GluonCV:用Pascal VOC数据训练YOLO v3(上)准备数据+简单训练命令
1.GluonCV简介
Github:https://github.com/dmlc/gluon-cv
GluonCV提供计算机视觉中state-of-the-art(SOTA)深度学习模型的实现。
它专为工程师,研究人员和学生设计,可基于这些模型快速产生原型产品和研究思路。 该工具包提供四个主要功能:
(1)训练脚本用来复现研究论文中报告的SOTA结果
(2)大量预训练模型
(3)精心设计的API可大大降低实施复杂性
(4)社区支持
2.安装环境
训练了一下GluonCV提供的 YOLOv3,记录一下使用过程
首先是安装环境
pip install --upgrade pip
apt-get update
pip install gluoncv --pre --upgrade
pip install mxnet-cu90 --pre --upgrade
apt-get install python-tk3.准备pascal voc数据集
Pascal VOC是用于目标检测的数据集,benchmark最常用的组合是使用2007 trainval和2012 trainval进行训练,使用2007test进行验证。 本节将介绍为GluonCV准备此数据集的步骤。
3.1 下载pascal voc数据集
我们需要来自Pascal VOC的以下四个文件:
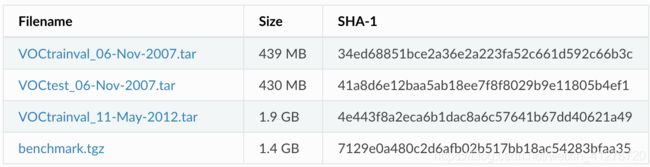
下载和解压缩这些文件的最简单方法是使用数据集自动下载脚本pascal_voc_down.py
"""Prepare PASCAL VOC datasets"""
import os
import shutil
import argparse
import tarfile
from gluoncv.utils import download, makedirs
_TARGET_DIR = os.path.expanduser('~/.mxnet/datasets/voc')
def parse_args():
parser = argparse.ArgumentParser(
description='Initialize PASCAL VOC dataset.',
epilog='Example: python pascal_voc.py --download-dir ~/VOCdevkit',
formatter_class=argparse.ArgumentDefaultsHelpFormatter)
parser.add_argument('--download-dir', type=str, default='~/VOCdevkit/', help='dataset directory on disk')
parser.add_argument('--no-download', action='store_true', help='disable automatic download if set')
parser.add_argument('--overwrite', action='store_true', help='overwrite downloaded files if set, in case they are corrupted')
args = parser.parse_args()
return args
#####################################################################################
# Download and extract VOC datasets into ``path``
def download_voc(path, overwrite=False):
_DOWNLOAD_URLS = [
('http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtrainval_06-Nov-2007.tar',
'34ed68851bce2a36e2a223fa52c661d592c66b3c'),
('http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtest_06-Nov-2007.tar',
'41a8d6e12baa5ab18ee7f8f8029b9e11805b4ef1'),
('http://host.robots.ox.ac.uk/pascal/VOC/voc2012/VOCtrainval_11-May-2012.tar',
'4e443f8a2eca6b1dac8a6c57641b67dd40621a49')]
makedirs(path)
for url, checksum in _DOWNLOAD_URLS:
filename = download(url, path=path, overwrite=overwrite, sha1_hash=checksum)
# extract
with tarfile.open(filename) as tar:
tar.extractall(path=path)
#####################################################################################
# Download and extract the VOC augmented segmentation dataset into ``path``
def download_aug(path, overwrite=False):
_AUG_DOWNLOAD_URLS = [
('http://www.eecs.berkeley.edu/Research/Projects/CS/vision/grouping/semantic_contours/benchmark.tgz', '7129e0a480c2d6afb02b517bb18ac54283bfaa35')]
makedirs(path)
for url, checksum in _AUG_DOWNLOAD_URLS:
filename = download(url, path=path, overwrite=overwrite, sha1_hash=checksum)
# extract
with tarfile.open(filename) as tar:
tar.extractall(path=path)
shutil.move(os.path.join(path, 'benchmark_RELEASE'),
os.path.join(path, 'VOCaug'))
filenames = ['VOCaug/dataset/train.txt', 'VOCaug/dataset/val.txt']
# generate trainval.txt
with open(os.path.join(path, 'VOCaug/dataset/trainval.txt'), 'w') as outfile:
for fname in filenames:
fname = os.path.join(path, fname)
with open(fname) as infile:
for line in infile:
outfile.write(line)
if __name__ == '__main__':
args = parse_args()
path = os.path.expanduser(args.download_dir)
if not os.path.isdir(path) or not os.path.isdir(os.path.join(path, 'VOC2007')) \
or not os.path.isdir(os.path.join(path, 'VOC2012')):
if args.no_download:
raise ValueError(('{} is not a valid directory, make sure it is present.'
