周常
五道算法题 java 实现
1.二维数组搜索
2.二分查找最小值
3.从尾到头打印链表
4.用栈表示队列
5.重建二叉树koa-bodyparser 源码解析
async / await 原理解析
算法题
二维数组中查找
输入:
matrix = [
[1, 3, 5, 7],
[10, 11, 16, 20],
[23, 30, 34, 50]
]
target = 3
输出: true
---
输入:
matrix = [
[1, 3, 5, 7],
[10, 11, 16, 20],
[23, 30, 34, 50]
]
target = 13
输出: false
解题思路
- 此二维数组是按顺序排列
- 每一行数组的最后一位都是此行数组的最大值
- target 如果比当前数组最后一位大,那 target 肯定在下面的几行数组内
- target 如果比当前数组最后一位小,那 target 可能在当前数组内
-
用 target 与二维数组内的每个数组最后一位比较,在最后一位比 target 大的那一行数组内进行 target 查找

代码实现
public class SearchMatrix {
public boolean searchMatrix(int[][] matrix, int target) {
if (matrix.length == 0)
return false;
int i = 0; // 第一行
int j = matrix[0].length - 1; // 最后一个点
while (i < matrix.length && j >= 0) {
if (matrix[i][j] == target) // 第一排最后一个
return true;
else if (matrix[i][j] < target) // 如果小,就移动到下一排最后一个
i++;
else // matrix[i][j] > target // 如果大,i 就是当前排,在当前排搜索
j--;
}
return false;
}
}
搜索二维矩阵
寻找旋转排序数组中的最小值
假设按照升序排序的数组在预先未知的某个点上进行了旋转。
( 例如,数组 [0,1,2,4,5,6,7] 可能变为 [4,5,6,7,0,1,2] )。
请找出其中最小的元素。
你可以假设数组中不存在重复元素。
解题思路
- 查找某个值比较合适的解法是二分搜索
- 此题数组已经是排序数组,变化后有以下几个结果,
[1,2,3,4,5] // 顺序不变,直接取数组 arr[0]
// 中值 arr[mid] 是数组最大值或最小值
[3,4,5,1,2] // arr[mid] 是 5 arr[mid] > arr[mid+1] 最小值是 arr[mid+1]
[4,5,1,2,3] // arr[mid] 是 1 arr[mid-1] > arr[mid] 最小值是 arr[mid]
// 中值 arr[mid] 是数组最大值或最小值以外的值
[2,3,4,5,1] // arr[mid] 是 4 最小值在数组右侧,left = mid + 1 继续查找
[5,1,2,3,4] // arr[mid] 是 2 最小值在数组左侧,right = mid - 1 继续查找
代码实现
public class BinarySearch {
/**
* 找到最小数
* nums [3,4,5,1,2], 一定是按顺序排列的数组,只是进行了旋转
* 旋转后=[3,4,5,1,2], 原数组=[1,2,3,4,5]
*/
public int findMin(int[] nums) {
// 一个数
if (nums.length == 1)
return nums[0];
int left = 0, right = nums.length - 1;
// [1,2,3,4,5] 为没旋转的原数组
if (nums[right] > nums[0])
