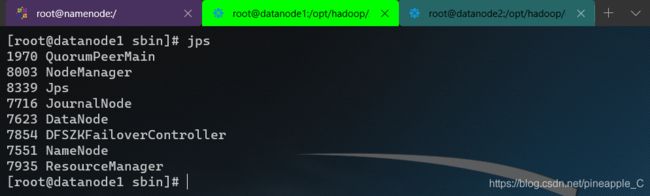

整整齐齐一家子!
上文说到,关闭的时候也要手动关闭,所以也偷懒一下
修改stop-yarn.sh
最简单的也是给31行的daemon加个s,当然患有强迫症的我就例外了
这是修改之前的关闭结果,发现最后一行没有代理服务器去关闭,我记得在start-yarn.sh中官方把start proxyserver的启动命令给注释掉了,事实上我也没有用到这个守护进程,所以在stop-yarn.sh中也可以顺便把它给注释掉。
echo "Stopping yarn daemons"
bin=`dirname "${BASH_SOURCE-$0}"`
bin=`cd "$bin"; pwd`
DEFAULT_LIBEXEC_DIR="$bin"/../libexec
HADOOP_LIBEXEC_DIR=${HADOOP_LIBEXEC_DIR:-$DEFAULT_LIBEXEC_DIR}
. $HADOOP_LIBEXEC_DIR/yarn-config.sh
echo "Stopping ResourceManagers on [datanode1 datanode2]"
# stop resourceManager
"$bin"/yarn-daemons.sh --config $YARN_CONF_DIR stop resourcemanager
echo "Stopping NodeManagers on [namenode datanode1 datanode2]"
# stop nodeManager
"$bin"/yarn-daemons.sh --config $YARN_CONF_DIR stop nodemanager
# stop proxy server
#"$bin"/yarn-daemon.sh --config $YARN_CONF_DIR stop proxyserver
关闭展示:


五、结语
所谓脚本,目的就是为了省去复杂又重复的工作,hadoop的“定制”程度很高,还有其他很多的配置等着我去探索,加油。
hadoop平台的搭建过程相对繁琐,要设置很多环境变量,写很多配置文件。如果你是一名新手,在搭建过程中出现了一些问题,可以下方评论告诉我,咱们一起解决。要是实在不想动手,可以花钱,我帮你搭建,高可用完全分布式价格70左右,详谈。
如有错误,欢迎私信纠正!
技术永无止境,谢谢支持!