' Or you should not disable "--no-download" to grab it'.format(path)))
else:
download_voc(path, overwrite=args.overwrite)
shutil.move(os.path.join(path, 'VOCdevkit', 'VOC2007'), os.path.join(path, 'VOC2007'))
shutil.move(os.path.join(path, 'VOCdevkit', 'VOC2012'), os.path.join(path, 'VOC2012'))
shutil.rmtree(os.path.join(path, 'VOCdevkit'))
if not os.path.isdir(os.path.join(path, 'VOCaug')):
if args.no_download:
raise ValueError(('{} is not a valid directory, make sure it is present.'
' Or you should not disable "--no-download" to grab it'.format(path)))
else:
download_aug(path, overwrite=args.overwrite)
# make symlink
makedirs(os.path.expanduser('~/.mxnet/datasets'))
if os.path.isdir(_TARGET_DIR):
os.remove(_TARGET_DIR)
os.symlink(path, _TARGET_DIR)运行
python pascal_voc_down.py它将自动下载并将数据提取到〜/ .mxnet / datasets / voc中。
3.2 用GluonCV读取分析数据集
此处是官方教程里分析的pascal_voc.py
from gluoncv import data, utils
from matplotlib import pyplot as plt
train_dataset = data.VOCDetection(splits=[(2007, 'trainval'), (2012, 'trainval')])
val_dataset = data.VOCDetection(splits=[(2007, 'test')])
print('Num of training images:', len(train_dataset))
print('Num of validation images:', len(val_dataset))
################################################################
# Now let's visualize one example.
train_image, train_label = train_dataset[5]
print('Image size (height, width, RGB):', train_image.shape)
##################################################################
# Take bounding boxes by slice columns from 0 to 4
bounding_boxes = train_label[:, :4]
print('Num of objects:', bounding_boxes.shape[0])
print('Bounding boxes (num_boxes, x_min, y_min, x_max, y_max):\n',
bounding_boxes)
##################################################################
# take class ids by slice the 5th column
class_ids = train_label[:, 4:5]
print('Class IDs (num_boxes, ):\n', class_ids)
##################################################################
# Visualize image, bounding boxes
utils.viz.plot_bbox(train_image.asnumpy(), bounding_boxes, scores=None,
labels=class_ids, class_names=train_dataset.classes)
plt.show()如果直接在linux命令行运行
python pascal_voc.py因为没有GUI终端,会报错如下,(如果有GUI界面,比如VNC server,不会报错,并且后面可显示边界框图片)
_tkinter.TclError: no display name and no $DISPLAY environment variable
解决方法是
python文件中:
在 from matplotlib import pylot 之前,添加代码:
如下:
import matplotlib as mpl
mpl.use('Agg')
from matplotlib import pylot 下面是对其语句的分析(可以用jupyter notebook)
使用gluoncv.data.VOCDetection可以直接加载图像和标签。
from gluoncv import data, utils
from matplotlib import pyplot as plt
train_dataset = data.VOCDetection(splits=[(2007, 'trainval'), (2012, 'trainval')])
val_dataset = data.VOCDetection(splits=[(2007, 'test')])
print('Num of training images:', len(train_dataset))
print('Num of validation images:', len(val_dataset))
Out:
Num of training images: 16551
Num of validation images: 4952现在让我们看一个例子。
train_image, train_label = train_dataset[200]
print('Image size (height, width, RGB):', train_image.shape)
Out:
Image size (height, width, RGB): (360, 480, 3)通过从0到4的切片列获取边界框
bounding_boxes = train_label[:, :4]
print('Num of objects:', bounding_boxes.shape[0])
print('Bounding boxes (num_boxes, x_min, y_min, x_max, y_max):\n',
bounding_boxes)
Out:
Num of objects: 2
Bounding boxes (num_boxes, x_min, y_min, x_max, y_max):
[[209. 32. 327. 190.]