return nums[0];
// 进行二分搜索
while (right >= left) {
// 找到中点防止溢出
int mid = left + ((right - left) >> 1);
// [3,4,5,1,2] midVal = 5
if (nums[mid] > nums[mid + 1])
return nums[mid + 1];
// [4,5,1,2,3] midVal = 1
if (nums[mid - 1] > nums[mid])
return nums[mid];
// [2,3,4,5,1]
if (nums[mid] > nums[0])
left = mid + 1;
// [5,1,2,3,4]
else // nums[mid] < nums[0]
right = mid - 1;
}
return -1;
}
}
寻找旋转排序数组中的最小值
使用栈实现队列
解题思路
- 队列有 push 添加元素, pop 删除并返回队列头元素,peek 查看队列头的元素, empty 是否为空
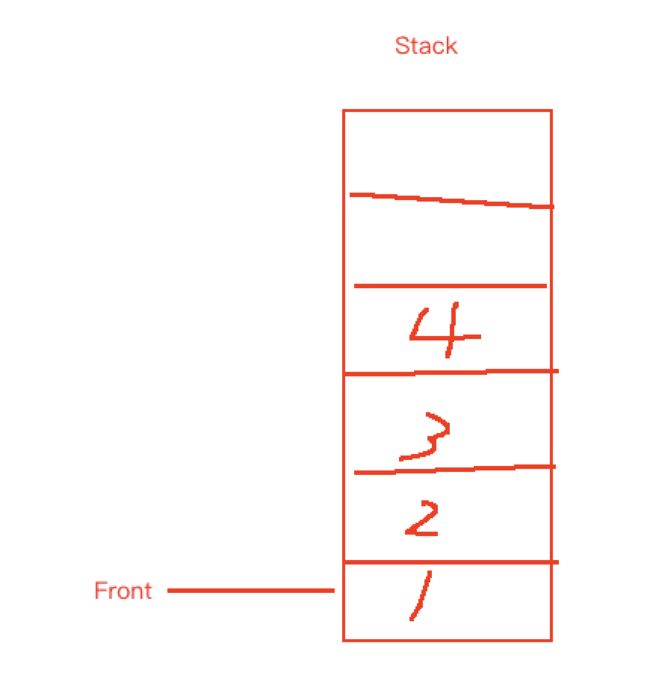
- 实现 Queue 的 push 可以直接使用 Stack 的 push,而队列的头部元素可以用 Front 变量来保存。
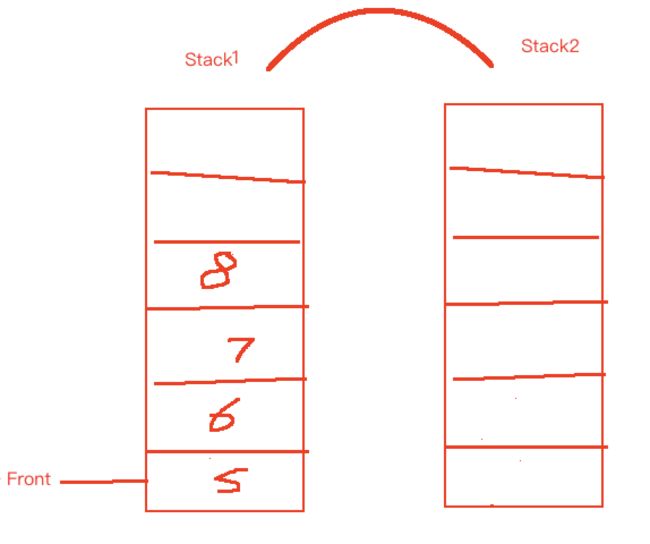
- 实现 Queue 的 pop 需要删除掉 队列的头元素并返回,而 Stack 的 pop 只能返回最后进入的元素,这时候需要 Stack2 协助完成
- Stack1 的元素 pop() 出来 push() 到 Stack2 中,这时 Stack2.pop() 出的就是 队列的头部元素

- 实现队列 peek 方法要考虑两种情况
- Stack2 是空的,此时 Queue 队列还没进行 pop() 操作或者 Stack2 已经排空,只有 Stack1 有元素, 此时 front 变量就是 peek() 出的元素
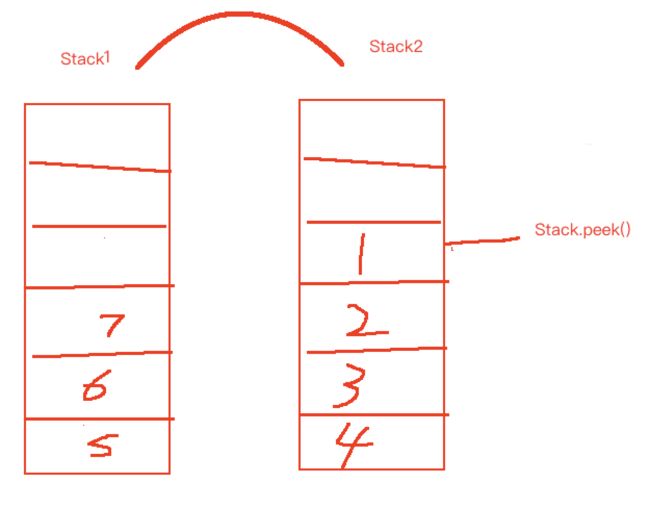
- Stack2 有元素,此时 Queue 队列已经进行 pop() 操作,Stack2 的栈顶就是队列头,只需要进行 Stack2.peek() 就行了。
- Stack2 是空的,此时 Queue 队列还没进行 pop() 操作或者 Stack2 已经排空,只有 Stack1 有元素, 此时 front 变量就是 peek() 出的元素
代码实现
public class ImplementQueueUsingStacks {
private int front;
private Stack s1 = new Stack<>();
private Stack s2 = new Stack<>();
/** Initialize your data structure here. */
public MyQueue() {}
/** Push element x to the back of queue. */
public void push(int x) {
if (s1.isEmpty())
front = x;
s1.push(x);
}
/** Removes the element from in front of queue and returns that element. */
public int pop() {
while (s2.isEmpty()) {
if (!s1.isEmpty())
s2.push(s1.pop());
}
return s2.pop();
}
/** Get the front element. */
public int peek() {
if (!s2.isEmpty())
return s2.peek();