[ 64. 72. 402. 309.]]通过切片第5列取类ids
class_ids = train_label[:, 4:5]
print('Class IDs (num_boxes, ):\n', class_ids)
Out:
Class IDs (num_boxes, ):
[[14.]
[12.]]可视化图像,边界框 (需要有GUI,即可视化界面,比如在vnc server运行)
utils.viz.plot_bbox(train_image.asnumpy(), bounding_boxes, scores=None,
labels=class_ids, class_names=train_dataset.classes)
plt.show()
官方准备数据集的详细解释
https://gluon-cv.mxnet.io/build/examples_datasets/pascal_voc.html#prepare-the-dataset
4.训练YOLO v3
# train_yolo3.py
"""Train YOLOv3 with random shapes."""
import argparse
import os
import logging
import time
import warnings
import numpy as np
import mxnet as mx
from mxnet import nd
from mxnet import gluon
from mxnet import autograd
import gluoncv as gcv
from gluoncv import data as gdata
from gluoncv import utils as gutils
from gluoncv.model_zoo import get_model
from gluoncv.data.batchify import Tuple, Stack, Pad
from gluoncv.data.transforms.presets.yolo import YOLO3DefaultTrainTransform
from gluoncv.data.transforms.presets.yolo import YOLO3DefaultValTransform
from gluoncv.data.dataloader import RandomTransformDataLoader
from gluoncv.utils.metrics.voc_detection import VOC07MApMetric
from gluoncv.utils.metrics.coco_detection import COCODetectionMetric
from gluoncv.utils import LRScheduler
def parse_args():
parser = argparse.ArgumentParser(description='Train YOLO networks with random input shape.')
parser.add_argument('--network', type=str, default='darknet53',
help="Base network name which serves as feature extraction base.")
parser.add_argument('--data-shape', type=int, default=416,
help="Input data shape for evaluation, use 320, 416, 608... " +
"Training is with random shapes from (320 to 608).")
parser.add_argument('--batch-size', type=int, default=64,
help='Training mini-batch size')
parser.add_argument('--dataset', type=str, default='voc',
help='Training dataset. Now support voc.')
parser.add_argument('--num-workers', '-j', dest='num_workers', type=int,
default=4, help='Number of data workers, you can use larger '
'number to accelerate data loading, if you CPU and GPUs are powerful.')
parser.add_argument('--gpus', type=str, default='0',
help='Training with GPUs, you can specify 1,3 for example.')
parser.add_argument('--epochs', type=int, default=200,
help='Training epochs.')
parser.add_argument('--resume', type=str, default='',
help='Resume from previously saved parameters if not None. '
'For example, you can resume from ./yolo3_xxx_0123.params')
parser.add_argument('--start-epoch', type=int, default=0,
help='Starting epoch for resuming, default is 0 for new training.'
'You can specify it to 100 for example to start from 100 epoch.')
parser.add_argument('--lr', type=float, default=0.001,
help='Learning rate, default is 0.001')
parser.add_argument('--lr-mode', type=str, default='step',
help='learning rate scheduler mode. options are step, poly and cosine.')
parser.add_argument('--lr-decay', type=float, default=0.1,
help='decay rate of learning rate. default is 0.1.')
parser.add_argument('--lr-decay-period', type=int, default=0,
help='interval for periodic learning rate decays. default is 0 to disable.')
parser.add_argument('--lr-decay-epoch', type=str, default='160,180',
help='epochs at which learning rate decays. default is 160,180.')
parser.add_argument('--warmup-lr', type=float, default=0.0,
help='starting warmup learning rate. default is 0.0.')
parser.add_argument('--warmup-epochs', type=int, default=0,
help='number of warmup epochs.')
parser.add_argument('--momentum', type=float, default=0.9,
help='SGD momentum, default is 0.9')
parser.add_argument('--wd', type=float, default=0.0005,
help='Weight decay, default is 5e-4')
parser.add_argument('--log-interval', type=int, default=100,
help='Logging mini-batch interval. Default is 100.')
parser.add_argument('--save-prefix', type=str, default='',
help='Saving parameter prefix')
parser.add_argument('--save-interval', type=int, default=10,
help='Saving parameters epoch interval, best model will always be saved.')
parser.add_argument('--val-interval', type=int, default=1,
help='Epoch interval for validation, increase the number will reduce the '
'training time if validation is slow.')
parser.add_argument('--seed', type=int, default=233,
help='Random seed to be fixed.')
parser.add_argument('--num-samples', type=int, default=-1,
help='Training images. Use -1 to automatically get the number.')
parser.add_argument('--syncbn', action='store_true',
help='Use synchronize BN across devices.')
parser.add_argument('--no-random-shape', action='store_true',
help='Use fixed size(data-shape) throughout the training, which will be faster '
'and require less memory. However, final model will be slightly worse.')
parser.add_argument('--no-wd', action='store_true',
help='whether to remove weight decay on bias, and beta/gamma for batchnorm layers.')
parser.add_argument('--mixup', action='store_true',
help='whether to enable mixup.')
parser.add_argument('--no-mixup-epochs', type=int, default=20,
help='Disable mixup training if enabled in the last N epochs.')
parser.add_argument('--label-smooth', action='store_true', help='Use label smoothing.')
args = parser.parse_args()
return args
def get_dataset(dataset, args):
if dataset.lower() == 'voc':
train_dataset = gdata.VOCDetection(
splits=[(2007, 'trainval'), (2012, 'trainval')])
val_dataset = gdata.VOCDetection(
splits=[(2007, 'test')])
val_metric = VOC07MApMetric(iou_thresh=0.5, class_names=val_dataset.classes)
elif dataset.lower() == 'coco':
train_dataset = gdata.COCODetection(splits='instances_train2017', use_crowd=False)
val_dataset = gdata.COCODetection(splits='instances_val2017', skip_empty=False)
val_metric = COCODetectionMetric(
val_dataset, args.save_prefix + '_eval', cleanup=True,
data_shape=(args.data_shape, args.data_shape))
else:
raise NotImplementedError('Dataset: {} not implemented.'.format(dataset))
if args.num_samples < 0:
args.num_samples = len(train_dataset)
if args.mixup:
from gluoncv.data import MixupDetection
train_dataset = MixupDetection(train_dataset)
return train_dataset, val_dataset, val_metric
def get_dataloader(net, train_dataset, val_dataset, data_shape, batch_size, num_workers, args):
"""Get dataloader."""
width, height = data_shape, data_shape
batchify_fn = Tuple(*([Stack() for _ in range(6)] + [Pad(axis=0, pad_val=-1) for _ in range(1)])) # stack image, all targets generated
if args.no_random_shape:
train_loader = gluon.data.DataLoader(
train_dataset.transform(YOLO3DefaultTrainTransform(width, height, net, mixup=args.mixup)),
batch_size, True, batchify_fn=batchify_fn, last_batch='rollover', num_workers=num_workers)
else:
transform_fns = [YOLO3DefaultTrainTransform(x * 32, x * 32, net, mixup=args.mixup) for x in range(10, 20)]
train_loader = RandomTransformDataLoader(
transform_fns, train_dataset, batch_size=batch_size, interval=10, last_batch='rollover',
shuffle=True, batchify_fn=batchify_fn, num_workers=num_workers)
val_batchify_fn = Tuple(Stack(), Pad(pad_val=-1))
val_loader = gluon.data.DataLoader(
val_dataset.transform(YOLO3DefaultValTransform(width, height)),
batch_size, False, batchify_fn=val_batchify_fn, last_batch='keep', num_workers=num_workers)
return train_loader, val_loader
def save_params(net, best_map, current_map, epoch, save_interval, prefix):
current_map = float(current_map)
if current_map > best_map[0]:
best_map[0] = current_map
net.save_parameters('{:s}_best.params'.format(prefix, epoch, current_map))
with open(prefix+'_best_map.log', 'a') as f:
f.write('{:04d}:\t{:.4f}\n'.format(epoch, current_map))
if save_interval and epoch % save_interval == 0:
net.save_parameters('{:s}_{:04d}_{:.4f}.params'.format(prefix, epoch, current_map))
def validate(net, val_data, ctx, eval_metric):
"""Test on validation dataset."""