return front;
}
/** Returns whether the queue is empty. */
public boolean empty() {
return s1.isEmpty() && s2.isEmpty();
}
}
使用栈实现队列
从尾到头打印链表的值
// 链表节点结构
private class ListNode {
int val;
ListNode next;
}
实现思路
- 使用 Stack 保存所有链表的值
- 再使用 List 保存 Stack.pop() 出来的值

代码实现
public class PrintListFromTailToHead {
public List printListFromTailToHead(ListNode listNode) {
Stack stack = new Stack<>();
while (listNode != null) {
stack.push(listNode.val);
listNode = listNode.next;
}
ArrayList arrayList = new ArrayList<>();
while (!stack.isEmpty()) {
arrayList.add(stack.pop());
}
return arrayList;
}
}
根据中序排列、前序排列重建二叉树
实现思路
- 前序遍历顺序为 [ 根 左 右 ]
// 前序遍历的序号顺序
0
/ \
1 9
/ \ / \
2 6 10 13
/ \ / \ / \ / \
3 5 7 8 11 12 14 15
/
4
- 中序遍历顺序为 [ 左 根 右 ]
// 中序遍历的序号顺序
8
/ \
4 12
/ \ / \
2 6 10 14
/ \ / \ / \ / \
1 3 5 7 9 11 13 15
/
0
- 使用一个函数递归重建二叉树
- 函数中先确定重建的当前节点树的根节点,前序遍历的第一位 preStart 就是当前树结构的根节点 root = preorder[preStart]
- 确定 root.left 的位置,root.left 为 root 节点的 在前序遍历的位置 preStart + 1 的位置
- 确定 root.right 的位置, root.right 为 root 节点在前序遍历中 preStart + (所有左子树元素个数) + 1 的位置。
- 确定 root.right 的位置需要知道 root 所有左子树元素个数,这时只依靠前序遍历的结果是无法得到的,而中序遍历的结果顺序为 [ 左 根 右 ], 我们已经根据前序遍历 preorder[preStart] 确定了 根 root 的值,找到 root 在中序遍历结果中的位置后,此位置在中序遍历中的所有左侧元素就是我们要的结果。
- 查找当前 root 节点在 inorder 中的位置,已知 root,需要提供此段节点 inStart, inEnd 的位置。这时我们的函数 可写为
public TreeNode helper(int preStart, int inStart, int inEnd, int[] preorder, int[] inorder) {} - 找到 root 在 inorder 中的位置 inIndex,inIndex - inStart 为 root 节点所有左子树元素个数, root.right 的 preStart 就为 preStart + inIndex - inStart + 1
- 在递归函数参数中,通过 inIndex 再来确定 root.left、root.right 的 inStart 和 inEnd
代码实现
public class ReConstructBinaryTreeBak2 {
// Definition for a binary tree node.