eval_metric.reset()
# set nms threshold and topk constraint
net.set_nms(nms_thresh=0.45, nms_topk=400)
mx.nd.waitall()
net.hybridize()
for batch in val_data:
data = gluon.utils.split_and_load(batch[0], ctx_list=ctx, batch_axis=0, even_split=False)
label = gluon.utils.split_and_load(batch[1], ctx_list=ctx, batch_axis=0, even_split=False)
det_bboxes = []
det_ids = []
det_scores = []
gt_bboxes = []
gt_ids = []
gt_difficults = []
for x, y in zip(data, label):
# get prediction results
ids, scores, bboxes = net(x)
det_ids.append(ids)
det_scores.append(scores)
# clip to image size
det_bboxes.append(bboxes.clip(0, batch[0].shape[2]))
# split ground truths
gt_ids.append(y.slice_axis(axis=-1, begin=4, end=5))
gt_bboxes.append(y.slice_axis(axis=-1, begin=0, end=4))
gt_difficults.append(y.slice_axis(axis=-1, begin=5, end=6) if y.shape[-1] > 5 else None)
# update metric
eval_metric.update(det_bboxes, det_ids, det_scores, gt_bboxes, gt_ids, gt_difficults)
return eval_metric.get()
def train(net, train_data, val_data, eval_metric, ctx, args):
"""Training pipeline"""
net.collect_params().reset_ctx(ctx)
if args.no_wd:
for k, v in net.collect_params('.*beta|.*gamma|.*bias').items():
v.wd_mult = 0.0
if args.label_smooth:
net._target_generator._label_smooth = True
if args.lr_decay_period > 0:
lr_decay_epoch = list(range(args.lr_decay_period, args.epochs, args.lr_decay_period))
else:
lr_decay_epoch = [int(i) for i in args.lr_decay_epoch.split(',')]
lr_scheduler = LRScheduler(mode=args.lr_mode,
baselr=args.lr,
niters=args.num_samples // args.batch_size,
nepochs=args.epochs,
step=lr_decay_epoch,
step_factor=args.lr_decay, power=2,
warmup_epochs=args.warmup_epochs)
trainer = gluon.Trainer(
net.collect_params(), 'sgd',
{'wd': args.wd, 'momentum': args.momentum, 'lr_scheduler': lr_scheduler},
kvstore='local')
# targets
sigmoid_ce = gluon.loss.SigmoidBinaryCrossEntropyLoss(from_sigmoid=False)
l1_loss = gluon.loss.L1Loss()
# metrics
obj_metrics = mx.metric.Loss('ObjLoss')
center_metrics = mx.metric.Loss('BoxCenterLoss')
scale_metrics = mx.metric.Loss('BoxScaleLoss')
cls_metrics = mx.metric.Loss('ClassLoss')
# set up logger
logging.basicConfig()
logger = logging.getLogger()
logger.setLevel(logging.INFO)
log_file_path = args.save_prefix + '_train.log'
log_dir = os.path.dirname(log_file_path)
if log_dir and not os.path.exists(log_dir):
os.makedirs(log_dir)
fh = logging.FileHandler(log_file_path)
logger.addHandler(fh)
logger.info(args)
logger.info('Start training from [Epoch {}]'.format(args.start_epoch))
best_map = [0]
for epoch in range(args.start_epoch, args.epochs):
if args.mixup:
# TODO(zhreshold): more elegant way to control mixup during runtime
try:
train_data._dataset.set_mixup(np.random.beta, 1.5, 1.5)
except AttributeError:
train_data._dataset._data.set_mixup(np.random.beta, 1.5, 1.5)
if epoch >= args.epochs - args.no_mixup_epochs:
try:
train_data._dataset.set_mixup(None)
except AttributeError:
train_data._dataset._data.set_mixup(None)
tic = time.time()
btic = time.time()
mx.nd.waitall()
net.hybridize()
for i, batch in enumerate(train_data):
batch_size = batch[0].shape[0]
data = gluon.utils.split_and_load(batch[0], ctx_list=ctx, batch_axis=0)
# objectness, center_targets, scale_targets, weights, class_targets
fixed_targets = [gluon.utils.split_and_load(batch[it], ctx_list=ctx, batch_axis=0) for it in range(1, 6)]
gt_boxes = gluon.utils.split_and_load(batch[6], ctx_list=ctx, batch_axis=0)