public class TreeNode {
int val;
TreeNode left;
TreeNode right;
TreeNode(int x) { val = x; }
}
public TreeNode buildTree(int [] preorder, int [] inorder) {
return helper(0, 0, inorder.length - 1, preorder, inorder);
}
public TreeNode helper(int preStart, int inStart, int inEnd, int[] preorder, int[] inorder) {
if (preStart > preorder.length - 1 || inStart > inEnd)
return null;
TreeNode root = new TreeNode(preorder[preStart]);
int inIndex = 0;
for (int i = inStart; i <= inEnd; i++) {
if (root.val == inorder[i])
inIndex = i;
}
root.left = helper(preStart + 1, inStart, inIndex - 1, preorder, inorder);
root.right = helper(preStart + (inIndex - inStart + 1), inIndex + 1, inEnd, preorder, inorder);
return root;
}
}
koa-bodyparser 源码解析
作用
将 http POST 请求的数据解析成对象挂载到 ctx.request.body 对象上进行使用。
koa-bodyparser 中间件默认支持表单格式 application/x-www-form-urlencoded 和 JSON 格式 application/json
源码
bodyParser 中间件把请求的使用 parseBody(ctx) 解析成对象进行挂载
return async function bodyParser(ctx, next) {
if (ctx.request.body !== undefined) return await next();
if (ctx.disableBodyParser) return await next();
try {
const res = await parseBody(ctx); // 解析 ctx 数据,默认 from json 两种格式
ctx.request.body = 'parsed' in res ? res.parsed : {}; // 解析成功把结果挂载到 ctx.request.body 上
if (ctx.request.rawBody === undefined) ctx.request.rawBody = res.raw;
} catch (err) {
if (onerror) {
onerror(err, ctx);
} else {
throw err;
}
}
await next();
};
parseBody 函数使用 co-body 模块进行解析。
var parse = require('co-body');
// ...
async function parseBody(ctx) {
if (enableJson && ((detectJSON && detectJSON(ctx)) || ctx.request.is(jsonTypes))) {
return await parse.json(ctx, jsonOpts); // 解析 json 类型
}
if (enableForm && ctx.request.is(formTypes)) {
return await parse.form(ctx, formOpts); // 解析表单类型
}
if (enableText && ctx.request.is(textTypes)) {
return await parse.text(ctx, textOpts) || ''; // 解析文本类型
}
return {};
}
};
co-body 模块解析 json, 把请求解析成字符串后进行 JSON.parse(str) 然后返回
const raw = require('raw-body');
const inflate = require('inflation');
module.exports = async function(req, opts) {
req = req.req || req;
opts = utils.clone(opts);
// ...
const str = await raw(inflate(req), opts);
try {
const parsed = parse(str); // JSON.parse
return opts.returnRawBody ? { parsed, raw: str } : parsed;
} catch (err) {
err.status = 400;
err.body = str;
throw err;
}
co-body 模块解析 from, 把表单请求解析成字符串后使用 qs.parse 解析后返回
const raw = require('raw-body');
const inflate = require('inflation');
module.exports = async function(req, opts) {
req = req.req || req;
opts = utils.clone(opts);
const queryString = opts.queryString || {};
// ...
const str = await raw(inflate(req), opts);
try {
const parsed = opts.qs.parse(str, queryString); // 使用 qs.parse 解析
return opts.returnRawBody ? { parsed, raw: str } : parsed;
} catch (err) {
err.status = 400;
err.body = str;
throw err;
}
};
nodejs 的 http 模块接收的 post 请求为可读流内容,co-body 通过使用 raw-body 来解析成 str 供 co-body 来生成返回对象。
var inflate = require('inflation')
var raw = require('raw-body')
const str = await raw(inflate(req), opts);
这里使用了 inflate 库,库里返回 http 可读流的解压后 Stream, stream.pip(zip.Unzip(opts)) ,作为参数传给 raw-body 来解析
var zlib = require('zlib')
function inflate(stream, options) {
// ...
switch (encoding) {
case 'gzip':
case 'deflate':
break
case 'identity':
return stream
default:
var err = new Error('Unsupported Content-Encoding: ' + encoding)
err.status = 415
throw err
}
// no not pass-through encoding
delete options.encoding
return stream.pipe(zlib.Unzip(options))
}
raw-body 模块通过 readStream 方法返回解析出来的 buf 字符串数据
function getRawBody (stream, options, callback) {
// ...
return new Promise(function executor (resolve, reject) {
readStream(stream, encoding, length, limit, function onRead (err, buf) {
if (err) return reject(err)
resolve(buf)
})
})
}
readStream 方法注册 http stream 的事件进行处理,onData 来处理 POST 请求的 Stream 数据, onEnd 用 done 函数处理事件结束。
function readStream (stream, encoding, length, limit, callback) {
// ...
var buffer = decoder
? ''
: []
stream.on('aborted', onAborted)
stream.on('close', cleanup)
stream.on('data', onData)
stream.on('end', onEnd)
stream.on('error', onEnd)
// ...
function onData (chunk) {
if (complete) return
received += chunk.length
if (limit !== null && received > limit) {
done(createError(413, 'request entity too large', {
limit: limit,
received: received,
type: 'entity.too.large'
}))
} else if (decoder) {
buffer += decoder.write(chunk)
} else {
buffer.push(chunk)
}
}
function onEnd (err) {
if (complete) return
if (err) return done(err)
if (length !== null && received !== length) {
done(createError(400, 'request size did not match content length', {
expected: length,
length: length,
received: received,
type: 'request.size.invalid'
}))
} else {
var string = decoder
? buffer + (decoder.end() || '')
: Buffer.concat(buffer)
done(null, string)
}
}
}
body-parser 总结
koa-bodyparser 通过使用 raw-body 模块解析 http 请求的 stream buffer 数据成字符串格式,再根据请求头中的 MIME 来解析字符串成对应的对象,最后挂载到 ctx.request.body 对象上。
async / await 方法解析
async function async1() {
console.log('async1 start');
await async2();
console.log('async1 end');
}
async function async2() {
console.log('async2');
}
async 函数通过 babel 后为一个自执行函数,返回另一个函数, 而原 async 函数里所要执行的内容将由 function*() { // 执行内容 } 包裹传入 _asyncToGenerator 里
let async1 = (() => {
var _ref = _asyncToGenerator(function*() {
console.log("async1 start");
yield async2();
console.log("async1 end");
});
return function async1() {
return _ref.apply(this, arguments);
};
})();
let async2 = (() => {
var _ref2 = _asyncToGenerator(function*() {
console.log("async2");
});
return function async2() {
return _ref2.apply(this, arguments);
};
})();
解析 _asyncToGenerator
- _asyncToGenerator 的执行
1.会先执行传入的 generator 函数
2.然后返回一个 new Promise()
3.在 new Promise 里执行 step("next") 来检查当前函数是否 有 yield 可执行
4.有 yield 可执行就通过 Promise.resolve(value).then(// 继续执行 step('"next", value))
5.一直到当前 generator 函数执行完毕,next() 返回 done 为 true 时才最终返回 resolve(value) 并把执行的结果带出,也就是 await 出来的值。
function _asyncToGenerator(fn) {
return function() {
var gen = fn.apply(this, arguments); // 先执行传入 generator 函数
return new Promise(function(resolve, reject) {
function step(key, arg) {
try {
var info = gen[key](arg);
var value = info.value;
} catch (error) {
reject(error);
return;
}
if (info.done) {
resolve(value);
} else {
return Promise.resolve(value).then(
function(value) {
step("next", value);
},
function(err) {
step("throw", err);
}
);
}
}
return step("next");
});
};
}
async / await 总结
当 async 函数执行时,经过内部自执行函数的将会把需要执行的内容直接传入 _asyncToGenerator 中执行,同时直接返回的 new Promise(// .. step("next")), 而返回的 new Promise 回调中 step("next") 函数会一直执行直到 resolve(value) 带出 await 后的执行结果