sum_losses = []
obj_losses = []
center_losses = []
scale_losses = []
cls_losses = []
with autograd.record():
for ix, x in enumerate(data):
obj_loss, center_loss, scale_loss, cls_loss = net(x, gt_boxes[ix], *[ft[ix] for ft in fixed_targets])
sum_losses.append(obj_loss + center_loss + scale_loss + cls_loss)
obj_losses.append(obj_loss)
center_losses.append(center_loss)
scale_losses.append(scale_loss)
cls_losses.append(cls_loss)
autograd.backward(sum_losses)
lr_scheduler.update(i, epoch)
trainer.step(batch_size)
obj_metrics.update(0, obj_losses)
center_metrics.update(0, center_losses)
scale_metrics.update(0, scale_losses)
cls_metrics.update(0, cls_losses)
if args.log_interval and not (i + 1) % args.log_interval:
name1, loss1 = obj_metrics.get()
name2, loss2 = center_metrics.get()
name3, loss3 = scale_metrics.get()
name4, loss4 = cls_metrics.get()
logger.info('[Epoch {}][Batch {}], LR: {:.2E}, Speed: {:.3f} samples/sec, {}={:.3f}, {}={:.3f}, {}={:.3f}, {}={:.3f}'.format(
epoch, i, trainer.learning_rate, batch_size/(time.time()-btic), name1, loss1, name2, loss2, name3, loss3, name4, loss4))
btic = time.time()
name1, loss1 = obj_metrics.get()
name2, loss2 = center_metrics.get()
name3, loss3 = scale_metrics.get()
name4, loss4 = cls_metrics.get()
logger.info('[Epoch {}] Training cost: {:.3f}, {}={:.3f}, {}={:.3f}, {}={:.3f}, {}={:.3f}'.format(
epoch, (time.time()-tic), name1, loss1, name2, loss2, name3, loss3, name4, loss4))
if not (epoch + 1) % args.val_interval:
# consider reduce the frequency of validation to save time
map_name, mean_ap = validate(net, val_data, ctx, eval_metric)
val_msg = '\n'.join(['{}={}'.format(k, v) for k, v in zip(map_name, mean_ap)])
logger.info('[Epoch {}] Validation: \n{}'.format(epoch, val_msg))
current_map = float(mean_ap[-1])
else:
current_map = 0.
save_params(net, best_map, current_map, epoch, args.save_interval, args.save_prefix)
if __name__ == '__main__':
args = parse_args()
# fix seed for mxnet, numpy and python builtin random generator.
gutils.random.seed(args.seed)
# training contexts
ctx = [mx.gpu(int(i)) for i in args.gpus.split(',') if i.strip()]
ctx = ctx if ctx else [mx.cpu()]
# network
net_name = '_'.join(('yolo3', args.network, args.dataset))
args.save_prefix += net_name
# use sync bn if specified
if args.syncbn and len(ctx) > 1:
net = get_model(net_name, pretrained_base=True, norm_layer=gluon.contrib.nn.SyncBatchNorm,
norm_kwargs={'num_devices': len(ctx)})
async_net = get_model(net_name, pretrained_base=False) # used by cpu worker
else:
net = get_model(net_name, pretrained_base=True)
async_net = net
if args.resume.strip():
net.load_parameters(args.resume.strip())
async_net.load_parameters(args.resume.strip())
else:
with warnings.catch_warnings(record=True) as w:
warnings.simplefilter("always")
net.initialize()
async_net.initialize()
# training data
train_dataset, val_dataset, eval_metric = get_dataset(args.dataset, args)
train_data, val_data = get_dataloader(
async_net, train_dataset, val_dataset, args.data_shape, args.batch_size, args.num_workers, args)
# training
train(net, train_data, val_data, eval_metric, ctx, args)(1)在GPU:0上用Pascal VOC数据训练默认的darknet53模型
python train_yolo3.py --gpus 0
(2)在GPU:0,1,2,3上用Pascal VOC数据训练darknet53模型,并使用了synchronize BatchNorm。
python train_yolo3.py --gpus 0,1,2,3 --network darknet53 --syncbn
详细训练分析接下篇
GluonCV:用Pascal VOC数据训练YOLO v3(下)训练部分
参考资料
- 准备pascal VOC数据集
- 训练yolo v3
-
Linux终端没有GUI,如何使用matplotlib绘图